首页 > 心得体会 > 党团知识 / 正文
从大数据到大知识
2023-02-06 16:30:12 ℃陆汝钤
(中国科学院{数学与系统科学研究院,MADIS重点实验室},未来人工智能重点实验室,北京 100190)
在大数据概念被正式提出之前,其实有关的思想已经显现。1991年, 后来的美国副总统戈尔提出了信息高速公路和国家信息基础设施建设[1],而我国中科院计算所的曹存根在1995年中国科协的一次青年科学家座谈会上也提出了知识高速公路和国家知识基础设施建设[2]。他的建议在2000年由中科院正式立项百人计划[3],2002年发表了第一篇论文[4]。不难看出,他们的主张已经分别体现了大数据和大知识的基本思想。1997年有人在第八届IEEE会议的可视化大会上发表的演说中正式提到大数据[5],这是作者能查到的最早关于大数据的公开演说。大数据的第一个3V模型(Volume, Velocity, Variety)实际上早在2001年就由Gartner提出了,尽管当时没有用‘大数据’这个词[6-7]。接下来,大数据模型研究迅速升温。4V,5V,6V等扩充模型也陆续出现,到了2015年,就已经有人提出10V模型了[8]。与此同时,据我们搜索,较早提到大知识的代表性文献首推文献[9],包括该文在内的有关大知识的许多讨论,几乎都是集中在一个问题上,就是如何从大数据获取大知识。在这个背景下,国际形势促进了国内学界的关注和跟进,大数据知识工程概念应运而生。
这方面的相关研究工作主要是通过三篇文章[10-12]和一个重大课题启动的。其中文献[10]提出了不同于所有nV模型的HACE模型,从数据挖掘的角度给出了观察大数据的一个新视角。在这里H(Heterogeneous)代表异构性,指大数据的信息结构有极大的差异;
A(Autonomous)代表自治性,指大数据的分散、自发和无序生长;
C(Complex)代表复杂性,指大数据内部语义关系错综复杂;
E(Evolving)代表演化性,指这种错综复杂的语义关系随时间不断变化。文献[11]首次提出大数据知识工程的概念,指出这是一个从大数据中提炼和应用知识的过程。文献[12]则明确提出大数据知识工程是从大数据获取大知识的过程。而相应的重大课题则是国家“十三五”重点研发计划项目‘大数据知识工程基础理论及其应用研究’[13]。
作者个人认为大数据知识工程的提出实际上是从大数据到大知识的一个转折点。从大数据成为热门话题,到大知识概念浮出水面,学界和产业界的种种议论使我们产生了兴趣,到底什么是大知识?令人想起苏东坡老先生的一首诗,“横看成岭侧成峰,远近高低各不同。不识庐山真面目,只缘身在此山中”。实际上我们每天都生活在大知识之中,却很难说出它到底是什么样的。本文打算从几个不同的视角考察一下大知识相关研究的现状和它的发展方向。
2016年,作者在一个报告[14]中第一次发表了自己的个人观点。初步提出了大知识的6个海量特征(MC),它们依次是海量概念、海量概念之间的海量联系、海量清洁数据资源(支持和生成大知识的规范大数据,一可继续利用并深挖知识,二可用于出现问题时从大数据去追溯,三可在系统崩溃时用来恢复大知识)、海量技术工具和解决问题能力、海量应用实例(包括成功的和可能是失败的),以及海量的知识协调、更新和与时俱进。接着,在2018年正式发表的有关大知识的系统研究成果[15]中作者阐述了五个大知识(BK)特征,五个大系统特征,两者形成了大知识系统(BKS)的十个特征。另外还定义了大知识工程(BKE)的六大特点以及大知识工程生命周期的八个阶段,我们还考察了六个典型的大数据知识工程,对它们的BK、BKS和BKE特征做了分析对比。
其中BK五个特征在2016年阐述的基础上加入了定量的标准,这些定量标准不是凭空想象的,都是从一些实例中抽取的。BKS的十个特征是:
● Massive Concepts(MC1):以海量概念为基础,概念数10万以上
● Massive Connectedness (MC2):知识元之间的海量联络:联络数100万以上
● Massive Clean Data resource (MC3):海量清洁数据源:约为知识含量的1/100到1/10
● Massive Cases (MC4):海量的实例:平均100个实例/概念
● Massive Confidence (MC5):海量的可信度:自动(人工)获取的知识之可信度下界是60%(90%)
我们还进一步研究了BKS的五个附加特征:
● Massive Capabilities (MC6):全生命周期的海量(知识处理)能力,包括构建、管理、操作BK和提供服务的能力
● Massive Cumulativeness (MC7):海量的知识积累、演化和更新
● Massive Concerns (MC8):海量的广阔视角
● Massive Compatibility (MC9):海量兼容性
● Massive Cleverness (MC10):海量的聪明,能够在需要时涌现智能并解决复杂问题
BKE有六个要点,它们包括大目标、大数据、大知识、大技术、大服务、大生命周期。
● 大目标: BKE的根本目标是构建满足10个MC的BKS。从工程一开始就要确定BKS的科学或应用目标,特别是BKS的关键设计和它的未来长期演化方向。
● 大数据:BKE必须基于BD,形式可以多样。所建BKS能使用现代的先进数据分析工具和技术来处理、挖掘和管理它们。
● 大知识:BKS的核心是BK,必须高质量地满足5个MC标准。
● 大技术:开发和使用一切可用的技术(不限于信息处理技术)和工具来支持知识的挖掘、验证、使用和管理。
● 大服务:向用户提供强大的技术和工具来满足本大知识系统未来用户的各种不同和多变的需求。
● 大生命周期:一般来说,知识的获取和更新永无止境。大知识系统的管理和服务功能的改进和更新也永无止境。因此,只要大知识系统还在提供服务,大知识工程就还在路上,并且其生命周期的各个环节就还在循环不息。
下面介绍我们考察的六个大型知识工程:
第一个是上海第五次综合交通调查[16],这种调查每五年举行一次,通过所有可能的调查手段,获取海量数据并加以分析,然后在此基础上制定下个五年的交通设施建设计划。第二个是夏商西周编年史研究,中国的古代史主要根据司马迁的史记,而史记的记载是从西周的中期开始的,为此有些史学家质疑中国是否有5000年的文明史,甚至怀疑夏朝的存在。1996—2000年国家科委组织了近百位专家进行研究,结果给出了各朝和各代帝王的存在年份[17]。第三个是国际人类基因组计划[18],这个计划中国也参加了,虽然仅仅承担了1%的工作量,但是意义重大。第四个是特洛伊城战争考古[19],这是一个国际的地下挖掘和考古工程,据说一直挖到了地下9层,其中地下第7层被专家们认为是特洛伊城遗址。第五个是开发了维基家族这个庞大的知识宝库[20]。第六个是海量知识图谱的研发[15]。
考察结果显示在这六个大型知识工程中,只有三个才能够得上大知识工程的基本要素。它们是国际人类基因组计划,维基家族建设和大规模知识图谱开发。
我们从万维网,维基百科和大知识图谱三个角度来看。首先说一下万维网,它的网站数在1995年8月才13000多,到了2021年9月已经达到了11.9亿[21]。再看维基百科,它的英文页面数从2001年的22000多迅速扩张到2021年9月的4000多万[20]。至于大知识图谱,我们分析了10个国内外大型知识图谱的14个不同版本,其中有4个以概念为知识元的版本(Probase,YAGO1,Opencyc3, Opencyc4)达到了10万概念和千万事实的规模,另有4个以实体为知识元的版本(Freebase, Google Knowledge Graph, Knowledge Vault, OpenKN)达到了千万实体和十亿事实的规模[15]。它们分别达到了大知识图谱的标准。从以上三个例子,我们也可以计算出支配大知识规模增长的类似摩尔定律,它们大体上是每十几个月到二十个月翻一番。
大知识建模是一个崭新的研究课题。文献中最早的此类重要模型可能就是大数据知识工程[11-12],后来被进一步扩展成大数据-大信息-大知识-大数据的流水线模型[22-23]。这类模型起着承上启下的作用。第二类是大知识网络建模,例如物联网[24]、链接开放数据[25]等都是,这类模型的重要性不容轻估,但我们在此地不讨论了。第三类是云知识建模,是我们重点讨论的对象。我们的思路大致是把云建模分为内建模和外建模,前者的核心是知识,后者的核心是智能。云计算的标准模型是基础设施即服务、平台即服务和软件即服务这三个层次[26],但这个模型对我们远远不够,至少在平台即服务和软件即服务之间应该加一层知识即服务。对于一个大知识系统,知识的基础作用万万不可忽视,软件运行也要依靠知识。其次,我们还要在软件服务上面加一层:智能即服务。知识是静态的,只有在特定环境中,根据复杂问题恰当运用知识,从而涌现智能以解决问题,这才是我们需要的。我们搜索的文献中未见有人提到智能即服务,似乎一直被忽略了。关于知识即服务,有人提过,但和云建模无关[27-28],或与我们不同,把知识层置于软件层之上[29]。再进一步,我们认为知识即服务应该是众知即服务,智能即服务应该是众智即服务。其中众知是指有许多独立的知识源,它们的知识不仅可以互补,而且可能完全不同甚至于相反。至于众智,是指不同知识点涌现的智能可能会协商和合作,也可能会互相争辩甚至于对抗。图1是一个由多个知识图谱构成的众知模型,其中企业管理所需要的知识分布在不同的知识图谱中,我们称它们构成网群。图2是医院的众知模型,这是一个人和机器混合的众知模型,在这个模型中,多个人类专家和多个机器专家在同一个网络中协商或辩论,其中机器专家和人类专家的作用没有区别。
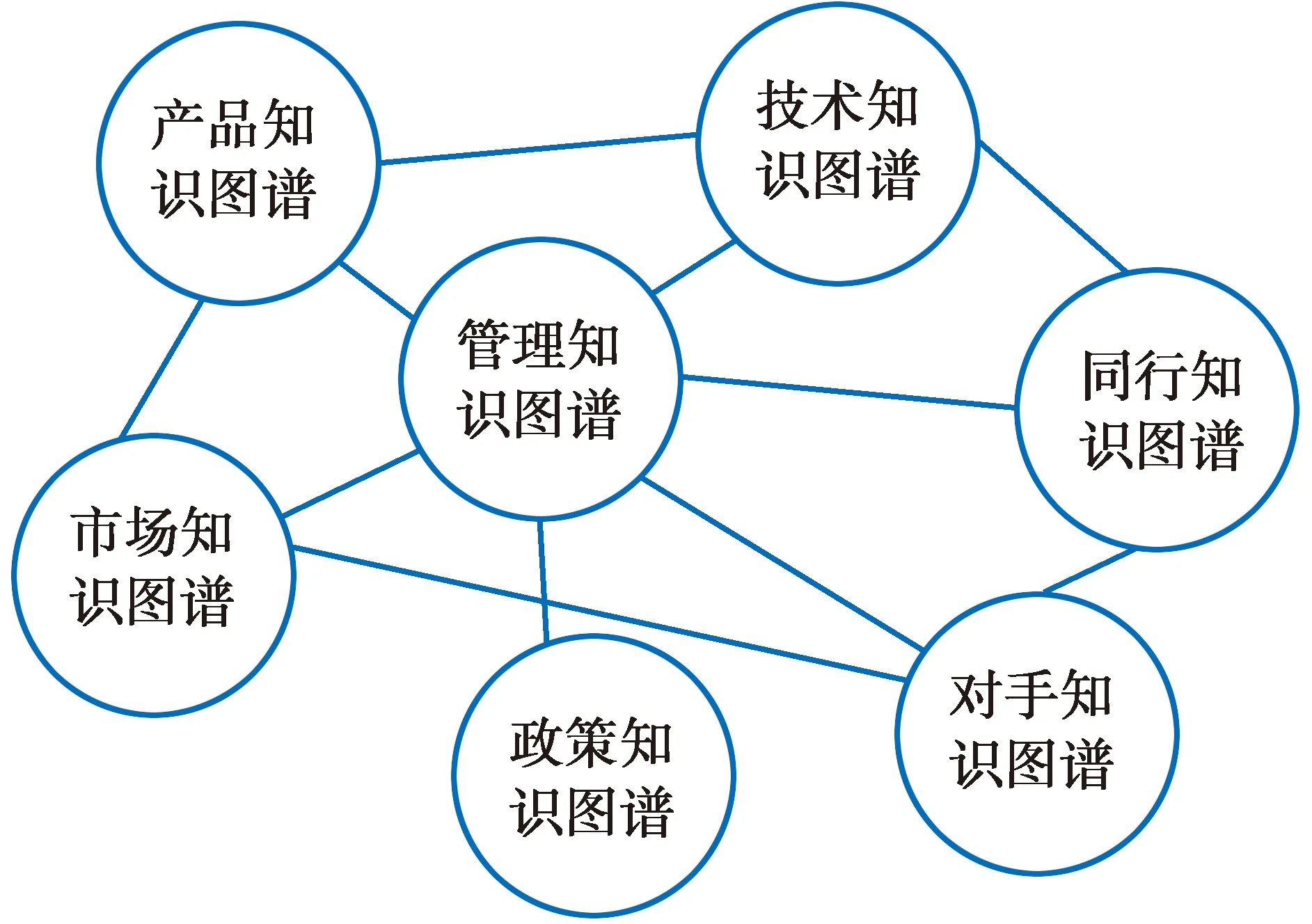
图1 多个知识图谱构成的众知模型(企业)Fig.1 Crowd knowledge model composed of multiple knowledge graphs (enterprise)

图2 多个知识图谱构成的众知模型(医院)Fig.2 Crowd knowledge model composed of multiple knowledge graphs (hospital)
图3例举了13个众智模型的核心功能,它们之间都有知识、思想和智能的交流。有一个非常现实且非常有实用价值的众智模型是无人和有人驾驶的混合机群对抗,国际上已经接近实战,它的理论基础就是去中心化的人机瞬时混合决策模型。
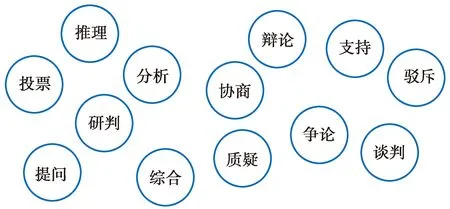
图3 不同的众智模型Fig.3 Different crowd intelligence models
大知识计算的主要功能是通过计算获取新的大知识。嵌入计算是目前最常用的一种大知识计算。考虑到符号处理功能的效率低下,把符号转换成数值再计算成了许多场合下大知识计算的首选。知识图谱操作常用的计算模型——嵌入计算就是这样的,它可以把各种形式表示的数据嵌入到同一个或不同的线性向量空间进行计算,得到结果后,再恢复成原来形式或其他形式。嵌入计算发展迅速,产生了很多的模型[30],也有很多的应用,其中之一是海量文本集成。
根据国际数据协会(IDC)2012年的估计,到2020年无结构大数据数量占比将达到全部大数据量的95%,且年增长率达到65%[31],其中文本大数据是最重要的无结构大数据,占到了无结构大数据研究文献数的49%[32],因此,海量文本的知识集成是一个重要的课题。为此我们开展了基于领域知识和修辞结构的自然语言文本摘要自动生成研究。修辞结构[33]是上世纪末学者们提出的一项理论 ,它把每篇文章分割为一株二叉树,称为修辞结构树[34],见图4。这株树的每对二叉节点中一个称为核心(句),另一个称为卫星(句),核心是主题,卫星是对主题的修饰。我们发现修辞结构树很类似于语法分析树,为此我们把修辞结构理论和属性文法理论结合起来形成属性修词结构文法理论(ARSG文法),在此基础上实现了有监督、无监督[35]和半监督[36]多文本摘要自动生成。其中半监督方法的实验是从SogouCA开源文档数据库的财经领域选取2万多篇文档作为素材,利用嵌入技术映入低维向量空间,在那里经过聚类计算后从每个聚类簇(平均每簇120篇文档)提取摘要,再返回文本形式做成多文本摘要。
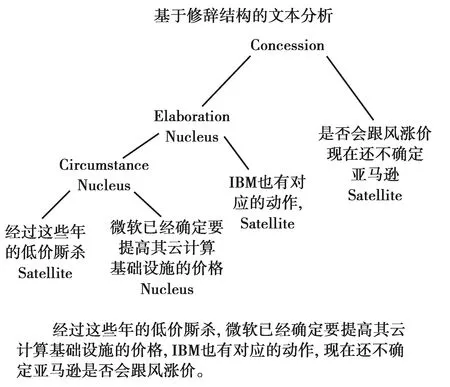
图4 基于修辞结构的文本分析Fig.4 Text analysis based on rhetorical structure
2020年我们利用上述多文本分析挖掘技术和知识嵌入技术完成了一个第二代浏览器的原型[37],所谓第二代浏览器,是作者在2005年提出的一个想法[38]。现在的浏览器功能单薄,只能帮助你从网上获取一个又一个的页面展示给你看,但是如果你出一个题,要求浏览器把网上有关信息综合起来并提供一个综述报告,它就做不到。第二代浏览器就是要完成这个任务,它的一个模型见图5。[37]实现的第二代浏览器由两部分组成,第一部分是一个百科文献集成器KACTL[39],它基于预建的知识分类树实行万维网搜索并建立海量文献库。第二部分就是根据用户需求从文献库提取相关资料,用嵌入技术引入到信息空间中,提取数值形式的多文本摘要,然后再恢复为文本形式提供给用户[37],见图6。在这里,文献[37]和文献[38]的主要区别是文献[37]采用了嵌入技术。
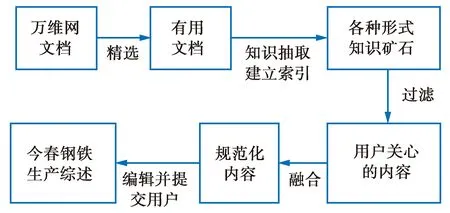
图5 第二代浏览器模型Fig.5 The second-generation browser model
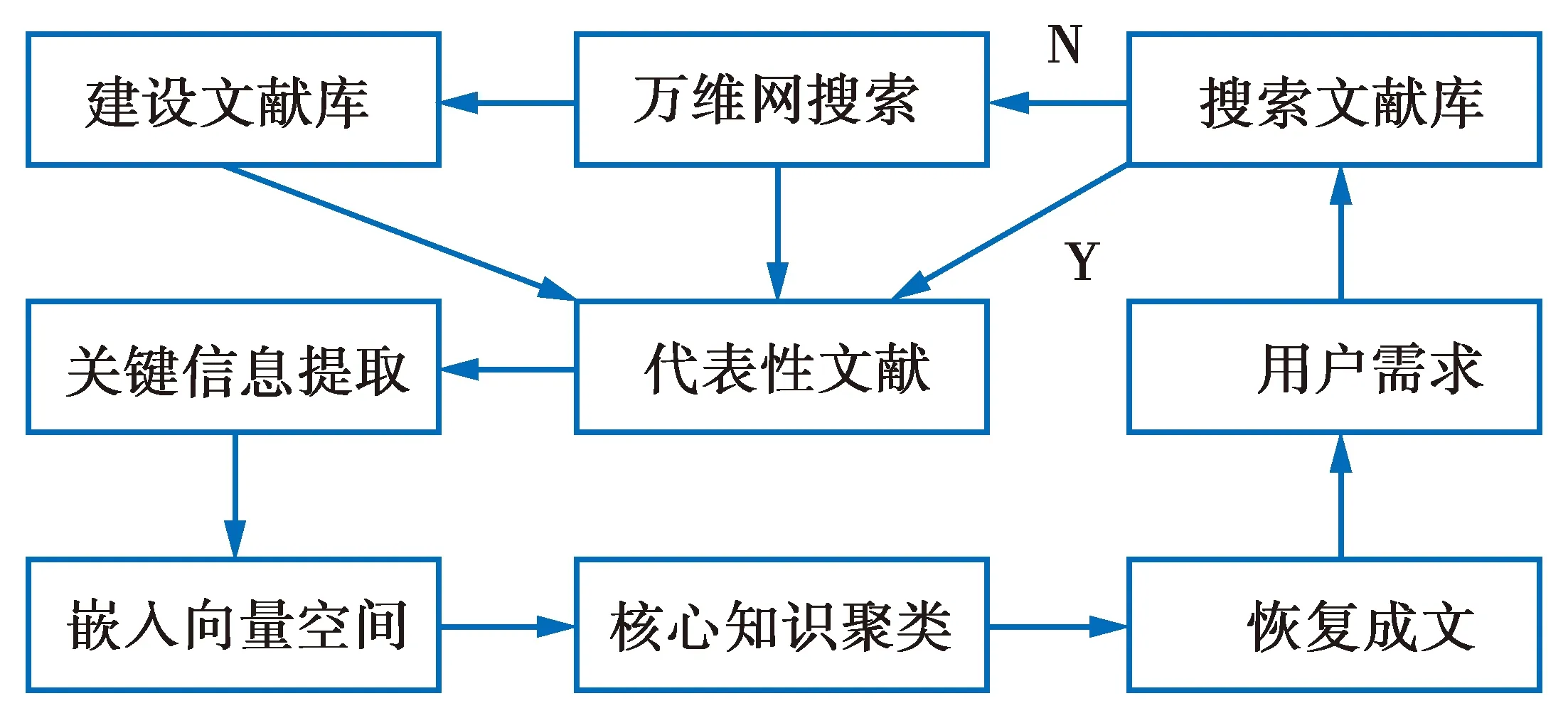
图6 一个第二代浏览器原型Fig.6 A second-generation browser prototype
其实,计算不一定是在线性空间中进行的,在很多场合下非欧空间的计算可能更能保证计算结果的真实性。很重要的一个理由就是客观上我们面临的数据集往往不是分布在欧氏空间中的。这有两种情形。情形一是需要处理的数据来自真实的三维物体,比如说一个花瓶。花瓶表面本是二维非欧流形,但是缺乏宏观直觉的计算机在判断采自花瓶表面的一组空间数据时很难发现它们属于一个非欧流形,于是往往直接用欧氏几何的方法把它们组合起来,结果可想而知。情形二是数据集并非来自客观的物理世界,而是某种统计数据。例如,对于一个很大的社会群体,其中所有成员的年龄、身高、体重、血压、和各种健康指标数据也可以构成一个高维的非欧流形。
常见的流形学习研究往往以欧氏空间为建模先验或隐含先验,来计算它们的空间分布和降维,结果造成计算结构的失真。2003年国外传来爆炸性消息,百年庞加莱猜想(任何一个单连通的闭三维流形一定同胚于一个三维的球面)证明了[40],证明的工具是以意大利数学家名字命名的Ricci(曲率)流。这是一组偏微分方程,建立了黎曼流形上的黎曼度量和Ricci曲率的关系。庞加莱猜想的证明给了我们很大的启示,使我们想到Ricci流也许可以用来解决数据的非欧空间建模问题。2019年李阳阳通过建立数据点之间的测地线逐步学习黎曼度量,使用Ricci方程组计算曲率,方程组的执行逐步‘拉平’了流形,最后得到一个曲率处处相等的n维平坦流形。此时的降维就容易了[41]。当然还要解决一些具体问题,例如方程计算的离散化,从三维推广到任意n维,负曲率的处理,等等。我们称这一方法为几何流学习或流学习。它应该有很好的发展前途。
我们早已指出:知识图谱支撑平台(以下简称知识图谱平台)的开发长期以来被忽视[14]。对于一般的大知识系统则更是这样。2020年我们考察了51个网上有介绍的知识图谱平台,分析了各个平台的功能模块,总结目前知识图谱平台的普遍问题如下[42-43]:
● 知识图谱平台尚未被公认为是一个独立的研究课题和软件产品。
● 知识图谱平台的设计者尚未足够关注一些新的技术挑战,例如大知识管理和处理技术。
● 特别是,我们没有看到哪个平台可以支持多知识图谱的合作运行。这方面的技术严重欠缺。
● 还有,大部分知识图谱平台不能支持知识图谱的全生命周期运转。
● 类似于软件代码共享的知识图谱平台开源共享还未成规模。
● 未见分布式知识图谱支撑平台。
事实上,我们早从2016年开始就发现并研究过这些问题[14],同时着手设计和开发通用知识图谱支撑平台HAPE[44]。它的特点第一是独立于任何特定的知识图谱,可以承载和运行来自不同开发者的产品。
第二是采用客户/服务器架构。第三是通过图谱浏览器(客户端)和图谱操作系统(服务器端)集中了两端的主要功能,共包括八个功能模块,分别体现了大知识系统的10个特征。见图7、图8。第四是全高级语言编程,系统容易修改和移植。第五是其中客户和服务器分别用适合于两端功能的脚本语言Javascript和Python编写。第六是在RDF三元组triplets之上建立了一组高级知识结构,包括topic(话题), taxonomy (分类体系), snapshot (快照)等。第七是为两端分别开发了专用的知识脚本操纵语言各一个,它们是K-Script-c和K-Script-s[45],可以直接在这些高级知识结构上操作,就像一般高级语言可以在数组、记录或先进后出栈上操作一样。第八是开发了大知识查询语言BSparql[46],可以在大知识图谱这样的大规模知识网络上操作。HAPE后来又发展为HAPE 1000[47], 后者的主要新功能是集成的功能模块达1000个以上,以及初步具备了多知识图谱联合处理能力和全生命周期支持知识图谱开发、使用和演化的能力。
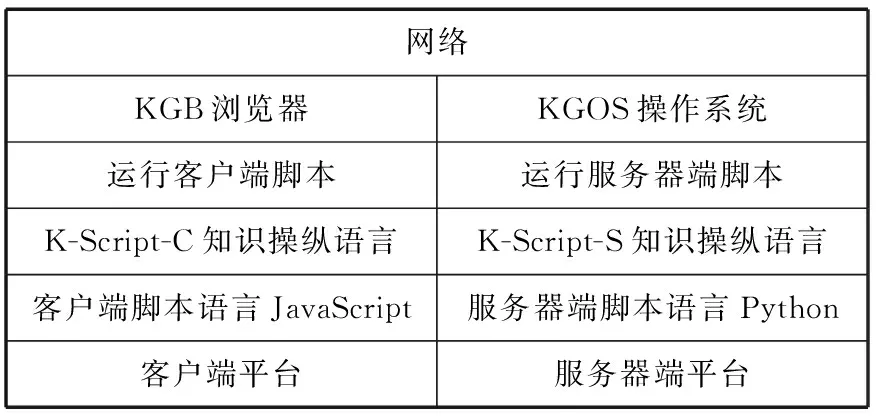
图7 HAPE系统Fig.7 HAPE System
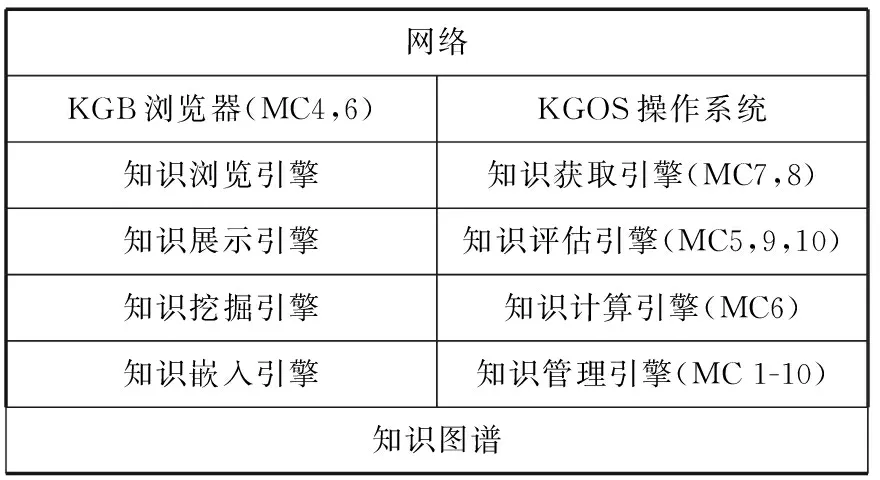
图8 HAPE功能Fig.8 HAPE Modules
知识图谱平台不能只有一种方案、一种模式,我们有一个开发一种新语言的计划及其初步设计[43],这个语言应该能够描述和生成各种不同的知识图谱平台,它应该是一个可执行的软件规格说明语言、一个可以解释执行的语言、一个模块化的语言、一个可以边设计边执行边修改的语言、一个可移植的高级语言和一个可以生成知识图谱全生命周期平台的语言,但是鉴于开发力量不足,目前还未具体实现。
我们在第3节谈到了大知识建模的众知和众智特性。众知是众智的基础,但若众知不能产生众智,众知的价值就要大大降低。因此,任何大知识编程语言必须能够体现出智能涌现的特性。历史上,我们曾经见过很多的人工智能语言,可是到了大数据时代,却发现能够表达智能的知识处理语言非常缺乏,能够被广泛使用的知识处理专用语言凤毛麟角,寥寥可数,为什么呢?为何不见现代版的人工智能语言?我们发现这是因为传统的人工智能语言都是基于某种特定的认知模型,例如LISP的模型是递归函数[48], Prolog的模型是Horn逻辑[49],Ops5的模型是Post产生式系统[50]。现实的人工智能问题非常复杂,非一种或两种模型可以解决,而是需要强大的知识后援和复杂的算法。传统的人工智能专用语言模式满足不了此需求,就只好让位给通用的高级编程语言了。大知识处理的复杂性和多样性远超大数据处理。大知识编程语言的一般性(适用于各类问题编程)和专用性(特别方便智能算法编程)难以兼顾,形成了鱼和熊掌的两难关系。鱼是灵活的,可以穿行于各种水道中。就好像面向过程的通用编程语言可以编写各种应用程序一样。而熊则是笨拙的,但力气巨大,若被它一掌击中,谁也难有活路。就好像面向任务的编程语言解决某类问题特别方便,但不能适用于一般问题。新的人工智能语言应该是面向过程,还是面向任务呢?前面在第6节提到了我们为HAPE平台开发的面向知识操纵的专用语言K-Script[44],包括K-Script-c和K-Script-s,就是面向任务的专用语言。因为它们主要适用于我们在知识图谱上定义的高层次知识架构。至于BSparql[45],它是Sparql语言的大知识扩充,可以对知识图谱中不同类型的知识子结构(如树、环、链、网、路径、嵌入空间等,以及由它们递归组成的更高级知识结构)做查询。BSparql稍加扩充,还可以应用于一般的网络型知识。但是BSparql的应用灵活性毕竟是有限的,不能当作面向问题的高级语言使用。它仍旧是缺乏鱼类特性的熊掌。在实际使用过程中我们的体会是:在人工智能语言设计方面,‘鱼’和‘熊掌’的功能哪一样都不能缺。但是要把它们融合成一个单一的、结构良好且合理的大知识编程语言还是一个不易完成的任务。
学术界和产业界,包括我们自己,在大知识领域的工作还只能说是开了一个头,下面该做的事情千头万绪。用一句老话来说就是万里长征走了第一步。最主要的不是已经做了什么,而是下一步需要做什么,本文的小节标题同时也表明了我们将继续努力的方向,主要是大知识建模、大知识计算、大知识平台以及大知识编程语言。
致谢:
本工作得到国家自然科学基金61621003的支持。作者感谢重庆邮电大学张清华教授和周雄同学在整理讲稿方面提供的帮助。
猜你喜欢 海量图谱建模 高清大脑皮层发育新图谱绘成军事文摘(2022年24期)2022-12-30一种傅里叶域海量数据高速谱聚类方法北京航空航天大学学报(2022年8期)2022-08-31基于图对比注意力网络的知识图谱补全北京航空航天大学学报(2022年8期)2022-08-31基于FLUENT的下击暴流三维风场建模成都信息工程大学学报(2021年5期)2021-12-30绘一张成长图谱少先队活动(2020年12期)2021-01-14联想等效,拓展建模——以“带电小球在等效场中做圆周运动”为例中学生数理化(高中版.高考理化)(2020年11期)2020-12-14求距求值方程建模初中生世界·九年级(2020年2期)2020-04-10海量快递垃圾正在“围城”——“绿色快递”势在必行当代陕西(2019年14期)2019-08-26基于PSS/E的风电场建模与动态分析电子制作(2018年17期)2018-09-28“海量+”:大学生品格提升的浸润方——以高职艺术设计专业为例消费导刊(2018年10期)2018-08-20猜你喜欢
- 2024-01-16 廉政知识考试题库
- 2024-01-15 2024年XX县领导干部廉政知识考试题库
- 2024-01-04 2024年(10篇)关于党务知识考试题库【优秀范文】
- 2023-08-06 2023年小学生国防知识教育6篇(完整)
- 2023-08-03 2023年度夏季四防知识5篇(精选文档)
- 2023-08-02 植物知识小百科4篇
- 2023-07-14 七一知识题库(258题)【优秀范文】
- 2023-07-13 2023年“三抓三促”行动应知应会知识集锦
- 2023-06-17 2023年党团知识竞赛主题
- 2023-05-08 了解一些全身麻醉的知识
- 搜索
-
- 2020年第三季度思想汇报范文 09-12
- 党员政治生日感言六篇 08-11
- 信访工作流程风险点及风控措施 10-18
- 某银行党委班子成员2019年度民主生活会 06-10
- 人民法院党组书记、院长专题民主生活会 02-12
- 2篇“坚持政治建警全面从严治警”自查 09-04
- 派出所辅警队伍管理制度 03-13
- 党群部部长岗位职责 10-14
- 党政办存在问题和整改措施 07-14
- 党务日常工作清单(分工) 03-13
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
