首页 > 心得体会 > 学习材料 / 正文
Seq2Seq中文文本摘要在金融知识引擎系统中的应用
2023-01-13 13:00:07 ℃谷葆春
(北京信息科技大学 计算机学院,北京 100101)
对于大多数中小投资者来说,由于信息获取的滞后性和非系统性,在和专业机构、游资以及很多量化资金的较量中,经常成为被收割的对象,难以获取满意的收益。因为在投资市场公司数量众多,散户的精力有限,缺少投研能力,因此没办法做到了解和熟悉大部分公司的基本面。
美国的AlphaSense公司已经开发出新一代的金融知识引擎系统,它可以从新闻、财报各种行业网站等获取大量数据、信息、知识形式的“素材”,然后通过自己的逻辑和世界观将这些素材组织成投资决策。国内目前还没有类似的系统,因此本文为中小投资者提供了一种在短时间内获取公司较多有价值投资信息的方法。
使用Seq2Seq深度学习模型,可以通过在Encoder端输入新闻、财报、公告和研报等数据,在Decoder端输出相关重要信息的摘要,从而为投资者节省大量的时间,并为他们的买入和卖出提供辅助决策。
文本摘要是对特定的文本信息,实现抽取或概括其主要含义,同时能保留原文本重要内容的一种文本生成任务。文本摘要技术一方面能对文本进行简洁、准确的总结,节省用户阅读和获取信息的时间,另一方面传达了原文内的主要内容,保证了用户获得信息的有效性。
摘要分为抽取式和生成式两种。抽取式摘要主要从文中选取跟中心思想最接近的一个或几个句子,组成最后的摘要;
而生成式摘要则是在理解原文内容的基础上,用自己的语言概括原文的核心思想,从而达到生成最后摘要的目的。
(1)早期的LSTM方法;
(2)早期的Encoder-Decoder模型,如lstm2lstm;
(3)Seq2Seq + Attention模型;
(4)Self-Attention和Transformer,自注意力机制;
(5)预训练+微调,例如Bert与PreSumm等。
近两年虽然Bert模型在许多摘要任务中有着较为出色的表现,但Seq2Seq + Attention模型仍然有自己的应用场景。考虑到普通用户的资源情况,本文采取Seq2Seq + Attention模型实现相关金融数据的摘要处理方式。
3.1 Seq2Seq模型
Seq2Seq即Sequence to Sequence,也就是序列到序列的意思,模型结构如图1所示。在文本摘要中输入序列为新闻或财报等原文,而输出序列为生成的原文摘要。Seq2Seq模型拼接了两个RNN系统的模型,分别称为模型的编码器Encoder部分和解码器Decoder部分。Encoder将变长源序列映射为定长语义向量并组合在一起,而Decoder将该向量映射回变长目标序列。
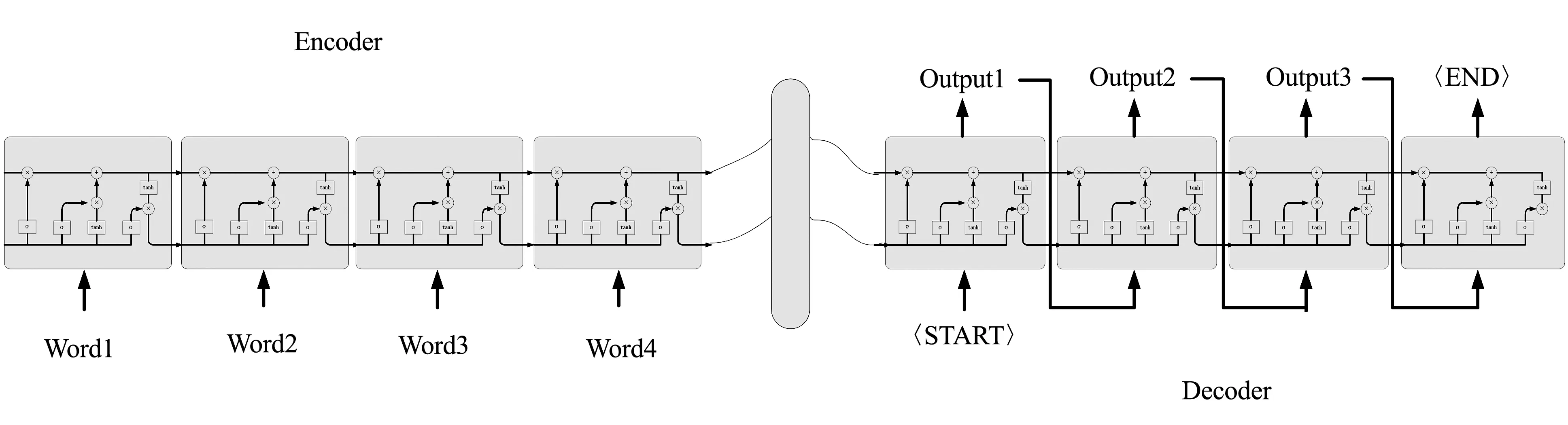
图1 Seq2Seq模型
给定输入序列=(,,…,),编码器将其转换成一个向量:
=(,,…,)
(1)
=(,-1)
(2)
是时刻的隐层状态,由当前输入和上一个单元的输出共同决定,是由整个序列的隐层向量得到的向量表示,由最后一个编码器输出,是解码器从编码器接收的唯一信息。
解码可以看作编码的逆过程,根据给定的语义向量和之前已经生成的输出序列,,…,-1来预测下一个输出的单词。
=argmax()=
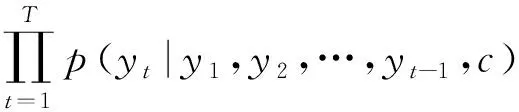
(3)
(|,,…,-1,)=(-1,,)
(4)
表示时刻预测的结果,是解码器Decoder的隐藏层。
3.2 加入Attention机制
Encoder-Decoder模型很经典,但其局限性在于编码和解码之间的唯一联系是固定长度的语义向量,即编码器要将整个序列的信息压缩进一个固定长度的向量中。这有两个弊端,一是语义向量无法完全表示整个序列的信息,压缩损失了一定的数据。二是先输入的内容携带的信息会被后输入的信息稀释掉。输入序列越长,问题越严重。这样在解码的时候一开始没有获得输入序列足够的信息,解码时准确率也会打一定折扣。
为了解决上述问题,Attention模型被提出。Attention模型在输出的时候,产生一个注意力范围表示接下来输出时重点关注的输入序列部分,再根据关注的区域来产生下一个输出,如此反复。Attention模型增加了模型的训练难度,但它提升了文本生成的效果。
在解码时,由提示当前输出对应的源序列的隐层状态,而不是在每步解码中都用同一个语义向量,用表示每步使用的语义向量后如下:
p(|,,…,-1,)=(-1,,)
(5)
=(-1,-1,)
(6)
其中,为某一步解码时的隐层状态,引入了相应信息,为激活函数。
代表对源序列信息的注意力,对不同输入的隐层状态分配不同的权重,由于输入输出序列往往长度不相同,此步还起到了对齐作用,整个构成了一个alignment model,定义():

(7)
其中为解码阶段的第步,为源序列的第个输入。
引入注意力机制后,输入的隐层状态不再经过整个源序列编码过程的传递,而直接作用于语义向量,减少了信息损失。
的定义为:

(8)
一个softmax层可以将归一化为,是注意力得分,即量化输入的隐层状态被第个输出分配的注意力,定义为:
=tan(-1+)
(9)
其中,tan为激活函数,是将输入输出隐层状态进行线性组合的注意力得分计算方式,另外还有dot product等不同的设计,但最终是都为了让相关输入的隐层状态与当前输出的隐层状态有更高的得分。
拥有更高注意力得分的输入,在语义向量的计算中有更高权重,从而为当前输出的引入了主要的信息,解码过程的语义向量不再是无差别,而是基于源序列与目标序列的依赖关系建模得到。
模型训练时,通过反向传播让输出更接近结果,更新隐层状态与注意力函数的参数。
总而言之,通过训练,注意力机制可以对关系较大的输入输出赋以较大权重(两者在转换中对齐的概率更大),对位置信息进行了建模,从而减少了信息损失,能专注于更重要的信息进行序列预测。
step_1:数据预处理
数据集采用的是网上的新浪微博数据,每篇文章由正文和标题组成,标题作为正文数据的摘要,总数量为45万个样本,选取其中的40万个数据作为训练数据。每篇正文平均字数为45个字,字数标准差为11,最多字数为513,最少字数为14。标题平均字数为11个字,字数标准差为3,最多字数为34,最少字数为2。
使用jieba分词器对正文和标题数据进行分词操作,然后在正文中去掉停用词,标题中的停用词则不用去除,因为去掉停用词之后,标题的意思会变得不连贯。
对标题数据加上开始标记“GO”和结束标记“EOS”。对长度不同的正文数据,以最长长度为基准,长度不足的填充数据“PAD”。
step_2:使用词向量
使用维基百科中文词向量实现中文词汇到向量的映射,该词向量表有35万个词语。有些词语没有出现在该表中,则对这些词语(UNK)需要单独构造词向量。
正文中如果有过多的UNK,或是长度超过设置的最大长度(80),则该数据会被去除。因为过长的正文数据会造成生成的摘要效果不佳。
step_3:建立模型
先构造基本LSTM单元,其隐层结点的数量为256个,后面接一个dropout层。采用双向RNN网络,把2层LSTM基本网络堆叠在一起,形成编码Encoder层。双向RNN网络是当前的输出除了与前面的序列有关系,与后面的序列也有关系的网络形式。
对于Decoder层的构造,首先是把sequence_length等参数传进来,然后同样构造2层RNN网络,在训练时,直接将标题数据作为输入,而不是将上一步的结果作为输入。而在测试时,则使用上一步的结果作为输入。
step_4:训练模型
指定好Scope域,保证训练好的权重参数,可以在测试时重复使用。训练的各项参数分别是每次的batch_size为64,学习率为0.0005。损失函数采用tensorflow的sequence_loss判断预测结果与目标值是否一致。
step_5:测试数据及结果评测
测试时,首先恢复之前的Seq2Seq模型,读取保存的session,输入测试数据,测试数据采用样本数据中剩下的5万个数据,将网络前向传播执行一次,最后生成的摘要数据保存在摘要文件中。中文文本摘要采用LawRouge评价器,它支持Rouge-1、Rouge-2以及Rouge-L三种评价。使用files_rouge.get_scores方法对模型输出摘要文件列表和参考摘要文件列表进行评价,再用三个评价的加权平均作为最终评价:0.2*scores["rouge-1"]["f"]+ 0.4*scores["rouge-2"]["f"]+ 0.4*scores["rouge-l"]["f"]。
最后的结果为0.8949,生成的摘要结果满足了用户的需求。
对于投资者来说,及时、准确地获取公司基本面和消息面的信息,才能对股票等投资标的下一步的走势和节奏进行合理的判断。本文采用Seq2Seq + Attention模型,对公司新闻、研报和财报等信息实现自动摘要生成,总体结果令人满意。后续的改进方向是能形成自己的逻辑和世界观,从而将这些素材组织成投资决策,对于摘要的准确性提高则可以考虑结合Bert模型。
猜你喜欢 解码语义向量 向量的分解新高考·高一数学(2022年3期)2022-04-28韩国语“容入-离析”关系表达及认知语义解释东疆学刊(2022年2期)2022-04-22解码 四十五度仰望天空睿士(2020年6期)2020-08-18文化解码南方周末(2019-12-19)2019-12-19文化 解码南方周末(2019-07-18)2019-07-18文明 解码南方周末(2019-05-09)2019-05-09向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
