首页 > 心得体会 > 学习材料 / 正文
突发环境事件中微博影响力的预测研究
2023-01-13 13:05:08 ℃姚 婷,赵锦栋,杨 莉
(1 南京邮电大学 地理与生物信息学院,南京 210023;
2 南京邮电大学 经济学院,南京 210023)
突发环境事件,是指由于污染物排放或自然灾害、生产安全事故等因素,导致污染物或放射性物质等有毒、有害物质进入大气、水体、土壤等环境介质,突然造成或可能造成环境质量下降,危及公众身体健康和财产安全,在导致生态环境破坏的同时,也可能对社会城市化发展产生不利影响,亟需采取紧急措施予以应对的事件。近年来,国内突发环境事件不时出现,不仅发生了伤亡事故,还会形成直接经济损失,同时也给社会稳定和日常生活带来了威胁。
随着互联网的迅速发展,微博从最初的社交属性延展到如今的自媒体属性,改变着人们的信息传播模式以及传媒习惯,并逐渐成为了在社会媒体中即时性最强、用户范围最广的信息传播平台。但因微博的使用门槛较低、而且具有无需实名认证、用户量大、连通性高等特点,则也较易滋生出不良舆论。在突发环境事件发生时,不良舆论就可能通过微博这一途径出现大范围传播,甚至发生不可控的事件与结果。
因此,当突发环境事件发生时,如何监测微博中的不良舆论的传播态势,正确引导舆论走向即已成为目前学界面临的热点问题。本文通过提取突发环境事件中的微博特征,利用机器学习技术建立突发环境事件中微博影响力的预测模型,研究微博影响力的影响因素,并分析微博用户各类言论的影响力。在突发环境事件发生时,有助于相关机构快速做出反应,更加迅速、准确定位高影响力微博与用户,从而抑制微博上不良舆论的传播,营造良好舆论氛围。
1.1 突发事件的舆情研究
目前国内外学者对于突发事件中的舆情研究主要分为3方面:
(1)从舆情本体入手,研究舆情生成及演变路径,主要通过采用搜索指数、发帖量等指标对舆情演变阶段进行划分,分析各阶段的情感强度和主题特征,把握舆情走势,从而提出各阶段的应对措施。
(2)通过剖析突发事件应急管理中网络舆情的传播规律,构建传播规律模型,对突发事件的舆情发展进行预测,并采取相应的措施。
(3)对舆情发展过程中的主体展开了深入研究,涉及政府部门、意见领袖、网民等,兼顾不同舆情主体的利益,研究突发事件网络舆情主体博弈的过程,从而提出舆情演化过程中各主体需要采取的措施,以确保事件发生时网络舆情的良性运转。
1.2 微博影响力的相关研究
国内外有关微博影响力的评价和研究主要包括2方面:
(1)对微博用户影响力的研究和预测。学者们提出了多种针对评价和预测微博用户影响力的方法和模型,包括h指数、BCI指数、TwitterRank模型等,使用的主要衡量因素包括关注数、粉丝数等。
(2)单条微博的影响力的评价。学者们普遍用转发数来衡量微博影响力,每一条微博影响力的扩大须依靠转发行为,基于这一理论,提出了不同的微博影响力的预测模型,分析方法主要有多层线性模型、PageRank算法等,但由于数据采集困难、微博影响力难以量化等原因,该方面的研究较少。
1.3 国内外研究综述
综上所述,国内外关于微博影响力和突发事件中的舆情研究都已经取得了长足的进步,建立了较为完整的研究体系,但是目前的研究仍然有着一定的局限性,依然存在有待改进的方面:
(1)突发事件中的舆情方面的研究视角较为单一。现有的研究多半为针对舆情演化走势的研究和预测,并没有对舆情演化过程中的各类人群特征做深入剖析,重复劳动较多,且对策、建议研究尚不成熟。
(2)微博影响力的研究大多以微博用户为主体,对单条微博影响力的研究仅仅考虑粉丝、注册时间等用户层面的简单影响因素,并且由于微博影响力量化的不科学,这样的分析方法和模型不具备很好的泛化性。
本文对当前的研究不足进行改进,并提供了方法和研究视角上的创新。在突发环境事件中,创新地从微博影响力角度入手,从多个层面综合选取微博影响力的影响因素,利用机器学习技术建立微博影响力预测模型,并对各影响因素进行分析。本研究有助于识别突发环境事件舆情演化过程中的高风险人群和高风险时期,提出舆论引导的建议和实践上的参考,给予管理者决策支持。
在微博影响力预测模型的选取中,本文经过对多个模型的性能比较,选取基于AdaBoost算法的预测模型作为最优模型。
AdaBoost是一种迭代学习算法,其核心思想是将弱的基础分类器迭代成一个强的最终分类器,本文使用决策树作为基学习器。虽然在最初的迭代中,基础分类器的分类效果并不理想,即误判率较高,但经过几轮迭代,不断增加误分类样本的权值,并在更新了权值样本的基础上不断构建新的分类器,从而使得分类精度得到有效提升。
AdaBoost算法没有关于数据的假设分布,实用性很强,而且对过拟合不那么敏感。
以本文研究的二分类问题为例,AdaBoost算法步骤如下:
假设个初始测试数据为{(,),(,),…,(x,y)},y∈{1,1},1为负样本(低影响力样本),1为正样本(高影响力样本);
每个样本x包括个特征,累计迭代次。
(1)初始化训练集数据的权重分布,使每个训练样本具有均匀的权值分布,设为第个样本的初始化权重。对应的数学表述可写为如下形式:

(2)循环训练次,1,2,…,。
①对权值分布更新为D的样本进行迭代,得到基本分类器G()。
②计算G()的分类误差率,具体公式如下:

③计算G()的系数α,具体公式如下:

由式(3)可知,随着e的减小,α不断增大,同时分类精度越高,基本分类器在最终分类器中所占的权重越大。
④更新训练数据集的权重分布,具体数学公式如下:

其中,Z是规范化因子,推导出的数学定义式可写为:

从公式中可以看出,基本分类器G(x)错分类的样本权值在迭代过程中不断扩大,正确分类的样本权值通过迭代不断缩小,从而在此后的机器学习中更加重视错误分类的样本。
(3)实现基本分类器的组合,可由如下公式来表示:

得到最终分类器,即:

该模型用于对微博的影响力进行预测,将提取得到的微博特征数据输入模型,预测微博的影响力等级。
3.1 数据获取及处理
本文以“xx突发环境事件”为例,通过编写爬虫程序,对与事件相关的热门话题下的微博展开爬取,共得到46265条微博数据,每条微博数据都包括:用户ID、所属地址、微博内容、发布日期、点赞数、评论数、转载量等属性。
获取数据之后,对数据中重复、无效以及无关数据进行删除,经处理后的微博数据剩余7540条。
3.2 指标体系构建及微博特征提取
3.2.1 指标体系构建
本文参考濮小燕提出的微博特征提取思路,结合突发环境事件的特点和实际情况,最终选择从微博内容、时间、用户基本信息和用户活跃度四个层面上对微博特征进行提取,选取的微博特征及特征值划分情况见表1。本文提取了18个微博特征变量。
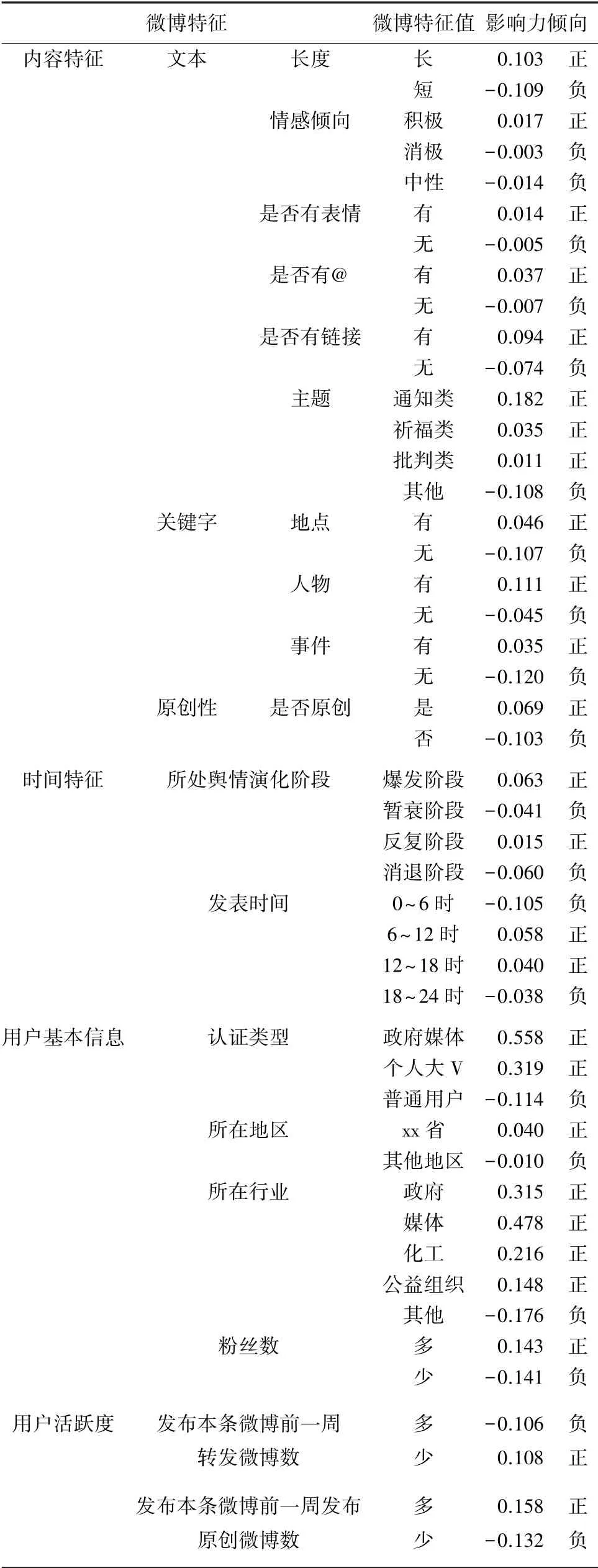
表1 微博特征提取表Tab.1 Microblog features extraction table
3.2.2 微博情感特征提取
在微博特征的提取中,大部分微博特征可以直接进行提取,所处舆情演化的阶段这一指标的特征值由舆情生命周期的划分决定。微博的情感倾向和主题则分别使用了朴素贝叶斯分类器和LDA主题模型的方法进行提取。本文选择使用朴素贝叶斯分类器对微博情感倾向特征进行提取。这里需用到的数学公式为:
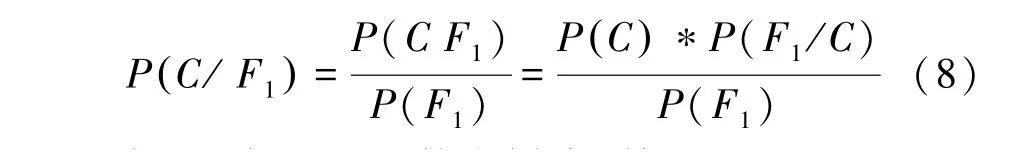
式(8)表示对于某个样本,特征出现时,该样本被分为类的条件概率。
本文从有关“xx突发环境事件”的微博数据中随机选取三分之一进行人工标注,分为“积极”、“消极”和“中性”三类,这部分数据用于朴素贝叶斯分类器的训练和模型预测精度的计算,预测精度由十折交叉验证的方法获得。通过计算,分类器的预测精度可以达到0.945,符合本文研究的要求。通过训练得出的模型可以对其余数据的情感倾向进行预测,提取微博的情感倾向特征。在7540条微博中,情感倾向为积极的博文数有2016条,情感倾向为消极的博文数有3311条,情感倾向呈中性的博文数有2123条,这说明在突发环境事件中公众的负向情感强度较正向情感强度更高。
3.2.3 微博主题特征提取
在主题特征的提取中,本文选择有关“xx突发环境事件”的微博数据,利用LDA主题模型提取主题。
LDA主题模型认为一篇文档包含多个主题,文档中的每个单词都属于其中的一个主题。一篇文档的形成,首先在文档中抽取一个主题,然后再在这个主题下抽取一个单词,最后,重复进行前两步,直到文档中的全部单词都被遍历。
LDA的核心公式如下:
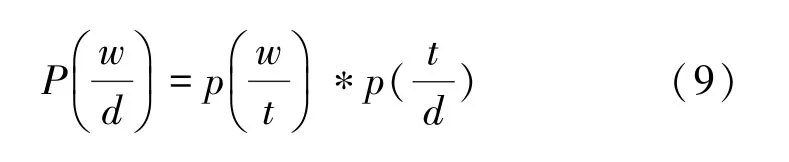
其中,为目标语料库中的一篇文档;
是该篇文章中的一个主题;
是该主题中的一个单词。
LDA主题模型提取主题结果见表2。

表2 LDA主题模型提取结果表Tab.2 LDA subject model extraction results
由表2可知,共提取出10个话题,每个话题包含5个特征词,每个特征词都给出了其关联度。根据主题提取结果,结合事件的具体情况,大致可将微博数据按话题特征分为4类,分别是通知类、祈福类、批判类和其他。
3.2.4 微博影响力量化
本文选取微博的点赞数、评论数和转发数三个指标对微博影响力进行综合衡量,指标权重由熵权法确定。
若选取个评价指标,个评价对象,构成的数据矩阵R=(r),则:



则第个指标的熵权w定义为:

其中,0≤w≤1,w为第个指标的熵权。
计算得到的指标权重及微博影响力计算方法见下式:

其中,、、、分别表示该条微博的影响力、点赞数、评论数和转发数。
3.3 微博影响力预测模型评价及微博特征分析
3.3.1 微博影响力预测模型评价
本文选取处理后的7540条微博作为实验数据,每条数据包含18个微博特征变量。利用式(12)计算每条微博的微博影响力,根据研究事件的特点,结合数据分布的真实状态,对微博影响力进行二分类处理,设定分类阈值为3,即影响力数值大于等于3的微博为影响力高的微博,小于3的为影响力低的微博。
基于同样的数据集,本文分别基于决策树、AdaBoost、Bagging和随机森林等算法构建预测模型。使用十折交叉验证的方法计算各模型的性能,选择预测精度、召回率和度量作为评价指标,计算结果见表3,与其他模型相比,基于Adaboost算法的预测模型在各项指标上都有所提高,证明该模型性能最好,具有较强的泛化能力,预测效果较好。

表3 各预测模型性能比较表Tab.3 Performance comparison of prediction models
3.3.2 微博特征重要性分析
在本研究中,使用了18个微博特征,根据AdaBoost算法模型基于基尼系数计算变量的重要度的功能,绘制了变量的相对重要性图,如图1所示,即条形越长的变量对结果的贡献越大,条形越短的变量重要程度越低。
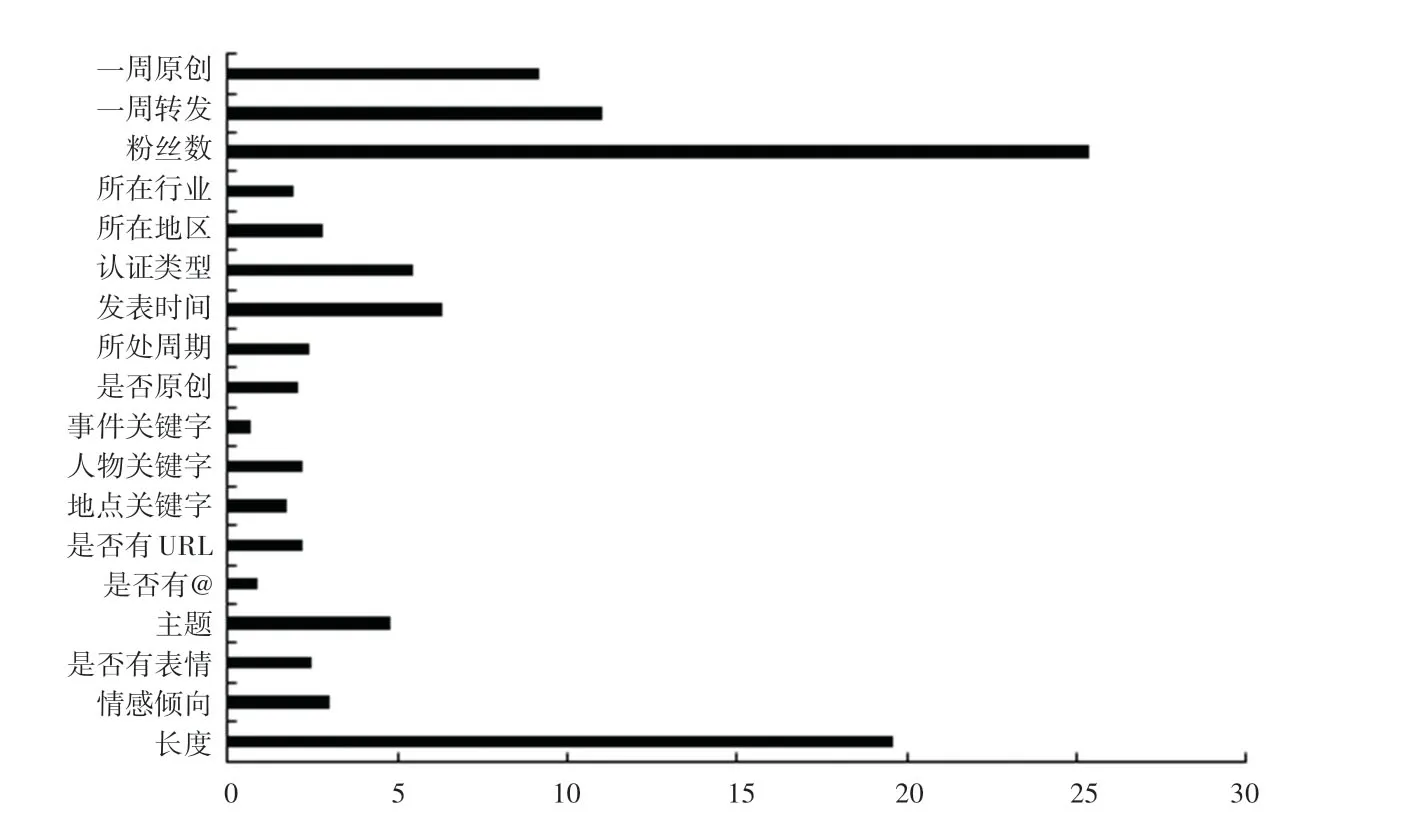
图1 微博特征值重要性表Fig.1 Microblog eigenvalue importance table
结果显示,模型中的各微博特征重要性相差较大。其中,重要性较大的7个特征从大到小依次是:用户粉丝数、微博长度、用户一周发微博数、用户一周发原创微博数、发表时间、用户认证类型和微博主题,而关键字特征、是否有@和链接等特征相对重要性较低。这说明粉丝数、微博长度、用户活跃度等因素对微博影响力大小至关重要。
3.3.3 微博特征值影响力倾向分析
为了进一步探究各微博特征值对微博影响力的影响倾向,对微博文本长度、粉丝数、发布本条微博前一周转发微博数、发布本条微博前一周发布原创微博数这4个指标进行二分类处理,以中位数作为类别的判定标准。本文参考张继东等人的研究思路,引入支持度的概念,并对微博特征值的影响力倾向的计算方法进行了描述,同时又阐明了各特征值与影响力两者的关联情况。具体计算公式如下:

式(13)中,Support(v)表示特征值v的高影响力支持度,即在所有特征值为v的微博数据中高影 响 力 微 博 数 据 所 占 比 例;
式 (14)中,表示全部微博数据的高影响力支持度;
式(15)中,(v)表示特征值v的影响倾向值,数值的正负表示该特征值对微博影响力的影响倾向,数值的绝对值表示该特征值对微博影响力的影响大小。计算结果见表1,基于计算结果,分别在内容、时间、用户基本信息和用户活跃度层面对微博特征值影响倾向展开研究,拟做阐释分述如下。
(1)内容层面。根据计算结果,分析内容层面的微博特征值的影响倾向,微博的长度、主题和原创性对微博影响力的影响较大,这与变量的相对重要性图相符。从微博长度来看,长文本微博比短文本微博的影响力更大;
从主题特征来看,一般通知类的微博影响力最大,祈福类微博和批判类微博的影响力也大于平均水平,而其他主题的微博影响力较小;
从微博原创性来看,相比非原创的微博,原创的微博具有更高的影响力。
(2)时间层面。时间层面包含微博所处舆情演化阶段和微博发表时间两个特征,每个特征包含4个特征值。从微博所处舆情演化阶段来分析,处于爆发阶段和反复阶段的微博较暂衰阶段和消退阶段的微博影响力更高,其中爆发阶段的微博影响力最高。这是因为在舆情爆发阶段,事件的严重性和突发性导致公众的关注度较高;
而在舆情发展的反复阶段,因为有伤亡情况和相关责任人刑事处罚等后续信息散布出来,导致次生舆情出现,再度引起事件热度提升。从微博发表时间来看,白天发布的微博比夜晚和凌晨发布的微博影响力更高,这也符合人们的作息习惯。
(3)用户基本信息层面。在微博用户基本信息层面,本文选取了4个特征,这4个特征对微博影响力的影响均比较显著。其中,政府媒体和大V用户发表的微博的影响力会更高,这主要是由于这2种用户的粉丝数比普通用户要更多,根据计算结果,政府媒体用户和大V用户的粉丝数分别是普通用户的25392倍和1502倍;
事件发生地的用户所发表的微博影响力会更高,说明事件发生地的用户相比其他地区用户容易受到更多关注;
相比普通行业,政府、媒体、公益组织的用户展现出更高的影响力倾向,同时化工行业的用户也呈现出较高的影响力倾向,这说明突发环境事件的相关行业工作者发表的言论更容易受到公众的关注,引发人们的共鸣。
(4)用户活跃度层面。用户使用微博的活跃度可以用博文数来衡量。实验结果显示,原创微博发布频率与影响力倾向成正比,转发微博发布频率与影响力倾向成反比。这是因为对于受众来说,只能接受有限的消息,某些博主发布微博较为频繁可能导致粉丝的选择分散,而有的博主发布微博的频率较低,正是因为这样,该博主一旦发博,其粉丝更可能认真阅读或转发。
3.4 各类微博言论的影响力分析
本文将“xx突发环境事件”中获取的微博数据进行人工分类处理,对各类微博言论的影响力进行分析。首先将数据分为媒体或大V用户发布的微博和普通用户发布的微博两类,对这2类微博的影响力进行计算,发现第一类微博的影响力平均值高达56.62,而第二类微博的影响力平均值仅为0.52;
接下来对第二类微博进行细分,分为不良言论、鼓舞性言论和其他言论三类。参考崔珊提出的不良文本分类体系,结合数据实际情况,在不良言论方面主要选取了谣言类、暴恐类、政治有害类等微博言论,在鼓舞类言论方面主要选取了加油打气、宣传积极事例等具有鼓舞人心作用的积极言论。结合舆情演化路径,分析舆情演化各阶段中各类言论的影响力水平,分析结果如下。
舆情演化路径中普通用户各类言论影响力变化图如图2所示。根据图2,在事件发展的整个过程中,不良微博言论的影响力水平最高,平均影响力数值达到了5.48;
鼓舞类微博言论的影响力水平其次,平均影响力数值为1.84;
其他微博言论的影响力水平最低,仅为0.29,这说明在突发环境事件中,由于不良言论的蛊惑性和欺骗性,很多不明真相的公众并不能正确地判断信息的可靠性,容易被外界环境所影响,而且还可能进行二次转发;
此外,网络上的鼓舞类言论同样影响力较大,具有积极的宣传作用。结合舆情发展阶段来看,在舆情发展的反复阶段,普通用户发布的各类微博言论的影响力均达到最高峰,在舆情发展的消退阶段达到最低值,这说明舆情发展的反复阶段是防范不良言论的紧要时期,同时也是积极引导的关键时期。

图2 舆情演化路径中普通用户各类言论影响力变化图Fig.2 Changes in the influence of various remarks of ordinary users in the evolution path of public opinion
本文构建了微博影响力评价的指标体系,利用AdaBoost算法建立突发环境事件中微博影响力的预测模型,并以“xx突发环境事件”为例进行了实例验证,结合舆情演化的生命周期对微博影响力变化规律进行研究。通过研究,发现影响舆情发展的主要影响因素,帮助相关部门了解舆情发展各阶段的特征,对于突发事件发生后微博网络舆情进行准确预测,及时制止不良言论,并进行正确引导,从而在突发环境事件发生时,确保网络舆情良性运转。
研究表明,模型效果比较理想,具有良好的预测能力,这对于相关部门在环境突发事件初期识别高影响力微博和打造高影响力微博具有重要的现实意义。突发环境事件中的微博的影响力受多层面微博特征的影响,其影响因素重要性排序为:用户基本信息、内容特征、用户活跃度和时间特征。在舆情发展的整个过程中,媒体或大V用户发布的微博影响力始终保持在很高水平;
而在普通民众发布的微博中,处于反复阶段微博影响力水平最高,消退阶段最低。从不同言论种类来看,不良言论的影响力最高、鼓舞类言论的影响力其次、其他言论的影响力较低。
基于上述数据分析及研究结果,在突发环境事件发生时,用户的基本信息对微博影响力最大,因此相关部门要重视自身微博平台的运营,积极与公众互动,多与政府媒体和大V用户建立合作,提升自身微博影响力;
在发布时间方面,白天发布的微博影响力会更大,政府部门应该在此阶段发布重要内容,来提高微博影响力;
在发布内容方面,媒体和相关部门要注意用词的准确度、真实性,发布长文本的微博来提高微博影响力,正确引导舆情发展方向;
在发布频率方面,要定期发布高质量原创微博,尽量在用户登录微博的高峰期发帖。在舆情发展的整个过程中,根据各阶段演化特征,在环境突发事件发生初期,相关部门应加强对高风险微博用户和高风险微博的防范,从源头阻止不良言论传播;
舆情发展的爆发阶段和反复阶段是容易导致舆情发展失控的高风险时期,相关部门要采取正面教育、科学引导、及时澄清和准确抑制的措施,保证舆情态势的平稳发展。
猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
