首页 > 心得体会 > 学习材料 / 正文
基于改进ABC和IDPC-MKELM的短期电力负荷预测
2023-01-15 16:00:09 ℃狄曙光,刘 峰,孙建宇,冀 超,董铎亮,蔄靖宇
(1.内蒙古电力(集团)有限责任公司包头供电分公司,内蒙古包头 014000;
2.上海电力大学能源与机械工程学院,上海 200090)
短期电力负荷预测对保证电力系统平稳安全高效运行具有重要意义[1-4],地区电力系统负荷受气候、经济、日期等多种因素影响,呈现周期性、随机性和波动性等特点,这也导致短期电力负荷预测具有很大的挑战性[5-8]。
统计学预测和机器学习预测是目前常用的两类短期负荷预测方法[9],由于电力负荷对外部因素影响较为敏感,单一预测方法很难得到满意的预测精度[10],而极限学习机、支持向量机等智能学习技术为短期电力负荷预测提供了新的研究思路,学者们围绕电力负荷数据处理、预测模型构建等方面开展了系列研究:Huang[11]、Kouhi[12]等学者对负荷与外部影响因素之间的关联性进行了研究,采用条件互信息法等手段选取特征子集,但是未考虑特征之间的冗余度,导致选取的特征子集未必最优。组合预测模型是当前短期电力负荷预测的研究热点,姚程文[13]等在电力负荷数据预处理的基础上,采用用遗传算法优化最小二乘支持向量机模型进行预测,仿真结果也验证了该方法的有效性,但是该模型复杂度较高,运行效率需要进一步研究;
魏健[14]等采用CNNGRU 复合模型进行短期电力负荷预测,预测精度好于一般单一模型;
朱凌建[15]等将高相关性特征向量作为预测模型输入,并构建融合卷积神经网络和长短时记忆神经网络的预测模型,但是没有考虑负荷数据时空差异性。而且,参数设定是机器学习技术面临的一个难题,传统反复实验获取参数的方法不仅效率低且预测精度不高。
为此,构建基于负荷数据最优特征子集提取、密度峰值聚类(Density Peak Clustering,DPC)和核极限学习机(Kernel Extreme Learning Machine,KELM)的短期电力负荷预测模型:采用DPC 算法对负荷数据进行聚类分析,充分考虑数据时空差异性对预测精度的影响;
设计最优特征子集提取机制,在充分考虑特征之间关联性的同时最大限度降低冗余度,提升预测效率;
设计多核加权KELM,以提高极限学习机预测精度;
设计改进的人工蜂群(Artificial Bee Colony,ABC)算法,并对DPC,KELM 参数进行优化求解。结果表明,本文提出短期电力负荷预测方法具有更高的预测精度。
短期电力负荷预测的目的是通过分析历史负荷、社会因素、气象因素等数据中的规律,实现对未来短期电力负荷的准确预测[16]。以某地区电网短期负荷预测为例,影响电力负荷的因素主要包括历史电力负荷Phis、电价Ep、节假日Hv、工作日Wd、周末We等社会因素(设定Hv=1,Wd=1,We=1 分别为节假日、工作日、周末,否则取值为0),温度tp、湿度hI、风速ws、太阳辐射sr等气候因素。构建如图1 所示的短期电力负荷预测模型,模型分为训练和预测2 个部分,主要包括最优特征子集提取、聚类分析、极限学习机3 个模块,并采用改进ABC 算法对参数进行优化配置。
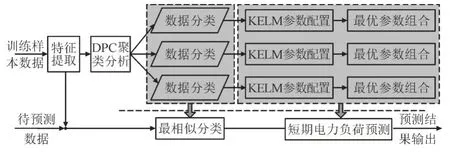
图1 短期电力负荷预测模型示意图Fig.1 Schematic diagram of short-term power load forecasting model
1)最优特征子集提取。设计最优特征子集提取机制,从输入特征集合FS=(Phis,Ep,Hv,Wd,We,tp,hi,ws,sr) 中选取对于预测结果最有益的特征子集FS,best,在降低数据维度、特征冗余度的同时,提升运算效率和预测精度。
2)聚类分析。采用密度峰值聚类理论对训练数据样本集合Sn={(})Di,Yi进行聚类分析,得到C个分类S′i(i=1,…,C)。(Di,Yi) 为:

3)极限学习机预测。训练阶段,采用极限学习机(Extreme Learning Machine,ELM)技术,对C个数据分类分别进行训练,得到每个分类对应的最佳参数配置。预测阶段,对于待预测数据(D,Y),找到其最相似聚类分类S′j,利用S′j对应的参数配置进行预测,最终得到预测结果。
4)改进ABC 算法。将DPC 及极限学习机参数配置过程等效成ABC 算法寻优过程,通过设计新型蜜源搜索和蜜蜂进化方式,提升改进ABC 全局收敛能力,得到最佳参数配置。
ABC 算法[17]模拟仿生蜂群集体觅食行为,将蜂群划分为雇佣蜂XEm、观察蜂XOb、侦查蜂XSc,不同类型的蜜蜂赋予不同进化方式,通过蜜蜂个体之间的信息交流实现最优解寻找。ABC 算法实现过程可以描述为:
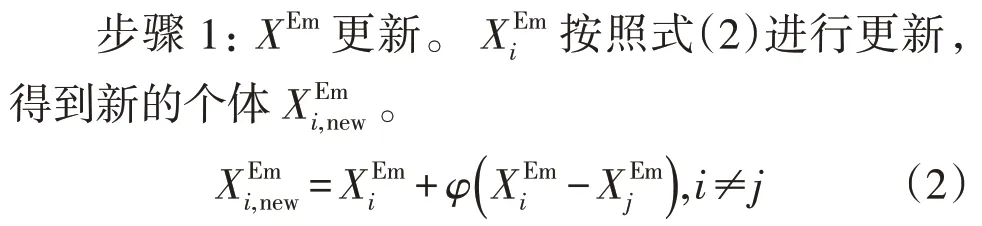
式中:φ为[-1,1] 均匀分布随机数。

式中:N为蜂群规模。
步骤4:XSc更新。当算法处于进化停滞状态时,对雇佣蜂执行式(5)更新,得到XSc。

式中:Xmax,Xmin为上下边界集合。
ABC 具有参数设置简单、易于实现的特点,但对于复杂优化问题存在收敛精度不高、容易“早熟”的缺陷[18]。为此,设计新型蜜源搜索和蜜蜂进化方式,以提升改进ABC(Improved ABC,IABC)的全局收敛能力。
2.1 雇佣蜂、观察蜂子种群自适应划分
ABC 在实现过程中,将雇佣蜂、观察蜂设置同等规模。但是,在算法进化初期,种群样本多样性较大,应采用更多的雇佣蜂进行更新;
随着进化次数的不断增加,种群样本逐渐降低,此时应采用更多的观察蜂进行更新,以扩展算法搜索空间。为此,将雇佣蜂、观察蜂子种群规模NEm,NOb分别设定为:

2.2 新的蜜蜂进化方式


式中:Xbest为蜂群最优解。
随机选取雇佣蜂子种群内N1(N1≤NEm)个体执行式(8)更新,其余个体执行式(2)更新。
2)观察蜂更新。ABC 采用轮盘赌的方式选取雇佣蜂再次执行式(2)更新操作,其实质为“2 次”雇佣蜂更新,降低了算法收敛效率。为此引入子种群最优解,提升算法收敛速度,XOb更新公式为:

从新的蜂群进化方式可以看出,蜂群在更新中引入了种群优秀个体信息,提升了算法收敛速度,并且反更新操作的引入保证了蜂群种群多样性,使改进的ABC 全局寻优能力更优。IABC 实现流程如图2 所示。

图2 IABC实现流程示意图Fig.2 Diagram of IABC implementation process
3.1 密度峰值聚类
2014 年,Rodriguez[20]等在《Science》上发表了密度峰值聚类算法,该算法能够识别出任意形状数据,具有实现建档、参数唯一、鲁棒性好等特点。电力负荷样本数据时空差异性对预测结果精度影响较大,为此,采用DPC 算法对样本进行聚类分析,使得预测更具鲁棒性。DPC 为数据点Xi设定局部密度ρi和最近点距离δi2 个属性:

式中:χ(x)为函数;
dij为Xi到点Xj的距离;
dc为截断距离,也是DPC 唯一参数。
对于第k个数据,定义判定参数γi,并给出其计算公式为γi=ρiδi,DPC 选择γi取值较大点为聚类中心。
DPC 对于大部分数据具有良好的聚类效果,但是存在明显缺陷[21]:截断距离dc以及聚类中心人为设定,效率较低,对分布不均匀数据聚类效果不理想。为此,引入邦费罗尼指数,提出改进DPC(Improved DPC,IDPC)。
1)邦费罗尼指数函数。引入邦费罗尼指数函数BN来度量(γ1,…,γN) 有序程度,BN取值越大,越有利于数据聚类。

从式(13)可以看出,BN依dc变化而变化,求解过程属于NP(Non-deterministic Polynomial)难题[22]。本文采用IABC 进行优化求解,即令:

通过IABC 迭代进化,最终得到BN取最大值时对应的最优解,该解即为最佳截断距离dc,best。
2)聚类中心自动确定dc,best确定后,计算每个数据点ρi,δi属性和γi。按照γi大小将数据样本降序排序,得到数据样本集根据式(15)计算重新排序后的每个数据点对应的聚类中心截止参数ωk:
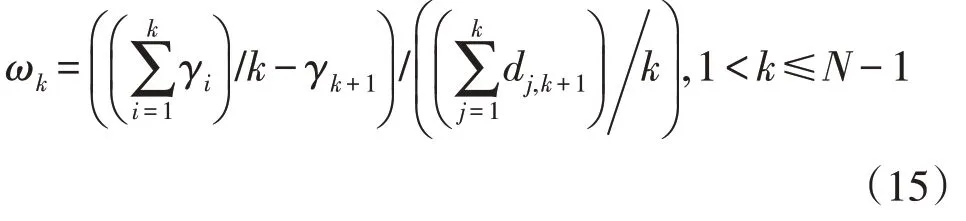
式中:γk+1为第k+1 个数据点的判定参数取值;
dj,k+1为第j个数据点到第k+1个数据点的距离。
定义ωk取最大值时对应的数据点为聚类中心截止点,该点以及排序在前的点即为聚类中心。聚类中心集合V=(C为聚类中心个数)确定后,根据δi取值大小,将剩余数据点划分到不同聚类中,从而得到C个分类{FC1,…,FCC} 。
3.2 最优特征子集提取
对负荷特征FS进行特征提取,能够在降低数据维度、特征间冗余度的同时,提升运行效率和预测精度[23]。定义特征提取向量l=(p1,p2,…,pM),
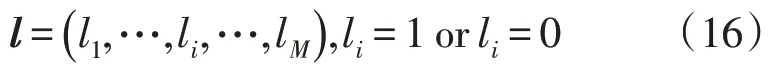
当li=1 表示对应的第i个特征被选取。利用l对FS进行特征子集提取:
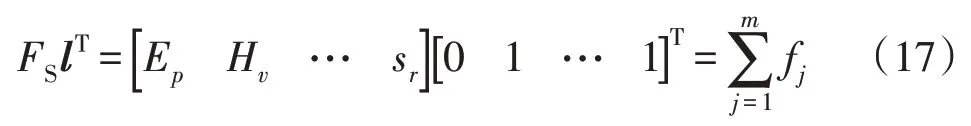
式中:fj为第j个提取特征;
m为提取特征总数。
1)评价指标。文献[24]指出,当式(18)定义的特征子集选取评价指标Ο(l) 的取最优值时,选取的特征子集能够最大限度保持原始数据分类能力,而且特征之间的冗余度最低,此时的特征提取向量即为最佳lbest。

式中:U为相似矩阵;
R=(lT,…,lT)为特征选取矩阵;
Φ=(FS1,FS2,…,FSN)T为特征矩阵;
ψ为相关性矩阵。
2)特征提取向量确定。采用IABC 对Ο(l) 优化过程进行求解,将l等效为蜜蜂编码X,IABC 目标函数选取为Ο(l)函数。

3)编码位调换进化。由于l编码是离散的,此时如果仍采用式(8)—式(10)更新公式进行更新,会产生大量不符合要求的解。为此,提出编码位调换学习进化策略。以向Xbest学习为例,将φ(Xbest-连续操作定义为编码位调换进化操作,即随机选取Xbest内K个编码位替代(如图3 所示。)

图3 编码位调换进化操作示意图Fig.3 Diagram of code bit exchange evolution operation
3.3 多核加权极限学习机
ELM 具有更快的运算效率,被广泛应用于预测领域。对于训练数据集合Sn={(xi,yi)},ELM 利用输入权值ω=(ω1,…,ωk)、连接权值β=(β1,…,βk)和偏置b=(b1,…,bk)定义预测输出值向量Y=[y′1y′2…y′n]T:

式中:H为输出矩阵。
训练过程中,X,Y已知,ω,β事先给定,根据式(20)可以得到β:

式中:H+为H的广义逆矩阵。
为提高ELM 预测的稳定性,引入训练误差e=(e1,…,en)和正则系数Q,并求解β最小范数:
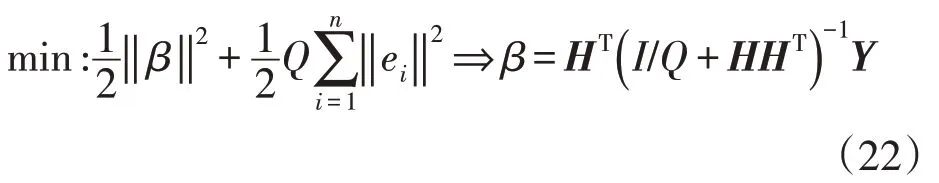
当H未知时,文献[25]提出了一种核极限学习机(KELM),即通过构造核矩阵ΩKELM替代HHT:

定义为K(xi,xj)=h(xi)h(xj)核函数,则有:

1)多核加权KELM 提升了对复杂数据的预测能力,但是一种核函数不可能对所有数据都具备良好的分析预测性能,为此引入多核加权极限学习机(Multiple Kernel Extreme Learning Machine,MKELM),即:

式中:Kz(x,x1) 为第z(1 ≤z≤Z,Z为核函数总个数)个核函数;
∂z为第z个核函数对应的加权值。
2)IABC 优化MKELM 参数。本文选取三阶多项式函数Kp(x,xn)、指数核函数Ke(x,xn)和高斯核函数KR(x,xn)为多核加权函数,式中Kp(x,xn),Ke(x,xn),KR(x,xn)分别涉及参数C0,σe,σR。此时采用IABC 对MKLEM 参数进行优化,定义蜜蜂编码X=(0,σe,σR,C∂1,∂2),目标函数定义为训练集均方根误差,即:
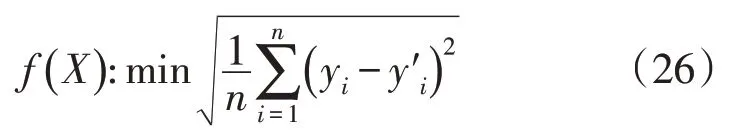
蜜蜂种群循环迭代进化,最终得到MKELM 最优参数组合。
采用MATLAB 平台对某地区短期电力负荷进行预测分析。每间隔1 h 采集8 月1 日至8 月31日以及12 月1 日至12 月31 日的电力负荷、环境因素等数据,其中前25 天数据作为训练样本集,后6 天为预测验证数据集以验证所提短期电力负荷预测的有效性(其中,8 月29 日、30 日,12 月28 日、29日为周末)。采用文献[9]提出的均方根误差RM与平均误差MA进行量化评估。最后采用本文提出的基于改进密度峰值聚类和多核加权极限学习机预测方法(IDPC-MKELM)对短期电力负荷进行预测。
4.1 有效性验证
以8 月27 日0:00-24:00 电力负荷预测为例,采用本文提出的短期电力负荷预测模型进行预测分析。表1 给出了样本最佳聚类个数C、特征提取数m、平均运算时间tˉ,RM和MA结果,选取基本ABC、改进的灰狼优化算法(Improved Grey Wolf Optimizer,IGWO[19]进行对比实验(对目标函数值无量纲化处理),图4 给出了某个分类对应的IABC 优化最优特征子集提取(目标函数取lg 值)、MKLEM参数收敛曲线。以最佳特征子集为基数,依次增加或减少选取特征数量,图5 给出了不同特征组合下RM,MA变化曲线(对RM,MA进行无量纲化处理),图6 给出了预测效果图。

图4 分类对应IABC收敛曲线Fig.4 IABC convergence curve corresponding to classification
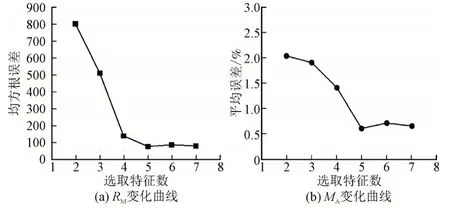
图5 不同特征组合下RM,MA 变化曲线Fig.5 RM,MA change curve under different feature combinations

图6 短期电力负荷预测效果图Fig.6 Effect drawing of short-term power load forecasting

表1 短期电力负荷预测结果Table 1 Short term power load forecasting results
从图4 可以看出,相比于其它2 种优化算法,IABC 算法具有更快的收敛速度和更高的收敛精度,因此能够给出更佳的参数优化结果,有利于提升预测效果;
从图5 可以看出,随着选取特征数的不断增加,预测精度在提高,但是,当特征选取数达到设定的最佳数值时,预测精度基本保持不变,这也表明,最优特征子集提取不仅保持了原始数据辨识能力,而且能够有效降低数据维度,减少数据处理复杂度;
从表1、图6 可以,本文预测模型的短期电力负荷预测曲线与真实值曲线拟合度很高,这也验证了所提短期电力负荷预测的有效性。
4.2 对比试验
为进一步验证所提IDPC-MKELM 的有效性,选取MKELM、卷积神经网络—双向长短期记忆网络(Convolutional Neural Networks-Bidirectional Long ShortTerm Memory,CNN-BiLSTM)[9]进行对比实验,表2 给出了8 月和12 月预测RM,MA对比结果,图7、图8 分别给出了8 月31 日和12 月28 日(周末)电力负荷预测曲线图。
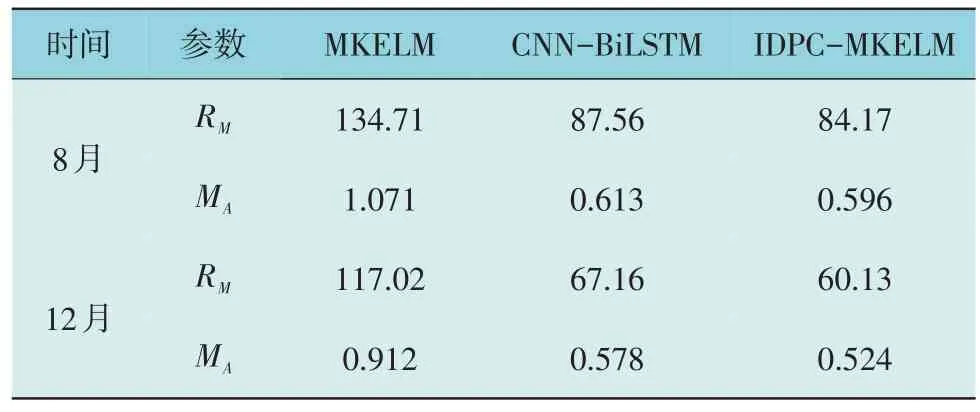
表2 不同算法短期电力负荷预测结果Table 2 Short term power load forecasting results with different algorithms
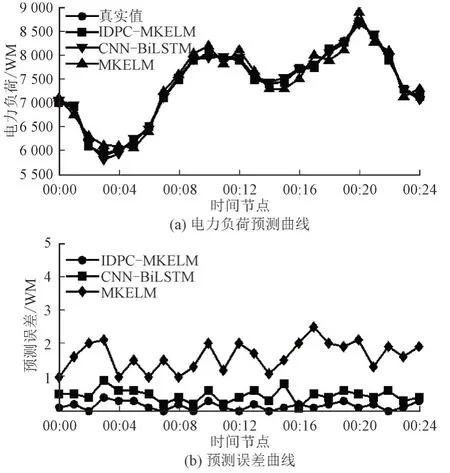
图7 8月31日短期电力负荷预测曲线Fig.7 Short term power load forecasting curve on August 31
从表2 可以看出,无论是对于8 月还是12 月电力负荷预测,IDPC-MKELM 的RM和MA表现最好,CNN-BiLSTM 次之,而MKELM 表现最差。相比于其它2 种预测算法,IDPC-MKELM 的RM降低了约3.5%~37.5%,MA降低了约8.8%~39.8%;
从图7和图8 可以看出,IDPC-MKELM 预测结果与原始数据曲线拟合度最高,而且能够以更小的误差给出工作日、非工作精确预测结果。对比实验仿真结果表明,利用改进密度峰值聚类对数据进行聚类分析,提升了预测的精细度和预测精度;
多核加权极限学习改进方式以及利用IABC 对参数进行全局优化,很大程度地改善了短期电力负荷预测精度,使所提的IDPC-MKELM 在短期电力负荷预测问题更具优越性。

图8 12月28日短期电力负荷预测曲线Fig.8 Short term power load forecasting curve on December 28
对短期电力系统负荷预测问题进行了研究,提出了基于密度峰值聚类、极限学习机和智能优化算法理论的的短期电力负荷预测方法。该方法从降低数据维度、提升预测效果出发,分别设计了改进DPC 聚类分析、最优特征子集提取、多核加权ELM和改进IABC 算法,并以某地区实测数据进行验证分析,仿真结果表明,所提方法能够很好地预测跟踪短期电力负荷变化。
猜你喜欢 子集学习机聚类 警惕平板学习机骗局保健与生活(2022年10期)2022-05-06高一上学年期末综合演练中学生数理化·高一版(2022年1期)2022-04-05K5;5; p 的点可区别的 IE-全染色(p ?2 028)华东师范大学学报(自然科学版)(2022年2期)2022-03-31基于数据降维与聚类的车联网数据分析应用汽车实用技术(2022年4期)2022-03-07“机”关文萃报·周五版(2021年30期)2021-09-05基于模糊聚类和支持向量回归的成绩预测华东师范大学学报(自然科学版)(2019年5期)2019-11-11基于密度的自适应搜索增量聚类法电子技术与软件工程(2016年23期)2017-03-06集合的运算数学教学通讯·初中版(2015年5期)2015-06-17从学习机到上网本微电脑世界(2009年3期)2009-04-03猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
