首页 > 心得体会 > 学习材料 / 正文
基于MI+PSO-LSTM的能耗预测模型
2023-02-03 11:05:16 ℃谌东海,王 伟,赵昊裔,明新淼
(1.长江勘测规划设计研究有限责任公司 城市规划与建筑设计院,湖北 武汉 430010;
2.武汉科技大学 机械自动化学院,湖北 武汉 430080)
随着科技产品的广泛应用,对电力的需求目前正在全球范围内逐渐增大,需要对电网进行控制[1]从而实现电力的可持续发展[2]。商业和住宅建筑占智能楼宇能耗总量的30%~40%[3]。所以对于家庭建筑和企业建筑[4],通过能耗的预测[5]提高能耗的使用效率[6],降低能耗[7]具有很大的现实意义。
鉴于此,研究人员开发了许多预测方法来改善电网质量并优化能源的使用[8]。能源消耗预测已经被许多先进的模型所研究,这些模型通常可以分为传统模型[9]和基于人工智能(AI)的模型[10]。目前研究人员常常将历史数据与AI算法[11]结合使用。比如,Jia等[12]针对大型商业建筑客户密度较高、随机性强的特点,采用多元线性反馈回归模型来精确预测空调能耗,该方法在能耗预测中具有好的仿真效果,但是特征的数量是不确定的,特征的选择是根据变量之间的显式条件进行选择的。Yang等[13]提出了一种利用递归神经网络(RNN)估算建筑能耗的方法,该方法只使用两层及以下的小型循环网络,没有深入探索两层以上的深层网络是否会在建筑能耗预测中表现更好的问题。Luo等[14]采用遗传算法GA确定LSTM架构的超参数包括LSTM层数、每个LSTM层中的神经元数、每个LSTM层的丢包率和网络学习率,使得LSTM的网络结构达到最优以提高其预测精度和鲁棒性。
在总结借鉴前人的研究,提出了MI+PSO-LSTM模型,首先在对数据进行预处理时,使用互信息法(MI)[15]对原始数据的特征进行选择,然后采用粒子群优化算法(PSO)[16]对长短时神经记忆网络(LSTM)[17]的网络结构进行寻优,以求得到最佳的网络拓扑结构,最后将某建筑的历史用电量作为时间序列进行短期单步1 h的用电量预测。
1.1 LSTM长短时神经记忆网络

遗忘门:根据xt和ht-1的大小控制上一单元状态Ct-1被遗忘的程度
ft=σ(Wf·[ht-1,xt]+bf)
(1)
输入门:根据xt和ht-1的大小控制哪些信息被加入到本单元Ct中
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
单元状态更新:根据ft将新信息有选择的记录到Ct中
(4)
输出门:将Ct激活,并控制Ct被过滤的程度
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot∘tanh(Ct)
(6)
σ(x)=1/(1+e-x)
(7)
tanh(x)=(ex-e-x)/(ex+e-x)
(8)
输出层依据式(9)将ht经过一个全连接层(dense)得到最终预测值yt
yt=σ(Wy·ht+by)
(9)
其中,Wy,by分别为权重矩阵和偏置项。
LSTM通过遗忘门,控制历史信息的传递,通过输入门决定当前信息的保留程度,然后将经过遗忘门的旧状态与经过输入门的新状态进行叠加,得到当前单元状态更新后的状态,将更新后的状态通过输出门输出。
1.2 MI互信息法
在对数据进行预处理时,其中原始数据的选择在一定程度上决定了模型的准确性。如果可以通过选择最有效和有用的输入来减少输入数据特征的数量,则预测模型会得到更好的增强。特征选择方法的方法包括相关性分析[18]和数值灵敏度分析[19]等,但是这些方法都是线性的输入选择方法,而能耗数据则是非线性的。因此,互信息特征选择方法将更加有效[20],此方法计算输入和输出数据相关性的效率是很高的[21]。
互信息(mutual information,MI),表示两个变量X与Y之间的相互依赖性。
X,Y之间的互信息I(X;Y) 定义为
(10)
其中,p(x,y) 是联合概率密度函数,p(x),p(y) 分别为x,y的边缘概率密度函数。MI是用来评价一个事件的出现对于另一个事件的出现所贡献的信息量[22]。MI互信息法通过计算所有特征与目标特征的互信息度量,然后进行排序,选取K个MI最高的特征,从而达到特征选择的目的。
LSTM是一种深度学习模型,可以有效地处理较长的时间序列并自动学习数据并挖掘更深层次的功能。但是与其它神经网络模型类似,LSTM神经网络模型中部分超参数的设置,往往依赖研究者的经验,这样的模型缺乏科学严谨性。为了使LSTM模型的预测效果达到最优,采用粒子群优化(PSO)算法对LSTM模型进行优化。PSO的优势在于简单容易实现,PSO解决方案提供了更快的收敛速度,并且没有许多参数需要调整。遗传算法和蚁群算法等不具备这种引导机制。
2.1 PSO粒子群优化算法
粒子群算法的基本思想:一群鸟在一定的区域内随机飞往某处搜索食物,所有的鸟仅知道自己与食物的距离和其它鸟的位置信息。每一只鸟在离开当前所在位置飞往其它位置时,会依赖于下列信息:目前离食物最近的鸟的周围区域、根据自己飞行的经验判断食物的所在。
PSO初始化的状态为一群随机生成的粒子。然后通过迭代改变粒子的位置从而找到最优解。在每一次的迭代中,粒子通过比较当前粒子与两个“极值”(局部最优解pbest,全局最优解gbest)来改变粒子的速度和位置,从而达到更新粒子的目的。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置
vi=vi+c1×rand()×(pbesti-xi)+c2×rand()×(gbesti-xi)
(11)
xi=xi+vi
(12)
其中,i=1,2,…,N,N是粒子群的粒子总数。vi为i粒子的当前速度;
rand()为介于(0,1)之间的随机数;
xi为i粒子的当前位置;
c1和c2为学习因子;
pbesti和gbesti分别是当前粒子群局部最优位置和全局最优位置。
2.2 LSTM的超参数
网络层数并不是越多越好,如果设计的浅层(3层到5层)网络没有学习任何特征,那么设计的超深(如100层)网络也会没有效果,甚至更加糟糕。隐藏单元太多或者太少,都会导致网络难以训练。LSTM隐藏层神经元个数units是非常重要的,若units过小,LSTM网络性能会很差甚至LSTM可能根本不能训练。增加units的大小在降低模型预测的误差的同时,也会增加网络的复杂度,从而增加网络的训练时间。若units过大,会导致网络缓慢、难以训练,残留噪声难以消除,从而导致LSTM训练容易陷入局部极小值点甚至出现“过拟合”。
权重正则化可以减少LSTM“过拟合”训练的风险。当dropout很小时,惩罚项值不大,还是会出现过拟合现象,当dropout的值逐渐调大时,会逐渐抑制过拟合现象的发生,但是当dropout的值超过一个阈值时,就会出现欠拟合现象,因为其惩罚项太大,导致丢失太多的特征。dropout选择合适的大小,权重衰减会抑制静态噪声对目标的某些影响。所以选择的dropout值至关重要。
除了上述两个参数对LSTM模型影响很大之外,批处理大小batchsize的选择不可或缺。批处理大小为batchsize意味着在更新模型权重之前,将使用训练数据集中的batchsize个样本来估计误差梯度。小批量通常会导致快速学习,但学习过程不稳定,并且分类精度差异较大。较大的批次大小会减慢学习过程。若LSTM网络中存在批归一化,batchsize过小则更难以收敛,甚至垮掉。这是因为数据样本越少,统计量越不具有代表性,噪声也相应的增加。而过大的batchsize,会使得梯度方向基本稳定,容易陷入局部最优解,降低精度。
所以将units、dropout、batchsize作为LSTM的超参数优化目标,使用PSO算法得到最优解,使得LSTM模型在短期能耗预测中达到最优的预测精度。
2.3 MI+PSO-LSTM模型结构
用电量作为时间序列,其具有复杂的不确定性。为了准确地预测建筑的用电量,将在时间序列分析预测中有良好表现的LSTM模型作为基础模型,构建建筑用电量预测模型。由于时间序列的复杂性,如果分析的特性不足,会无法达到预期的预测效果,但如果分析所有特征,毫无疑问将会大幅度提升模型搭建的难度和模型的运行时间,造成模型性能大幅度下降。MI互信息法能尽可能地保留有用的信息,在保证模型预测精度的同时能减少模型搭建的复杂度。PSO优化算法能够科学处理全局优化问题,有效地解决LSTM因参数设置不当导致模型效果不佳的问题。
基于MI互信息法和PSO优化算法与LSTM结合,提出了一种建筑能耗短期预测组合模型MI+PSO-LSTM,模型结构如图2所示。
组合模型算法流程如下:
步骤1 对原始数据进行预处理,然后进行平滑处理形成480个特征分量。
步骤2 计算步骤1中480个特征分量与预测分量的MI值,选取MI权重前60个的特征分量构成新的数据集。
步骤3 将步骤2中80%的数据集作为训练集,剩下的数据作为测试集。
步骤4 初始化相关参数,设置以下参数的范围,units∈[20,300],dropout∈[0,1],batchsize∈[20,300]。
步骤5 在初始范围内,对粒子群(20个粒子)随机初始化,根据fitness function(LSTM模型拟合结果),计算每个粒子的适应值(平均绝对误差MAE),根据当前每个粒子的MAE确定这次迭代的粒子群的最优位置(pbest)以及历史粒子种群的最佳方位(gbest)。
步骤6 根据最优粒子的位置和速度以及式(11)和式(12),对当前粒子的位置和速度进行更新,将更新后的粒子通过LSTM模型拟合后,计算每个粒子的MAE,根据MAE更新pbest和gbest;
步骤7 当最优粒子的适应度值不再变化或者迭代次数达到上限值即认为此时算法已经达到收敛;
若粒子未收敛,则返回步骤3。
步骤8 将得到的最优粒子参数代入到LSTM模型中,对步骤3中的数据进行预测分析,得到最终的结果。
3.1 实验数据集
实验所用数据集为某建筑2019年10月15日至2019年6月4日的用电量,该数据集一共20个特征。这些特征的描述见表1。

表1 数据集说明
本文使用前24小时的数据预测下一小时Gi的值,故使用滑动窗口将24小时的20个特征的数据形成480个特征分量。然后使用MI互信息法选择使用滑动窗口法形成的480个特征分量中MI值最大的前60维特征。选择结果见表2。
其中,选择的特征例如Gi(t-1) 表示,以当前时间为基准前一小时从工业厂房公共电网中输入。MI值为当前特征分量X与以当前时间为基准的Gi分量(即I(X;Gi(t)) 的互信息值大小。由表2可知前4小时的大部分特征与当前时刻的Gi特征的互信息值较大,Gi、Ao、Co、A2前24个小时的特征与当前时刻的Gi特征的互信息值也相对较大。MI减少了87.5%的多余特征,对提高模型算法效率起到了很好的作用。
3.2 评价指标
使用4种评价指标来评判模型的好坏程度。
均方根误差:RMSE,数值越小,表示模型拟合效果越好
(13)
平均绝对误差:MAE,数值越小,表示模型拟合效果越好
(14)
对称平均绝对百分比误差:SMAPE,数值越小,表示模型拟合效果越好
(15)
可决系数:R2,数值越大,表示模型拟合效果越好
(16)
3.3 模型参数设置
为了验证提出MI+PSO-LSTM组合模型的预测效果,本节采用表3中的两组5个实验模型做实验对比,模型的主要参数见表4、表5。
3.4 模型实验数据分析
3.4.1 基础模型实验结果分析
本节表3的基础模型M1~M3,通过特征1~20对公共电网输入总电量Gi,进行单步预测实验对比。
实验对比结果(表6)中,从可决系数、均方根误差、对称平均绝对百分比误差这3个模型预测评价指标中均可看出LSTM模型预测结果最好。
ARMA、K近邻和LSTM预测1 h用电量的预测结果与真实值的比对如图3和图4所示。由图3和图4可以看出LSTM模型预测的趋势与真实值最接近,且仅有LSTM

表2 MI选择的特征
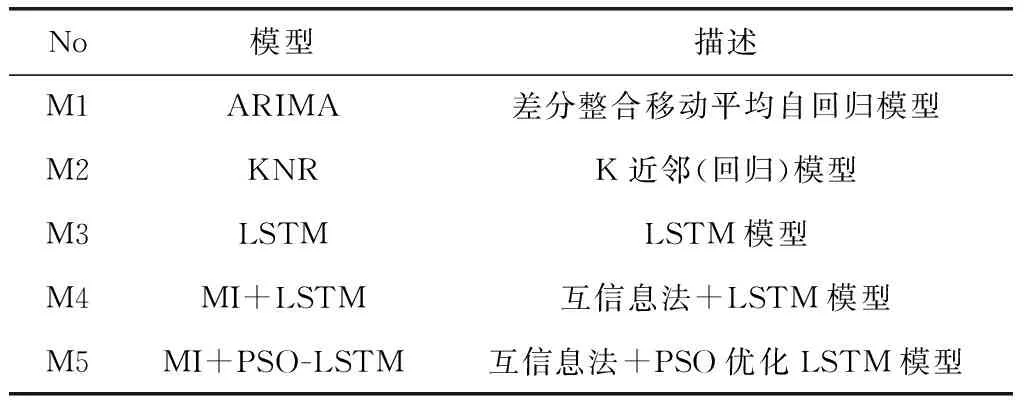
表3 实验对比基准模型

表4 对比模型主要参数1

表5 对比模型主要参数2

表6 基础模型实验对比
模型在原始值的置信区间里。ARIMA与K近邻模型预测的结果曲线既不在真实值的置信区间内,又存在预测滞后问题。综上对比于ARMA、K近邻回归模型,LSTM模型的预测效果是最佳的。所以选择LSTM作为实验基础模型。
3.4.2 LSTM组合模型实验结果分析
本节采用表3的组合模型M3~M5,通过特征1~20对公共电网输入总电量Gi,进行了20组单步预测对比实验。
3种模型预测1 h用电量Gi的预测结果与真实值的比对如图5和图6所示。由图5和图6可以看出3个模型的预测值基本处于真实值的置信区间内,而且MI+PSO-LSTM模型预测的趋势与真实值最接近。从图7可以看出,MI+PSO-LSTM模型的各项评价指标均为最优。
表7给出了3种组合模型20组实验结果的平均值,前4列为预测模型的4种评价指标,第五列为预测模型的训练时间。从表7中可以看出,对比于LSTM和MI+LSTM模型,MI+PSO-LSTM模型在R2上提高并不明显,但是在MAE、SMAPE上性能分别提高了20%和10%左右。对比于LSTM模型,MI+LSTM的性能并没有显著提升,但是通过MI选择特征之后,输入数据的维数减少了87.5%,使模型训练时间减少了约63%。

表7 组合模型评价指标对比
图7是M3~M5的20组实验4项评价指标的箱线图。图中不在箱子形状内的“+”符号为异常值(可以忽略不计)。从图7中可以看出,MI+PSO-LSTM模型的4项评价指标明显优于其它两种模型,且MI+PSO-LSTM模型每次的MAE和SMAPE均优于其它模型的所有结果,而MI+PSO-LSTM模型每次的R2和RMSE也有95%左右的数据优于其它模型。而MI+LSTM的4项评价指标与LSTM虽然有部分重合,但是MI+LSTM总体趋势上是优于LSTM模型的。从图7中可以看出,对比于LSTM模型与MI+LSTM模型,MI+PSO-LSTM模型的箱线图形状(上下四分位数差值)最小,这说明MI+PSO-LSTM模型比其它模型更为稳定。
综上所述,MI+PSO-LSTM模型所有评价指标均为最优。
本文提出了一种基于MI、PSO、LSTM的短期能耗组合预测模型。首先,在数据预处理阶段,使用互信息法对原始数据进行特征选择,删除冗余特征。然后使用PSO对LSTM的网络架构进行匹配化寻优,使得LSTM的拓扑结构与当前输入数据适配性达到最好,最后将特征选择后的数据输入到优化好的LSTM中,对能耗数据进行短期预测。为了验证MI+PSO-LSTM模型在短期能耗预测上的效果,对某建筑的能耗时间序列数据集进行了多维单步预测对比实验。综合上述实验的结果表明,MI+PSO-LSTM组合模型的4种评价指标均为最优,即说明MI+PSO-LSTM模型具有更高的预测精度和鲁棒性以及更为稳定的预测性能。MI+PSO-LSTM组合模型可以为利用深度学习探索时间序列的预测分析方面提供一个有益的研究思路。然而,MI+PSO-LSTM组合模型仍有很大的优化空间,例如研究时间序列的噪声过滤问题和特征动态智能选择问题,从而进一步优化模型预测精度。
猜你喜欢 互信息能耗粒子 120t转炉降低工序能耗生产实践昆钢科技(2022年2期)2022-07-08碘-125粒子调控微小RNA-193b-5p抑制胃癌的增殖和侵袭昆明医科大学学报(2022年1期)2022-02-28能耗双控下,涨价潮再度来袭!当代水产(2021年10期)2022-01-12探讨如何设计零能耗住宅建材发展导向(2021年23期)2021-03-08混沌粒子群算法在PMSM自抗扰控制中的优化研究防爆电机(2020年5期)2020-12-14基于膜计算粒子群优化的FastSLAM算法改进新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25日本先进的“零能耗住宅”华人时刊(2018年15期)2018-11-10基于改进互信息和邻接熵的微博新词发现方法计算机应用(2016年10期)2017-05-12基于互信息和小波变换的图像配准的研究电脑知识与技术(2016年25期)2016-11-16基于互信息的图像分割算法研究与设计电脑知识与技术(2016年1期)2016-03-22猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
