首页 > 心得体会 > 学习材料 / 正文
基于深度监督学习的零样本跨模态检索方法
2023-02-06 09:15:08 ℃曾素佳,庞善民,郝问裕
(西安交通大学电子与信息学部,710049,西安)
以图像来检索与视觉特征最相关的文本,或者以文本来检索与语义最相关的图像,称为图像-文本的跨模态检索。图像-文本跨模态检索是信息检索领域新的重要发展方向,也为实现图像、文本、音频和视频等多模态检索提供了研究基础[1-2]。传统的图像-文本检索以典型相关分析为主要方法,随着深度学习的发展,出现了基于哈希[3-4]、余弦相似度[5-7]等相关性度量的深度神经网络建模方法,并逐渐成为图像-文本检索研究的主流[1-2]。随着零样本学习[8-9]的兴起,出现了图文跨模态检索与零样本学习相结合的应用场景,即零样本的图文跨模态检索[10-11]。
零样本的图文跨模态检索关键在于保持图像的视觉特征和文本的语义特征之间的类别匹配和对应匹配关系,检索的质量受限于深度特征提取的方法,以及类别相关的图文特征之间的关联学习。当前的研究[12-15]大多依赖于从深度预训练的词向量,例如Word2Vec、BERT[16]等中获得一个较好的文本语义初始化表示,缺乏对文本本身语义显著性的理解。此外,训练阶段的模型也只约束了图文数据对间的类别关系,而没有区分过同一类别并且匹配的另一模态数据、同一类别但不匹配的另一模态数据,以及类别不同的另一模态数据。
本文选取文献[12]的研究作为基线模型,提出一种基于深度监督学习的零样本图文跨模态检索方法,在保持类别匹配的同时又兼顾图文的对应匹配关系。在以KL散度(Kullback-Leibler divergence)约束图文数据类别间的匹配关系时,也采用掩码的方式,从两种不同的角度构造了新的图文对应匹配约束条件;同时,采用两种分类网络进一步实现视觉空间和语义空间结构的对齐,并在深度特征的嵌入学习中引入自注意力机制,有效提升了零样本图文跨模态检索性能。
文献[8]最早将零样本学习的原理引入图像-文本跨模态检索,在训练集图文数据的类别和测试集图文数据的类别不相交的条件下,建立自然语言描述和视觉特征之间的细粒度联系,并对研究动机进行了阐述:在零样本学习中,由于测试集图像的类别未在模型训练过程中出现过(称为未见类别),测试图像通常要借助专家标注的属性向量作为语义辅助信息进行类别的区分。尽管具有较高的准确率,但是属性向量标注的成本也较高,标注者也需要具备相关专业知识,耗费大量人力、财力和时间。自然语言则提供了一种更灵活和紧凑的方式,通过描述显著的视觉特征就能区分出图像类别。因此,该文献收集了Caltech-UCSD Birds-200-2011(CUB)和Oxford Flowers-102(FLO)两个数据集图像的细粒度文本描述,提出通过一个零样本的图文跨模态检索任务,从细粒度的自然语言中训练得到语义辅助信息,来克服属性向量存在的局限性。此后,CUB和FLO被普遍作为评估图文跨模态检索方法在零样本学习方向上的性能表现公共数据集,文献[12-15]均在其上进行方法验证。
文献[12]提出跨模态的投影学习,采用KL散度来度量图文数据分布的跨模态相关性,避免了三元组形式的损失函数[17]需要人为选定合适边界值的不足,检索效果也超过了三元组损失。文献[13]以BERT预训练的词向量初始化词序列,以ResNet-101为图像的视觉特征提取网络,在文献[12]的研究基础上,采用生成对抗网络的训练方式消除视觉特征和语义特征间的异质性,进一步改进了零样本图文跨模态检索的性能。文献[14]基于BERT提出多级文本(包括句子、短语和单词)语义学习网络,同时利用耿贝尔注意力(Gumbel attention)强化这些多级语义和图像区域视觉特征之间的联系。文献[15]则利用图注意力关系网络建模单词之间的语义关系,再与图像整体和区域的视觉特征分别进行匹配学习。
在类别相关的零样本图文跨模态检索研究中,通常存在3种类型的图文数据对,分别为来自同一类别并且匹配的数据对、来自同一类别但不匹配的数据对以及来自不同类别的数据对。然而,相关研究或者将前两者都视为正样本对,或者将后两者都视为负样本对,都会给图像和文本之间的细粒度匹配带来误差,如图1所示。
由图1(a)可知,尽管前两对图像和文本都来自“Brewer Sparrow”类,但是从第1张图像中几乎看不到第2个文本描述中的“黑色条纹”特征;同样,对于第2张图像,第1个文本描述中的“弯曲的脚”视觉特征也不明显,可知每张图像的视觉特征只与其对应的文本描述最相关,而不一定与同一类别的其他图像的文本描述相关。因此,仅以类别关系作为图像-文本跨模态样本对之间的匹配关系是片面的、不够准确的。
如果将每一个图文数据对视为一个单独的类别,例如文献[18],虽然能够保持跨模态数据间的对应匹配关系,但是却丢失了有用的类别监督信息。如图1(b)所示,虽然第1张图像和第2张图像中的花卉来自同一类别,具有相似的形态特点,只是颜色不同,但是如果没有类别信息作为监督,神经网络便无法学到形态才是区分“class_00087”类花卉的主要特征,而颜色是次要特征。在文本检索图像时,同一类别的图像便不能排到检索结果中靠前的位置,而这是检索排序中不期待出现的情况,因为理想的排序结果是类内的图像总是排在其他类别图像的前面。因此,基于实例的匹配也是不完美的,对于类别相关的零样本图文跨模态检索任务中,既要保证图文的对应匹配关系,又要保持图文间的类别匹配关系。
本文训练阶段的方法框架如图2所示,从左到右主要包括3个模块。
(1)最左侧为基于注意力的特征学习模块,文本和图像分别通过一个深度神经网络提取其深度嵌入特征;采用注意力的方式使获得的语义特征和视觉特征信号表达更加显著;以1×1的卷积网络将两者变换到同一维度的公共空间中进行度量学习。
(2)中间为分类网络学习模块,设计了语义特征分类网络和视觉特征分类网络,分别用于对语义特征和视觉特征进行分类,输出两种特征的类别分布信息,再共享两者的分布信息。对于成对的图像和文本,在这一模块中既能对齐类别分布信息,又能保持对应匹配关系。
(3)最右侧为深度跨模态特征匹配学习模块,利用视觉特征和语义特征计算得到图像和文本间跨模态的匹配概率分布,用于约束跨模态的图文数据对之间的类别关系和对应匹配关系。其中,浅紫色的色块表示同一类别并且匹配的跨模态数据对之间的匹配概率,浅红色的色块表示同一类别但不匹配的跨模态数据对之间的匹配概率,浅灰色的色块表示类别不同的跨模态数据对之间的匹配概率。
2.1 基于注意力的特征学习模块
对于数据集中的文本描述,采用随机初始化的方式,获得其低维词向量序列表示,接着双向长短时记忆网络(bi-directional long short term memory network,Bi-LSTM)被用于学习这些初始化词向量序列的深度语义嵌入。不同于先前的研究需要人为选定平均池化或最大池化的方式来将单词序列特征转换为句子的语义特征,本文提出以自注意力池化[19]的方式将Bi-LSTM网络输出的词序列隐藏状态转换为句子的语义特征,表达式如下
ai=softmax(Wouttanh(Whidhi+bhid)+bout)
(1)
(2)
式中:hi为第i个单词的隐藏状态特征;ai为hi的注意力向量;Whid、Wout分别为线性变换层的权重向量;bhid、bout为线性变换层的偏置量;t为句子的语义特征;l为每个句子的单词数;∘为哈达玛积操作。
对于数据集中的图像,采用深度预训练神经网络提取图像的深度视觉特征V,并且对称地采用自注意力的方式使重要的视觉特征更加显著。
为了在同一公共空间对视觉特征和语义特征进行度量学习,训练过程中采用一个1×1的卷积网络分别将视觉特征和语义特征变换到相同维度的空间中,获得视觉特征V=[v1,v2,…,vN]∈RN×d和语义特征T=[t1,t2,…,tM]∈RM×d。其中,d为公共空间的维度,N和M分别为图像数和文本数。
2.2 分类网络学习模块
视觉特征来源于二维图像数据,而语义特征来源于文本序列,两者分别从不同的深度特征嵌入网络中获得,因此两者在公共空间中的流形结构具有差异,给跨模态的匹配带来了困难。为了对齐视觉空间和语义空间的结构,视觉特征分类网络和语义特征分类网络分别被用于学习两种特征在各自空间中的类别分布信息,同时,通过共享两者的类别分布信息,实现视觉空间和语义空间结构的对齐。
视觉特征分类网络和语义特征分类网络均由两层全连接神经网络构成,对于视觉特征及其对应匹配的语义特征,分类网络计算其类别分布的数学表达式如下
(3)
(4)
对于分类网络输出的类别分布,在类别标签的监督下,采用均方差损失函数计算网络的预测损失,将视觉特征和语义特征分类网络的预测损失分别记为LV和LT,具体计算公式如下
(5)
(6)
式中:n为每次迭代的样本批量大小;yi∈R1×K为第i个样本的类别标签,为独热编码的形式。
此外,本文也通过计算对应匹配的视觉特征和语义特征之间的类别分布差异来实现两者的类别信息共享和空间结构对齐,因为当任意一个视觉特征及其对应的语义特征在各自空间中的类别分布状态相同时,视觉空间和语义空间应具有相同的结构,如下式所示
(7)
式中:|·|为绝对值误差损失函数。
2.3 深度跨模态特征匹配学习模块
零样本的图文跨模态检索是类别相关的检索任务,因此,在训练过程中,对于某一批次的采样,视觉特征可能遇到3种不同类型的语义信息,分别为与其对应匹配的语义特征、与其属于同一类别但不匹配的语义特征以及与其属于不同类别的语义特征,对于文本的语义特征亦是如此。
为了度量图文数据之间的类别匹配关系,受启发于文献[12]的跨模态投影学习,本文将视觉特征vi匹配到来自同一类别的语义特征都视为等概率事件,并将该类事件的概率总和记为1,而将vi匹配到来自不同类别的语义特征的事件概率均记为0,对于文本的语义特征亦是如此,获得类别匹配约束下的概率分布,如图3所示。
同时,计算视觉特征和语义特征分别在各自空间中的匹配概率,表达式如下
(8)
(9)
式中:q(vi|tj)为视觉特征vi在语义空间中的投影,作为与tj之间的匹配概率;q(ti|vj)为语义特征ti在视觉空间中的投影,作为与vj之间的匹配概率。
再以反向KL散度计算训练的模型对图3中数据分布的拟合误差LC,表达式如下
(10)
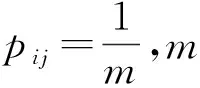
为了度量图文数据间的对应匹配关系,不同于文献[18]将每一张图像(或文本描述)视为一个单独的类别,本文利用两种掩码的方式,在保持数据集中原始类别关系的同时,也保持视觉特征和语义特征间的对应匹配关系,两种掩码隐藏方式(以灰色点线箭头表示)如图4所示。
在图4(a)中,若vi和tj(或ti和vj)来自同一类别但不匹配,则将模型预测的概率值q(vi|tj)(或q(ti|vj))替换为负无穷,以避免经过softmax函数变换后,再经过自然对数函数变换时真数为0,分别记为qs(vi|tj)(或qs(ti|vj))。同时,也将该概率值对应的标签pij替换为0,相当于不使用vi和ti之间的概率匹配信息更新神经网络的参数,以避免同类跨模态样本对约束类别匹配关系产生不利影响。在隐藏了同一类别但不匹配的图文数据之间的匹配概率后,以交叉熵损失函数构造该隐藏条件下的匹配约束条件LS,如下式所示
(11)
式中:qs为隐藏同一类别但不匹配的图文数据之后的跨模态匹配概率;xij为vi和tj是否来自同一类别的标签,若vi和tj来自同一类别,则xij=1,否则xij=0。
在图4(b)中,若vi和tj(或ti和vj)来自不同类别,则将模型预测的概率值q(vi|tj)(或q(ti|vj))替换为负无穷,以避免经过softmax变换后,再经过自然对数函数变换时真数为0,记为qu(vi|tj)(或qu(ti|vj))。同时,将该概率值对应的标签pij替换为0,相当于其他类别的数据不参与神经网络的参数更新,只对来自同一类别的跨模态数据按照是否对应匹配进行二元分类。由于隐藏了其他类别的另一模态样本,在这种方式下能够学到同一类别内跨模态样本之间的区分性。同样地,以交叉熵损失函数构造该隐藏条件下的匹配约束条件LU,如下式所示
(12)
式中:qu为隐藏其他类别的图文数据之后的跨模态匹配概率;yij为vi和tj是否对应匹配的标签,若vi和tj对应匹配,则yij=1,否则yij=0。
在式(11)和式(12)中,本文将掩码处理后的匹配概率均进行了一次softmax变换,以获得未隐藏的跨模态样本之间新的归一化的匹配概率。
综上,通过基于注意力的特征学习模块、分类网络学习模块以及深度跨模态特征匹配学习模块的工作后,得出训练阶段两种优化的目标函数。
方法1优化L1,基于隐藏同一类别但不匹配的另一模态数据约束匹配关系,如下式所示
L1=LS+α1LC+α2LD+α3LT+α4LV
(13)
式中:α1、α2、α3和α4为各项约束条件的权重系数。
方法2优化L2,基于隐藏类别不同的另一模态数据约束匹配关系,如下式所示
L2=LU+β1LC+β2LD+β3LT+β4LV
(14)
式中:β1、β2、β3和β4为各项约束条件的权重系数。
在测试阶段,语义特征由测试集全部的文本描述依次通过训练阶段保存的文本处理模块得到,并且按类别取平均作为文本类语义;视觉特征由图像依次通过ResNet-101[20]网络,以及训练阶段保存的图像处理模块得到。接着,计算得到测试图像的视觉特征和文本类语义特征之间的余弦相似度,作为测试阶段检索排序的依据,如图5所示。
3.1 数据集与参数设置
CUB、FLO、Flickr30k[21]和Microsoft COCO[22]均为图文跨模态检索常用的公共数据集。其中,CUB数据集含有200种鸟类的图像,共11 788张;FLO数据集共有102种花卉的8 089张图像。此外,CUB数据集的每一类图像也具有312个专家系统标注的属性向量,可作为图像分类时的语义原型。文献[8]利用Amazon Mechanical Turk(AMT)众包平台收集了这两个数据集每一张图像的10个细粒度的句子描述,这些句子只描述视觉外观信息,不含比喻,不含命名,也不包括背景、地名等信息。与相关研究[8,12-15,23-25]一致,本文采用这两个数据集公开的零样本划分方式。对于CUB数据集,训练集共有150个类别的8 821张图像和88 210个文本描述;测试集共有50个类别的2 967张图像和29 670个文本描述;对于FLO数据集,训练集含有7 034张图像和70 340个文本描述,共82种花卉;测试集含有1 155张图像和11 550个文本描述,共20种花卉,训练集数据的类别和测试集数据的类别是不相交的。
Flickr30k数据集包含30 000多张图像以及每张图像对应的5个句子描述,而Microsoft COCO数据集含有的图像更多,共123 287张,两者都是复杂生活场景图像,对一张图像通常不只用一个类别标签来标注。然而,零样本学习的设定中单个图像只对应一个类别标签,所以这两个数据集不太适合零样本学习相关的任务,况且当前训练集和测试集这两个数据集的数据类别也有重叠,也不符合零样本学习数据集的划分方式。相比而言,CUB和FLO数据集更适合本文进行方法验证。
使用PyTorch搭建模型框架,在NVIDIA GEFORCE GTX 2080 GPU服务器上进行训练,使用Adam优化器,初始学习率为2×10-4,在迭代30 000次和80 000次后分别将学习率调整为2×10-5和2×10-6;权值衰减系数设置为4×10-4;每次迭代的批量大小为64;训练阶段迭代总次数为200 000。实验中,式(13)中的超参数设置为α1=1.0,α2=1.0,α3=1.0,α4=1.0;式(14)中的超参数设置为β1=1.0,β2=1.0,β3=1.0,β4=1.0。
对于图像,采用预训练的ResNet-101网络提取全局平均池化后的2 048维深度视觉表征,再使用一层1×1的卷积将视觉特征变换到512维;对于文本,将每个句子的单词数截取或填充(补零)到30,采用随机初始化的方式,获得单词的512维随机向量,再通过Bi-LSTM获得1 024维的深度语义表征,同样地,使用一层1×1的卷积将语义特征变换到512维。使用注意力机制时,将注意力层用在1×1卷积层之前。
3.2 评价指标
在测试阶段,与相关研究[8,12-15,23-25]在这两个数据集上的处理方式一样,将所有测试类别文本的语义特征按类别取平均,作为参与检索的文本类语义。对于图像检索文本,采用召回率(R@1)作为评价指标,即对于某一张图像,计算检索到的排名第一的文本类语义与之属于相同类别的比例;对文本检索图像,采用准确率(P@50)作为评价指标,即对于某一个文本类语义,计算检索到的前50个图像中与之属于同一类别的比例。
3.3 实验结果
本文方法在CUB和FLO数据集上进行验证,并且与近年来相关的零样本图文本检索方法[8,12-15,23-25]进行比较,对图像检索文本以及文本检索图像的评估结果如表1所示。

表1 在CUB和FLO数据集上图像检索文本的召回率以及文本检索图像的准确率结果比较
由表1可知,在CUB数据集上,本文方法在图像检索文本上的召回率取得了最佳表现,其中,方法1和方法2的召回率分别高于基线模型CMPM+CMPC[12]5.5%和5.9%。对于文本检索图像,和基线模型CMPM+CMPC[12]相比,方法1和方法2的准确率分别提升了1.8%和2.2%,但是比现阶段表现最佳的HGAN[14]效果略低,分别相差2.0%和1.6%。
在FLO数据集上,本文提出的方法1和方法2在图像检索文本和文本检索图像上都取得了最佳表现。其中,方法1的召回率和准确率比CMPM+CMPC[12]提高了7.7%和7.1%,同时也高于HGAN[14]4.2%和1.7%。实验证明,在含有类别信息的细粒度数据集上,本文提出的方法有效提升了图像-文本跨模态检索的效果。
此外,与基于属性向量的类语义相比,如表1中Attributes[24],从自然语言描述中得到的类语义特征具有远高于其的识别效率。采用专家系统标注数据集的属性向量往往耗费大量人力、财力和时间,而自然语言的获取则容易得多,同样是在零样本学习的方式[8,12-15,23-25]下,本文对于从自然语言中学习零样本的图像分类也具有参考意义。
本文方法1和方法2的区别主要在于掩码隐藏的方式不同。由于保留了不同类别间的关系,方法1中的掩码匹配损失LS也能够在本文任务中单独使用。方法2中的掩码匹配损失LU不能在本文任务中单独使用,因为LU只用于对比类内的图文匹配关系,不能对不同类别的跨模态样本进行比较。
由表1可知,方法2在CUB数据集上的检索效果略高于方法1,而方法2在FLO数据集上的检索效果略低于方法1,也反映出两个数据集本身的特性。同一种鸟类的图像可能因为图像的拍摄角度、背景等不同,而形成视觉特征上的干扰差异。同一种花卉图像的差别可能不仅来自图像的拍摄角度、背景等,还可能来自颜色、形态等因素。因此,FLO数据集类内的方差更大,在本文任务中其类别间的比较更加重要,因此方法1对FLO数据集上的检索更有利;而CUB数据集图像的粒度更细,方法2可以对类内的匹配关系进行比较,所以方法2对CUB数据集上的检索更有利。
3.4 消融分析
为了探究注意力机制、分类网络,以及基于掩码匹配的约束条件对检索效果的影响,本文对方法1和方法2分别进行了消融实验,如表2和表3所示。
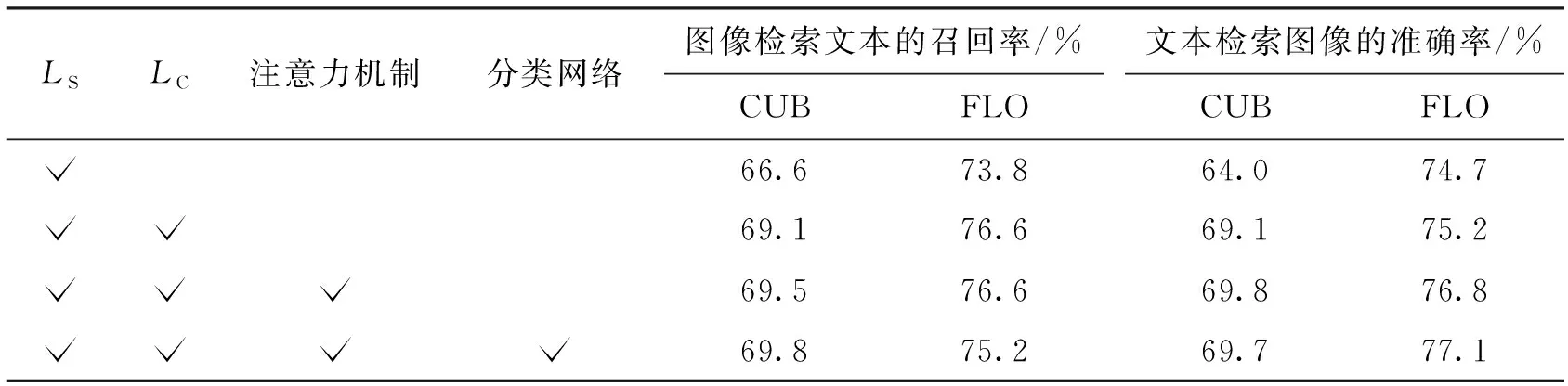
表2 本文方法1的消融实验结果

表3 本文方法2的消融实验结果
其中,未使用注意力机制时,对词序列的深度特征使用全局平均池化生成句子的语义特征;分类网络包括使用LD、LT和LV3种约束条件;使用LU时,由于隐藏了其他类别的跨模态数据,只能约束同一类别内的跨模态数据,因此不能单独使用,只给出与LC共同使用时的结果。
由表2可知,LS单独使用时,在CUB数据集上,图像检索文本的结果高于CMPM[12]4.5%,而文本检索图像的结果仅低0.6%;在FLO数据集上,两个方向上的检索表现都超过了基线模型CMPM+CMPC[12]。LS和文献[18]相似,都是将一个样本视为单独的一个类;不同的是,LS只是不使用来自同一类别但不匹配的另一模态样本的信息,而不是像文献[18]那样将其视为负样本。因此,LS保留了真实的类别信息,保证了某一批次样本中只有一个正样本,即使单独使用也能发挥作用,而基于实例的损失由于破坏了真实的类别关系,单独使用时对测试任务几乎不起作用。
LS和LC共同使用时进一步提升了在两个数据集上的图像-文本检索效果。其中,在CUB数据集上,图像检索文本和文本检索图像比单独使用LS分别提高了2.5%和5.1%,在FLO数据集上分别提高了2.8%和0.5%。使用注意力机制后,均能改进在两个数据集上的检索表现,证明了使用注意力的有效性。加入分类网络后,在CUB数据集上对图像检索文本的效果有0.3%的提高;而FLO数据集上的结果显示,分类网络更有利于文本检索图像的任务。
由表3可知,未使用注意力机制时,LU+LC在CUB数据集上两个方向的检索结果略胜过LS+LC(表2),分别高了0.4%(召回率)和0.5%(准确率);加入注意力后,与之相比仍高了0.7%(召回率)和0.2%(准确率)。在FLO数据集上,使用注意力机制和分类网络均能进一步改进LU+LC的检索效果;当同时使用注意力机制和分类网络时,达到了方法2在FLO数据集上的最佳表现。
3.5 定性分析
利用训练过程中保存的文本和图像处理模块分别获得测试集中图像的视觉特征和文本的类语义特征,并根据两者间的余弦相似度大小对检索结果从左到右排序,错误结果以红框标记,进行定性分析。由于在测试阶段对句子特征按类别取平均处理作为类语义特征,因此,当图像检索文本时,也相当于零样本的图像分类。本文对文本检索图像的排序结果进行可视化,如图6所示。
由图6(a)可知,在CUB数据集上,由于拍摄角度不同,有些图像不能体现鸟类的主要识别特征,同时,背景中其他物体的颜色、形态等也会形成干扰,从而导致错误的排序。例如第2行第3张图像的视角中,也可以看到“麻雀形状”“白色的喉颈”“黄色的”等视觉特征,因此被误认为属于相关实例。
当图像能全面体现鸟类的主要特征,并且背景干扰较小时,返回的排序结果就比较可靠,例如:第1行的图像,“深棕色斑点”的特征都比较明显;第3行的图像,视觉外观上都体现了“黑色的头”“黑色的颈”“黑色覆盖其身体的其余部分”,背景环境中也没有和鸟类特征相似的干扰信息。
由图6(b)可知,对于FLO数据集,第1行第3张图像被误认为有很高的相关度,可能与其同样具有“尖尖末端”的花瓣形态,以及图像背景中有大量的与“长长的绿色和橙色萼片”相似的视觉干扰信息有关。第2行的第3张图像中的花由于具有类似于“粉红色和黄色斑点”的外观特征,也被误认为属于相关实例,但是在形态上它与真实类别的花卉相差较大。与之相反,第3行的第2张图像,由于图中的花整体形态与该类别的花卉非常相似,而被排名为响应第二的检索结果,说明花卉形态可能是区分该类别的重要特征,而网络在训练过程中对颜色的影响关注较小。
根据图6的分析可以得出,为了提高图文跨模态检索的性能,可以进一步解决主要特征和次要特征判定不清、判断规则具有片面性等问题,以及抵抗背景信息的干扰等。
本文提出一种基于深度监督学习的零样本跨模态检索方法。首先,注意力机制被用于优化语义特征以及视觉特征的深度特征嵌入。其次,在语义空间和视觉空间中分别构造了分类网络,以使成对的图文既能对齐类别分布,又能保持对应匹配关系。此外,针对当前零样本图文跨模态检索的研究中未能同时兼顾图文间的类别匹配关系和对应匹配关系,基于掩码的方式,有选择地利用同一类别但不匹配的另一模态数据,以及类别不同的另一模态的数据,以此构造了两种新的匹配约束条件。在CUB和FLO数据集上的实验证明,所提方法有效提升了零样本图文跨模态检索的性能。在后续研究中,也可以引入生成对抗网络的训练方式来消除图像和文本之间的异质性,进一步提升检索表现。
猜你喜欢 图文类别检索 画与理文萃报·周二版(2022年3期)2022-01-20论陶瓷刻划花艺术类别与特征陶瓷学报(2021年4期)2021-10-14CNKI检索模式结合关键词选取在检索中的应用探讨技术与创新管理(2020年5期)2020-10-09一起去图书馆吧少儿画王(3-6岁)(2020年4期)2020-09-13瑞典专利数据库的检索技巧科学与财富(2019年27期)2019-10-252019年第4-6期便捷检索目录意林(图解作文)(2019年6期)2019-07-16英国知识产权局商标数据库信息检索科学与财富(2017年28期)2017-10-14图文配海外英语(2013年9期)2013-12-11图文配海外英语(2013年10期)2013-12-10选相纸 打照片微型计算机(2009年4期)2009-12-23猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
