首页 > 心得体会 > 学习材料 / 正文
后疫情时代侨情危机状况识别方法
2023-02-26 09:20:10 ℃王华珍, 孙雨洁, 何霆, 陆炫羽, 刘晓聪
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)
2020年1月30日,世界卫生组织(WHO)宣布,将新型冠状病毒疫情列为国际关注的突发公共卫生事件(PHEIC)[1].2020年3月11日,WHO表示,新冠肺炎疫情的爆发已经构成一次全球性的“大流行”.新冠病毒席卷全球,海外侨胞的生活也因此受到了极大影响.为贯彻习近平总书记关于侨务工作的重要论述,需要密切跟踪疫情之下海外侨情的动态,充分借助互联网开展工作,增强底线意识和风险意识,为党和国家工作大局贡献力量[2].涉侨突发事件一般是指在非中国境内突然发生的,会给华人华侨造成或可能造成严重危害或损失,需要采取应急处置措施,以应对自然灾害、事故灾害、公共卫生、社会安全、政治冲突等事件[3],其中包括侨情危机事件.因此,基于网络媒体发布的侨情危机事件新闻来研究海外侨情危机状况,具有重要的现实意义和理论价值.
目前,无论是社会科学领域还是工程技术领域,侨情危机事件的研究已成为一大热点.在社会科学领域,学者们主要关注危机事件概念辨析、危机事件构成要素及分析、危机事件的影响、危机事件政府应对策略等.如骆克任等[3]开展的全球涉侨突发事件的危害等级研究,对涉侨突发事件类型及其信息要素进行定义.在工程技术领域,学者们主要注重获取话题的主要内容、事件关系及变化趋势的分析.如李弼程等[4]构建了一种网络话题智能引导的仿真推演系统,该系统能够在仿真推演的基础上实施网络舆论引导,从而突破传统的机械性引导方式.但侨情危机事件的研究仍处于起步阶段,骆克任等[5]对海外涉侨突发事件的危机类别进行定义,并开展了实证研究,但其在进行新闻要素抽取、危机等级判断时未能实现自动化和智能化,主要仍以人工分析为主,耗费人力成本较高,效率较低.此外,目前尚缺乏针对侨情领域的智能信息处理系统,难以对侨情危机状态进行高效、智能的分析和研究.
基于此,本文采用计算机技术,对骆克任团队海外涉侨突发事件危机类别的识别过程进行复现,提出一种基于自动化信息要素抽取的新闻事件类型识别方法,旨在对后疫情时代侨情新闻事件进行智能危机类别划分和事件信息数据展示.
提出的一种基于自动化信息要素抽取的新闻事件类型识别方法,该方法的研究流程,如图1所示.该方法的核心技术包括网络爬虫和自然语言处理技术(NLP).
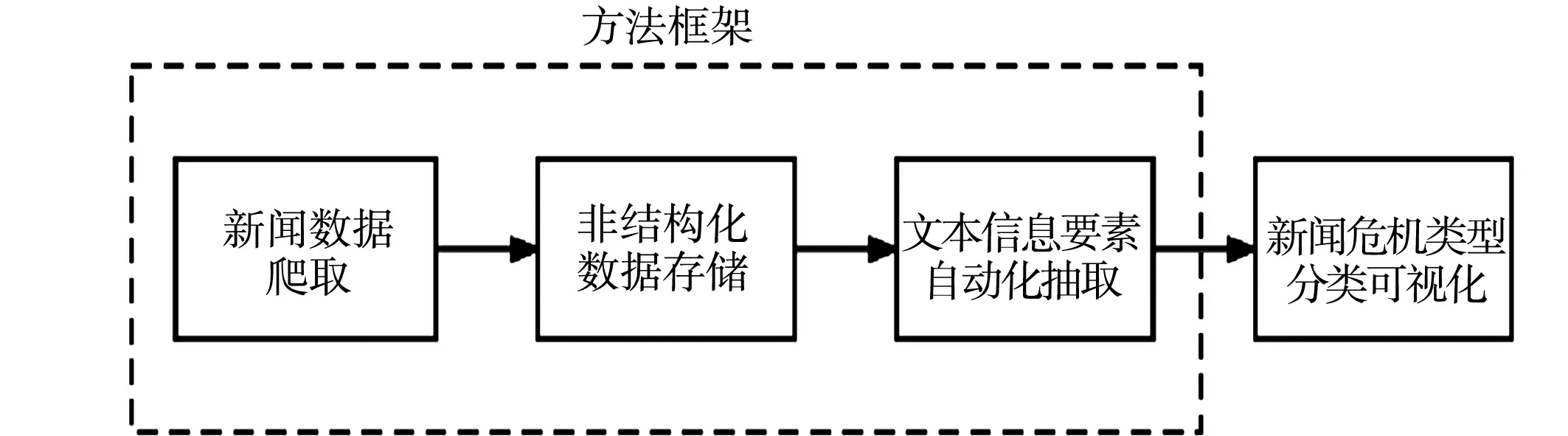
图1 侨情危机事件分类研究流程
1.1 侨情新闻数据获取
1.1.1 数据来源 中国侨网(http:∥www.chinaqw.com/)是由华声报(电子版)社主办的面对全球华侨华人提供综合性信息服务的专业网站,作为中国内地最大的侨务网络信息平台,推出了同心战“疫”信息服务平台,其内容涵盖全球六大洲际的实时海外侨胞新闻.因此,选择2020年1月-8月的中国侨网同心战“疫”信息服务平台的新闻事件数据作为研究对象,筛选出正文字数不少于200字的侨情事件新闻作为语料数据.
1.1.2 获取方式 网络爬虫是一种依据搜索规则自动解析网页并获取网络中符合检索要求的资源的获取程序,可从海量信息中搜寻所需信息.网络爬虫兼具获取数据的精确性与高效性,弥补了传统引擎检索的不足,被应用于自动化新闻分析与管理领域.如朱琪[6]基于网络爬虫技术开发网络舆情分析预警系统;
刘娜[7]以主题爬虫和文本分类技术为基础,设计并实现了冬奥会新闻文本采集及分类分析系统.
中国侨网页面中的新闻内容是由js和模板动态加载显示的,而传统爬虫技术擅长获取HTML页面中的静态部分内容,从而无法直接对新闻正文进行爬取.因此,通过python语言环境下的selenium库调用Chrome浏览器驱动,借用Chrome的自动代理框架控制浏览器的操作,从而直接在页面获取动态加载后的新闻内容.由于爬虫获取的数据格式是纯文本,属于非结构化数据,因此,需要先将非结构化文本按新闻标题、新闻链接、发布时间、新闻正文等进行半结构化存储,构成语料数据.
从中国侨网共获取2020年1月-8月的侨情新闻数据3 432篇.为确保新闻叙述完整性,以便在后续新闻要素抽取时获取完整信息,将获取的3 432篇新闻的正文字数进行统计,筛选后获得3 277篇符合字数要求的新闻.
1.2 侨情危机事件评估指标体系设计
1.2.1 事件及其要素的相关理论 事件是指在某个特定的时间和环境下发生的、由若干角色参与、表现出若干动作特征的一件事情.事件抽取是将文本中描述的事件识别出来并提取事件中的各个信息要素的技术.随着人工智能技术的发展,利用计算机自动抽取文本中的事件要素信息,实现事件自动识别的方法,在舆情监测、文本摘要、自动问答、事理图谱自动构建等领域有着重要应用.据此形成了一系列基于开源公共数据集的事件抽取竞赛活动,如2005年成立的自动内容抽取(ACE)竞赛(简称ACE2005).而在真实新闻事件中,新闻文本句式繁杂、表述多样,这为事件抽取任务带来了挑战.
根据具体的应用场景和问题焦点,事件的信息要素定义标准和要素集合将呈现不同的形式.刘宗田等[8]将事件定义为六元组,包含动作、对象、时间、环境、断言和语言表现;
而ACE2005将事件的信息要素进一步定义为事件类型、事件触发词、事件论元及论元角色.本研究采用ACE2005中的定义标准,其中,事件触发词指的是事件发生的核心词,通常为动词或名词,如遇害、受伤;
事件论元指的是事件的参与者,通常由人物、时间、地点、值等组成;
论元角色指的是事件论元在事件中充当的角色,如人物实体可划分为攻击者和受害者[9].
1.2.2 指标体系的设计 《中华人民共和国突发事件应对法》第3条所述的突发事件是指突然发生的,造成或可能造成严重社会危害,需要采取应急处置措施以应对的自然灾害、事故灾难、公共卫生事件和社会安全事件[10].上述定义是按照事件发生领域进行划分的.骆克任等[3]提出,涉侨突发事件主要是由政治矛盾、社会犯罪、意外事故和民族排斥等引发的危机事件,其划分依据是造成危机事件的原由.而从危机事件造成的后果来划分,将危机事件划分为生命损失事件、财产损失事件、其他事件3种危机类型.
生命损失事件主要是指侨情突发事件中涉及海外侨胞生命损失的事件,包括但不限于人员死亡、受伤.定义生命损失事件的触发词包含死亡、死去、遇害等词语,论元角色包括受害者、工具、地点.财产损失事件主要是指侨情突发事件中涉及海外侨胞财产损失的事件,包括但不限于抢劫财产、偷盗.定义财产损失事件的触发词包含偷窃、遗失、抢劫、诈骗等词语,论元角色包括受害者、方式、地点.
如新闻描述:“在约翰内斯堡,南部非洲齐鲁同乡总会会长夫妇在下班途中,遭遇3名抢匪持枪械进行武装抢劫,不幸遇害身亡.”这条侨情危机新闻同时包含了生命损失事件和财产损失事件,其包含的事件类型及要素汇总,如表1所示.

表1 侨情危机新闻包含的事件类型及要素汇总
为了更准确地划分事件类型,制定了生命损失事件和财产损失事件的触发词词典,如表2所示.该词典使用中文突发事件语料库(Chinese emergency corpus,CEC)并结合专家整理得到.

表2 事件触发词词典
针对文中研究的侨情新闻数据,不属于生命损失事件和财产损失事件的其他类型事件统一视为其他事件.其他事件的触发词指的是排除表2列出的事件触发词,其他事件的论元不需要抽取.由表1展示的事件的触发词、论元、论元角色的定义及表2的事件触发词词典,构成了文中设计的侨情危机事件类型指标体系.
从非结构化的新闻正文文本中抽取出侨情危机事件要素,实现事件信息结构化的相关技术,进而根据结构化的事件信息数据识别出事件的类别,实现事件信息的可视化.由于事件各要素的属性、范畴、性质都不相同,需要分别研发不同事件要素的抽取技术.
2.1 地点要素抽取
侨情事件新闻地点要素抽取研究能够反映各个地区的移民安全状况,为移民安全指数分析提供技术支持,对侨情类型识别具有重要的现实意义.采用深度学习模型和知识推理法实现地点要素抽取任务.首先,对新闻正文和新闻标题的文本运行深度学习模型,抽取出地点实体词汇;
然后,采用知识推理法推理出地点的“地区-国家-大洲”三层次地理位置描述集.
2.1.1 地点抽取模型 地点要素抽取是自然语言处理常见的信息抽取任务,相对应的抽取理论和模型工具非常多.随着人工智能深度学习的发展,将地点抽取问题转换成序列标注问题,再采用深度神经网络进行端对端学习的方式一般能得到最好性能的模型,因此成为解决地点抽取任务的首选方案.李芳芳等[11]基于图模型和膨胀卷积神经网络,提出交通事件要素抽取算法,针对交通事件文本中的地点要素进行了抽取.
文中选用的深度神经网络模型是结构化预测模型,它是线性条件随机场(Linear-chain CRF)的改良模型,能实现地点要素的抽取.结构化预测模型优化了传统的以字符为单位进行编码的方式,在传统标注的基础上加入Tri-gram特征,使高阶预测变量之间的关系同样能够被捕捉[12].该模型由自然语言处理平台BosonNLP提供,采用API接口方式进行调用.BosonNLP平台在分词和词性标注中融合了半监督学习的方式,即使用在大规模无标注数据上的统计数据来改善有监督学习中的标注结果,使序列标注的准确率得到提升[13].针对新闻文本的特异性进行参数调优,在最优参数配置的条件下获得新闻事件地点的抽取结果.
2.1.2 层次地理位置推理 侨情事件具有全球性,事件发生的地理信息可分别从地区、国家、大洲这三层次进行描述,即地区是侨情事件地点的最小单元地理层面,大洲层面为最大单元地理层面.然而,侨情新闻具有本地化特点,每篇新闻中抽取得到的地点信息要素难以在地理等级上做到统一,且文本中一般不会全部出现地区、国家、大洲的三层次地理信息.因此,需对抽取到的地理信息实体进行知识推理,以同时获取地区、国家和大洲的三层次地理信息.
首先,构建“地区-国家”字典与“国家-大洲”字典;
然后,利用python编程方式进行知识推理,实现对每一条新闻的事件地点要素实体进行地区、国家、大洲层面的归类.若新闻中抽取到的地点实体为地区,则自动推理出该地点实体所隶属的国家和大洲.由此,最后得到的新闻事件地点要素是“地区-国家-大洲”三层次地理位置描述集S={area,country,continent}.
2.2 事件触发词抽取
采用词典语义匹配法进行事件触发词的抽取.首先,对新闻正文文本进行分词处理,以筛选出候选触发词;
然后,采用词典语义匹配法计算出语义匹配的触发词.
2.2.1 分词处理 分词处理过程包括分句、分词和词性筛选.由于事件触发词一般为动词、名词、动名词(表2),因此,需要筛选出动词、名词、动名词并进行词频统计,从而获得触发词候选列表,即
L1={(t1,s1),(t2,s2),…,(tN,sN)}.
(1)
式(1)中:t为筛选出的触发词;
s为各词词频;
N为触发词数量.
设置筛选阈值si>1,获得高频触发词候选列表L2.考虑到新闻标题作为新闻正文内容的高度概括,通常包含事件发生地点、事件主要人物、事件核心信息等要素,因此,对新闻标题进行触发词抽取处理,从而获得标题高频触发词候选列表,把它与L2并集得到最终触发词候选列表L3.
2.2.2 词典语义匹配 考虑到词汇表达的多样性和模糊性,如果对最终触发词候选列表L3和事件触发词词典(表2)进行关键词匹配法,将无法全面准确地抽取到事件所需要素信息,进而影响到事件危机类型的判断效果,因此,引入词向量表示法,把相关各个词汇表达成一阶高维向量,在向量空间中计算词汇之间的距离.研究证明,采用深度自然语言处理技术,如word2vec[14],BERT[15]等,构建的词向量具有语义一致性,即两个词之间的向量距离越小,其语义相似性越强.对最终触发词候选列表L3中的词汇进行BERT向量表达,获得触发词候选矩阵W,同时,对事件触发词词典(表2)的词汇进行BERT向量表达,获得触发词词典矩阵D,其具体表达式为
W=[w1,w2,…,wk],
(2)
D=[d1,d2,…,dm].
(3)
式(2),(3)中:k为触发词候选矩阵W中候选触发词个数;
m为事件触发词词典矩阵D中词的个数;
d为事件触发词向量;
w为候选触发词向量.
相似度计算采用余弦相似度算法计算,即通过计算候选触发词向量w与事件触发词向量d夹角的余弦值来判断对应词向量的相似度.一般地,夹角越小,余弦值越大,两个词向量语义越相似.设向量维度为n,w与d的相似度sim的计算式为
(4)

运用前述研究技术,对爬虫获取的3 277篇侨情事件新闻文本进行地点要素抽取模型和事件类别识别的研究,前者的关键技术是地点要素抽取,后者的关键技术是触发词抽取.
3.1 地点要素抽取模型研究结果及可视化
3.1.1 地点要素抽取结果 对3 277篇侨情事件新闻实行地点要素抽取,其中,有3 059篇新闻文本成功实现了地点要素抽取,218篇新闻未能成功抽取地点要素.由于新闻描述的简略性,每篇新闻包含的地点实体不一定具有“地区-国家-大洲”三层次地理位置,因此,采用Linear-chain CRF抽取5 211个地理位置实体词,其中,地区词3 277个,国家实体词23个,大洲实体词34个.针对这218篇新闻进行人工语义分析,并进行地点信息要素抽取,获得新闻事件发生的地理要素实体.对地点要素抽取模型的性能进行评估,得到模型的准确率为96.67%,精确率为100.00%,召回率为93.35%,精确度和召回率的调和平均值(F1值)为96.56%.
3.1.2 “地区-国家-大洲”三层次地理位置推理结果 由地点要素抽取结果可知,3 277篇侨情事件新闻的“地区-国家-大洲”三层次地理位置实体集尚不完整,需要继续采用知识推理获得完整的三层次地理位置实体集.推理结果汇总为地区实体词有2 485 个,国家有2 977个,大洲有3 277个,考虑到向下推理路径无法实现的局限性,地区和国家这两个层次的地点将无法全部获取.文中方法显示了获取每条新闻三层次地理位置信息要素的有效性,为后续的数据可视化奠定了基础.
3.1.3 地点要素抽取结果的可视化 收集的3 277篇侨情新闻中,各大洲危机事件的数量分布,如图2所示.

图2 各大洲危机事件的数量分布
由图2可知:北美洲危机事件的总数目在6大洲中排行第一,是排行第二的亚洲的4倍;
其次是欧洲、大洋洲;
非洲和南美洲的危机事件总数并列最少.根据中国经济网报道[16],2020年6月11日,美国三大股指出现暴跌,北美经济受疫情影响极大.新冠疫情对北美洲国家的经济产生了极大冲击,撼动了北美资本主义国家政治及人文的发展,社会的稳定性被打破,严重影响了北美侨胞的日常生活,大量危机事件也随之而来,使北美洲危机事件总数位居洲际第一.
3.2 事件类型识别结果及其可视化
为了评估文中提出的词典语义匹配法对事件类型识别的智能化效果,需对算法结果进行人工审核,以统计算法的准确率.考虑到人工审核需要耗费大量的人力和时间成本,选择对3 277篇新闻数据进行洲际等比例抽样,获得精简数据集,数据规模为369,再对精简数据集进行事件类型识别研究.精简数据集的洲际分布情况,如表3所示.

表3 精简数据集的各大洲分布情况
3.2.1 事件类型识别结果 根据文中方法获取到369篇新闻的事件类型,各大洲事件类型识别结果,如表4所示.

表4 各大洲事件类型识别结果
表4中:以北美洲为例,220条新闻中有35条新闻包含生命损失事件,118条新闻包含财产损失事件,70条新闻属于其他事件,其中,有6篇新闻既包含生命损失事件,又包含财产损失事件.其他洲的事件类型识别结果也按照该规律进行统计.
3.2.2 事件类型识别结果的可视化 可视化的基础维度包括月份、地理、事件类型,由此可以构建事件类型月分布、涉事国家月分布、涉事洲际月分布.多维度统计项的相关指标,如表5所示.

表5 多维度统计项的相关指标
用Excel的数据透视图工具进行数据可视化制作.数据透视表具有表格“透视”的能力,可以挖掘出数据中隐藏的关系,将纷繁的数据有序化,以供研究使用[17].将数据透视技术应用到侨情危机状况研究中,可以实现数据集、透视表、可视化图形的实时联动反应,从而增强数据可视化的交互质量.首先,将研究得到的369篇侨情事件新闻数据作为可视化的语料数据集;
其次,根据月份、地理、事件类型等3种可视化的基础维度,结合侨情事件新闻数据分析的需求,设计不同数据透视表的行字段、列字段和求和项,从而得到多个(10个)数据透视表;
最后,将语料数据集与数据透视工作表创建关联,通过数据透视图左侧的切片器实现月份、地理、事件类型等3种维度下的数据透视图.
全球危机事件概况可视化结果,如图3所示.图3中:左侧为月份选取栏,使用者可以通过点选不同月份来获知对应月份的危机事件概览结果,实现简单的交互功能;
右侧为可视化结果展示栏,通过柱状图的形式直观地展示了对应月份各大洲的危机事件总数,并以折线图的形式分别展示了各大洲生命损失事件和财产损失事件的计算分数,有利于各大洲不同类型危机事件的横向比对.
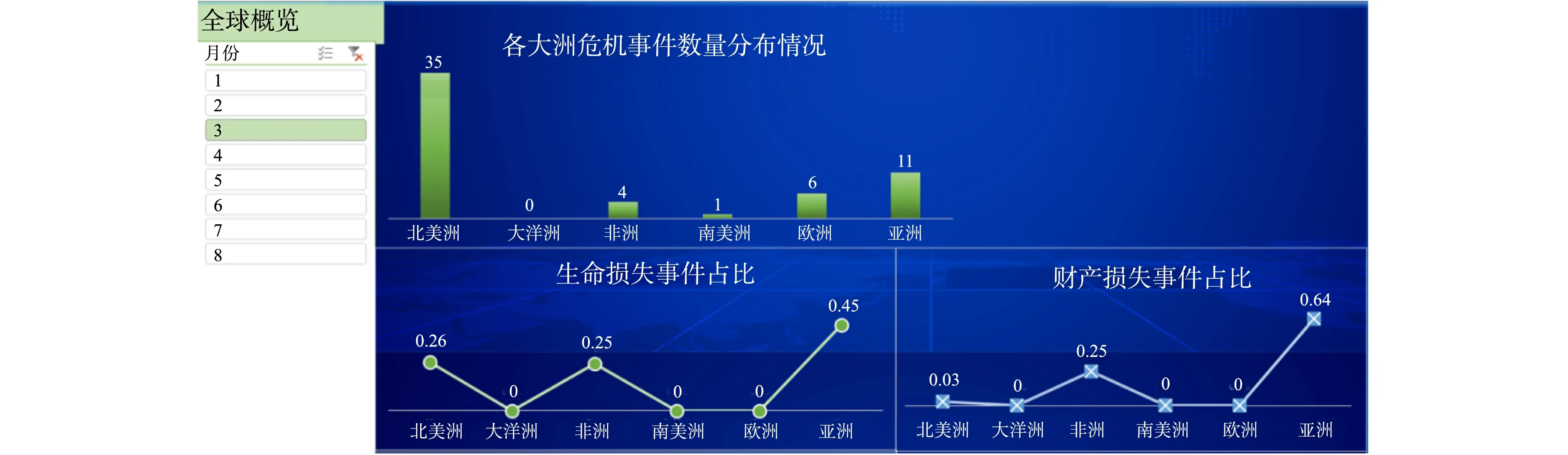
图3 全球危机事件概况可视化结果
以3月份的全球概览为例,危机事件数量最多的是北美洲,有35起.针对生命损失而言,亚洲的占比最高;
而对于财产损失而言,亚洲的占比也最高.这说明,虽然北美洲危机事件数量最多,但大多数应该属于其他事件类型.
新闻来源分析可视化结果,如图4所示.图4中:左侧为大洲选取栏,使用者可以通过点选不同大洲来获知对应洲的危机事件来源分析结果,实现简单的交互功能;
右侧为可视化结果展示栏,通过饼状图展示了各个国家危机事件的总数,并结合条形图综合展示了各国在不同月份发生危机事件的状况.该可视化结合了地点要素抽取的结果,针对各大洲中各个国家每月报道的危机事件数量,在地理层面上进行细分,更详细地展示了各大洲危机事件的来源地.

图4 新闻来源分析可视化结果
具体地,以亚洲为例,危机事件数量最多的国家为马来西亚,有29起.马来西亚的月分布也是比较密集的:2月9起;
3月2起;
4月5起;
5月13起.
月份事件统计可视化结果,如图5所示.使用者通过点选左侧的月份,在右侧以面积图的形式更直观地展示各国在对应月份中的危机事件数量,同时以饼状图的形式展示对应月份中各大洲的危机事件数量.以8月份为例,全球视角下危机事件数量最多的国家是美国,有25起.
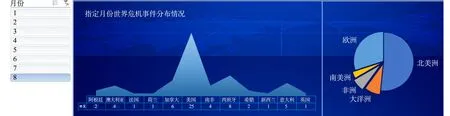
图5 月份事件统计可视化结果
提出一种基于自动化信息要素抽取的新闻事件类型识别方法,采用爬虫技术实现新闻数据获取,极大程度地节省了人力查找、获取数据的成本.在数据的处理部分,文中方法结合自然语言技术和语义词典方法,对新闻文本进行地点要素实体和触发词实体的智能抽取,实现事件类型的智能识别,省去了人工阅览新闻内容、手动划分的过程.对海外涉侨危机事件危机类别识别的推理方法涉及新闻实时爬取和新闻危机类别判定两个过程,所涉及的时间复杂度也由这两部分组成.其中,新闻爬取一般采用周期性定时爬取方式,而推理算法的时间复杂性为O(N)+O(N2),其中,O(N)为分词复杂度;
O(N2)为触发词字典语义匹配过程.最后,采用数据透视技术实现月份、地理、事件类型等三维度的数据聚合可视化,详细展示了侨情危机的具体情况和变化过程,从而获得侨情危机信息的多角度解析.综上可知,文中方法能提升侨情分析的效率,且可进行多维度的危机状况信息可视化,有助于制定危机事件的应对策略.
然而,文中方法对文本中暗含的事件地理位置信息无法实现自动抽取,仍需要依靠人工进行手动提取地理信息要素,因此,后续工作可以深入研究语义挖掘相关的技术,以提升隐含地理信息要素的抽取成功率.同时,由于定义的触发词词典数量有限,不能完全覆盖该危机事件类型中的全部触发词,所以在后续工作中仍然需要不断扩充触发词词典,以提高事件划分的召回率.另外,关于新闻危机事件研究的最新发展现状,如舆论引导、传播策略与信息建构等,并未见针对侨情领域的相关研究[18-20],这也是未来可继续探索的方向.
猜你喜欢 大洲可视化危机 基于CiteSpace的足三里穴研究可视化分析世界科学技术-中医药现代化(2022年3期)2022-08-22思维可视化师道·教研(2022年1期)2022-03-12动物“萌主”在澳洲作文大王·笑话大王(2020年6期)2020-06-22基于CGAL和OpenGL的海底地形三维可视化海洋信息技术与应用(2020年1期)2020-06-11“融评”:党媒评论的可视化创新传媒评论(2019年4期)2019-07-13高等教育的学习危机英语文摘(2019年4期)2019-06-24大洲与大洋学校教育研究(2019年16期)2019-03-24地球七巧板红领巾·探索(2018年12期)2018-01-26不讲读者(2016年22期)2016-11-01“危机”中的自信汽车观察(2016年3期)2016-02-28猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
