首页 > 心得体会 > 学习材料 / 正文
面向招标物料的命名实体识别研究及应用
2023-03-10 17:00:04 ℃米健霞,谢红薇
太原理工大学 软件学院,太原030024
随着互联网的迅猛发展,电子招投标依托于互联网的开放环境也得到了迅速发展,并形成了一种全新的投标采购活动。用户依托于电子招投标,可以互不谋面地与供应商进行采购活动。然而,随着电子招标采购领域的深化与扩展,命名实体识别成为从海量数据中为用户提取有价值的信息的重要手段之一。
命名实体识别最早采用基于规则和字典的方法,此方法可以对具有一定规律的语句准确反映,但依赖于大量的人工,耗费代价太大,且泛化能力极差。随后出现了最大熵模型[1]、条件随机场(conditional random field,CRF)[2]、隐马尔可夫模型(hidden Markov model,HMM)[3]等基于统计机器学习的方法,此方法能够减少人工成本,但这类方法仍需要大量语料库和标注支持。随着卷积神经网络(convolutional neural networks,CNN)[4]、循环神经网络(recurrent neural network,RNN)[5]、长短期记忆网络(long short-term memory,LSTM)[6]、双向长短期记忆网络(bi-directional long-short term memory,BiLSTM)[7]等基于深度学习方法的迅猛发展,命名实体识别的研究迎来了新的曙光,打破了传统方法的约束,解决了数据中高维、冗杂等传统机器学习难以解决的问题,不需要大量的人工干预便可以得到较好的识别效果。
虽然针对命名实体识别的研究已较为广泛,但在招投标领域尚未得到较好的发展。现阶段,招投标公司仍使用规则的方法解决物料识别问题,时间及人力成本较高。因此,提出一种基于深度学习的面向招投标领域的命名实体识别方法,不仅能够降低时间和人力成本,而且能够增强泛化能力,为招投标物料问题的解决提供了一种高效的新方案。
近年来,大量学者对命名实体识别方法及应用进行了深入研究,梅丰等[8]将电子数码领域中的品牌知识库与最大熵模型结合进行训练学习,最终F1值达到86.91%;
刘非凡等[9]为证明隐马尔可夫模型在解决多尺度嵌套序列方面的有效性优于最大熵模型,对电子数码和手机两个领域的产品名、产品型号、产品品牌三种实体进行识别,F1值分别为79.7%、86.9%、75.8%;
谷川等[10]在条件随机场中融合词、词性、品牌、数字、特殊符号五种不同层次特征,在电子数码和家电领域中的F1值达到了93.67%;
蒋超[11]提出创新的回溯CRF算法,并结合特征提取优化算法运用到研报领域产品中,丰富了模型特征,准确率达到了87.34%;
虽然这些方法取得较好的效果,但这类方法仍需要大量语料库和标注支持。随着深度学习的迅猛发展,此类方法被广泛使用,李博等[12]使用Transformer-CRF模型,在医学电子病历中取得了95.02%的F1值;
买买提阿依甫等[13]通过构建BILSTM-CRF深层模型,验证了该模型在解决维吾尔文命名实体识别中的鲁棒性;
李一斌等[14]在中文包装产品命名实体中验证了双向GRU-CRF模型优于单向长短期记忆模型,最终准确率达到了82.45%;
张应成等[15]对标书的实体识别进行了研究,运用BiLSTM-CRF模型对标书中的招标人、招标代理和招标编号三种实体进行识别,其准确率分别为82.16%、88.91%、85.74%;
但此类方法仍有缺点,无法有效地处理一词多义问题,且没有考虑到分词的影响,从而影响命名实体识别。唐焕玲等[16]提出BERT预训练模型和CRF相结合的方法,验证了BERT模型能够充分学习语义特征,从而解决语料中一词多义。
中文作为一种象形文字,有独特的字形特征,如部首、笔画、五笔等特征以及端点、折角点、交叉点等特殊特征。汉字结构特征和其所蕴含的事物信息往往具有关联相似性,如具有“艹”“竹”“木”等偏旁的汉字多于植物有关,许多疾病实体词往往带有“疒”部首,Dong等[17]用汉字的偏旁部首信息来增强汉字信息,用LSTM-CRF模型对中文实体进行识别;
赵健等[18]为了验证特殊特征对手写汉字识别率提升的重要性,选择汉字笔画的特殊特征进行提取,例如端点、折角点、交叉点特征;
Dai等[19]为了证明字形特征对命名实体识别的影响,运用CNN提取汉字的图像特征达到了较高的识别率。但以上方法只使用了汉字的一种特征,泛化能力较差。
考虑到BERT模型可以解决招标物料的多义性和分词问题,CNN提取汉字的五笔特征可以增强语义向量,BiLSTM可以对其结合的信息进行上下文提取,CRF能够对BiLSTM的标签结果进行检查约束,从而获取最优的全局标注序列,本文提出一种CB-BiLSTM-CRF模型,用来识别招标物料中名称、自然高、胸径、冠幅、光束角、功率、光通量等12种实体。
本文首先采用BERT预训练模型对输入文本进行特征提取,通过双向Transformer编码器,对词前后的信息充分利用,从而获取更准确的词向量分布表征;
同时将输入文本转换为五笔编码的形式,通过CNN对五笔编码进行卷积提取字形特征,随后,将BERT获得的字向量与汉字五笔字形向量相结合,并将组合结果作为双向LSTM的输入进行训练,最后将双向LSTM模型的结果输入到CRF中进行约束,最终得到最优预测结果,这样既结合了中文特有的字形特征,避免了分词,又实现了一词多义。这一创新模型通过对中文特有的字形特征与BERT预训练模型结合,减少了命名实体的识别错误,能够以少量的资源实现高效的识别效果。本文提出的CB-BiLSTM-CRF模型结构如图1所示。

图1 CB-BiLSTM-CRF模型架构图Fig.1 CB-BILSTM-CRF model architecture diagram
2.1 字形特征提取
卷积神经网络由Yan Lecun于1998年提出,卷积神经网络由卷积层、激活层和池化层三部分构成,该模型采用局部链接和权值共享的策略,减少了网络参数,具有平移不变形。卷积层的作用是利用不同尺寸的卷积核在输入的特征上以特定的步长滑动进行卷积计算;
在池化层中,卷积数据和参数量被压缩,一方面可以简化神经网络的计算复杂度,另一方面能够通过压缩来提取主要特征;
激活层是利用激活函数对结果做非线性映射,使其能够更好地解决复杂的问题。
汉字作为世界上最古老的象形文字之一,所蕴含的含义大多与汉字字形密切相关,具有相似字形的汉字往往也具有相似的含义,但是汉字的这一特性在电子招投标命名实体识别领域还未充分利用。五笔特征在编码时充分结合了汉字的笔画和字形结构,是一种能较好表征汉字字形特点的编码形式。例如,汉字“花”由“艹”“亻”“匕”三种笔画组成,分别用“a”“w”“x”表示,“花”的上下结构和最后笔画“折”用识别码“b”来表示,由汉字的笔画信息和结构信息便组成了“花”的五笔编码,即“awxb”。因此,本文充分利用这一特点,将汉字转换为五笔编码形式,然后利用CNN的卷积和池化操作进行特征提取,最终得到五笔特征向量。字形特征提取步骤如下:
步骤1将输入的中文语句拆分为单个汉字。
步骤2用程序实现每个汉字向五笔编码的转换,以特殊符号作为每个汉字五笔编码间的分隔符。
步骤3通过五笔编码获取对应汉字的五笔向量矩阵表示,利用CNN网络的卷积和池化操作对每个汉字的五笔特征进行提取。
2.2 BERT预训练模型
2018年,Devlin等[20]提出了BERT模型,该模型采用了只有编码模块,没有解码模块的双向Transformer结构。
BERT模型将三个能够充分表达语义信息的向量相加作为输入,分别为token词向量、segment句子向量和位置向量;
其中segment句子向量的作用主要是通过在句首添加[CLS]开始标志,句尾加[SEP]结束标记来判定词汇的语句归属;
BERT模型通过这三个输入的向量,既能够实现对字符级、词级、句子级甚至句子之前的关系的充分描述,又可以更好地表征不同语境中的句法与语义信息。
BERT模型有两大核心任务:Masked LM和下一句话预测。Masked LM,即mask语言训练模型,BERT模型中,作者随机抽取训练集15%的词,在抽取的词中,80%用[mask]替换,10%维持不变,10%用随机词进行替换,通过这样的方式对被msak的词的原意进行预测。下一句话预测是针对所有训练的语句,对语句之间的关系进行判断,例如,A、B是预训练样本,B有50%的概率是A的下一句,记为IsNext,同理,B有50%的概率不是A的下一句,而是一句随机从训练集中抽取的语句,记为NotNext。BERT模型通过这两大任务分别捕捉词和句子的表示,进而更好地利用上下文信息。
BERT模型的核心是Transformer中的自注意力机制,首先对每句话中每个词与其他词的相似度进行计算,然后对相似度做归一化得到注意力权重,利用注意力权重对字向量进行加权线性组合,从而使得每个字向量都含有当前句子中所有字向量的信息。计算公式如下:
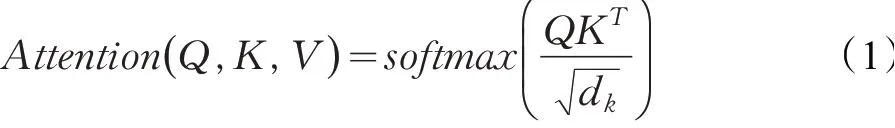
其中,Q为要查询的词,K为其他词,V为真实被取出来的值,dk为Q和V的维度,先用Q与每个K做attention点积计算,然后通过与dk做除把注意力矩阵转为标准正态分布,保证结果的稳定性,接着用softmax进行归一化,最后乘以V得到输出向量。
softmax函数,常用于多分类问题中,作用是将得到的分值进行归一化,最终概率值分布在[0,1]之间,且概率和为1,概率最大的便是预测目标,计算公式如公式(2):

为了确保每个head关注的信息都不同,BERT模型利用多头自注意力机制,将词的多种维度作为多个head,这样每个head便可以从不同的表示子空间进行学习。公式如下:

BERT模型解决一词多义问题,Masked LM、下一句话预测这两大核心任务和多层双向Transformer及其多头自注意力机制发挥着重要的作用,Masked LM使其不仅学习下文信息,也能够学习到上文信息,多头自注意力机制能够同时提取特征,解决长距离依赖问题,这样便使每个词可以同时利用该词的上下文信息,从而达到一词多义的效果。
2.3 BiLSTM模型
1997年,Hochreiter、Scmidhuber[21]为了解决RNN模型的缺点提出LSTM网络,该模型的诞生,为RNN中梯度消失及爆炸问题的解决提供了途径,从而摆脱了在处理长期依赖信息方面的困扰。
LSTM整体功能的实现主要依靠细胞状态、输入门、遗忘门、输出门等组件。其中,遗忘门输入的是上一时刻隐含层ht-1和这一时刻的输入xt,sigmoid激活函数作为是否遗忘上层细胞状态内容的标准;
输入门既要对输入信息进行处理,又要对更新信息进行确定,同时更新细胞状态;
最后,输出门决定输出细胞状态中保存的哪些信息。图2为LSTM的结构图。

图2 LSTM结构图Fig.2 LSTM diagram
LSTM网络的计算过程如公式(5)~(10)所示,其中ht-1表示上一时刻隐含层状态,xt表示这一时刻的输入,以it作为输入门,ot作为输出门,ft为遗忘门,W作为权重矩阵,用b表示偏置,Sigmoid激活函数为δ,双曲正切函数为tanh。
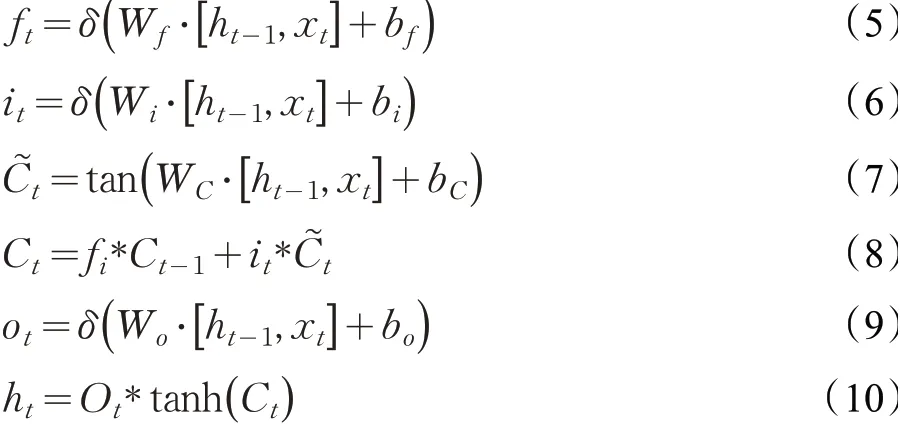
Sigmoid函数和tanh函数是两种使用广泛的激活函数。Sigmoid激活函数,如公式(11),用于二分类问题中,其取值范围为(0,1),即经过Sigmoid函数激活后恒为正值;
tanh双曲正切函数以(0,0)为中心点,其取值范围为(-1,1),收敛速度与Sigmoid相比更快,如公式(12)。

BiLSTM模型,即双向LSTM模型,由前向LSTM和后向LSTM共同结合而成,结构如图3所示。BiLSTM不仅可以学习到前向的有效信息,还可以学习到后向信息,更好获取上下文信息,进而提高识别率。

图3 BiLSTM结构图Fig.3 BiLSTM diagram
2.4 条件随机场CRF
2001年,Lafferty等[22]提出CRF模型,CRF模 型可以解决BiLSTM模型难以实现的标签依赖的问题,如BiLSTM模型可能会在“O”标签后输出“I-mc”等错误标签,CRF模型通过计算句子的标注序列概率可以得到标签之间的约束条件,如标签开头应该是“B”或“O”,“O”后边不应该输出“I-mc”,“B-mc”后应该是“I-mc”或“O”等;
CRF模型通过给定句子x计算标注序列y的概率如公式(13)、(14),其中F(y,x)是转移矩阵和状态矩阵。
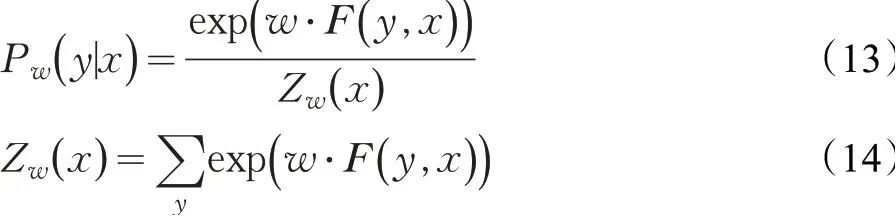
2.5 “智能物料”网页平台
本文采用python语言,通过整合Flask轻量级框架设计并构建了“智能物料”可视化Web在线识别平台,可以快速识别出名称、胸径、藤长、功率、光通量、光束角、品牌等特征。该平台初始界面如图4。

图4 “智能物料”在线识别平台初始界面Fig.4 Initial interface of“Smart Materials”online identification platform
其中,输入框记录用户提交的物料信息,“在线识别”按钮将用户参数传递至Web后端,通过调用训练好的模型对输入数据进行识别,最后将识别结果返回到“智能物料”在线平台中,识别界面如图5所示。

图5 “智能物料”在线识别平台识别界面Fig.5 Identification interface of“Smart Materials”online identification platform
3.1 实验数据与标注
由于电子招投标领域的特殊性,缺乏权威性的语料支持,所以本文采用人工收集的方式来构建实验样本。实验数据来源于两部分,一部分是招标公司提供的真实发生采购的物料数据,另一部分是从各招标网站中爬虫的产品数据,一共收集了约8万条数据,其中植物类约2万条,灯具类数据约3万条。实验中,使用植物类、灯具类两类数据,并将数据集按2∶2∶6的比例随机分为验证集、测试集和训练集。本文采用的标注方法为BIO标注法,采用的判断预测正确的条件为实体的边界和类型都正确。实体标签及标注如表1所示。

表1 实体标签及标注Table 1 Physical labeling and labeling
3.2 实验评价标准
本文将准确率P、召回率R、F1值作为实验的评价标准,公式如下:

3.3 实验参数设置
本实验使用12层的谷歌BERT-Base预训练模型,隐藏层数为768,12头,参数共110×106。实验参数如表2所示。
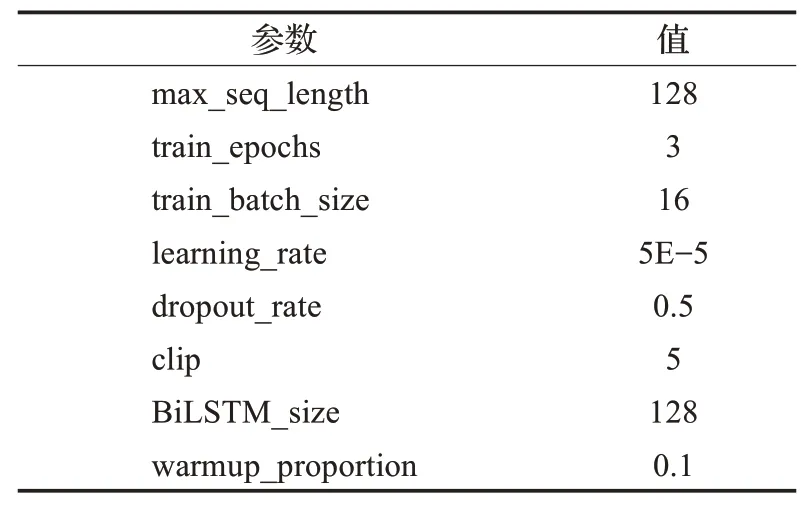
表2 实验参数Table 2 Experimental parameters
3.4 实验结果
为了证明模型的实验效果,本文用相同的数据集分别以GRU-CRF、LSTM-CRF、BiLSTM-CRF、CNNBiLSTM-CRF、BERT-BiLSTM-CRF、CB-BiLSTM-CRF模型进行了实验,并用同样的评价标准进行评价,各方法的实验结果如表3所示。
实验1为了对比GRU和LSTM在命名实体识别的效果,使用GRU-CRF和LSTM-CRF两种方法进行实验,由表3可知,LSTM-CRF准确率、召回率、F1值分别为75.12%、77.63%、76.35%,分别比GRU-CRF提高了0.59、0.76、0.82个百分点。由此可见,LSTM-CRF识别效果较好,因此本文选用LSTM-CRF作为基准模型。

表3 各方法识别结果Table 3 Results identified by each method单位:%
实验2采用BiLSTM-CRF模型,由表3可知,其识别效果比LSTM-CRF模型提高3.05、1.96、2.52个百分点,这是因为BiLSTM-CRF模型能够提取前向和后向两个方向的语义信息,相较于特性提取方向单一的LSTMCRF模型而言,具有更好的实体识别效果。
实验3在实验2的基础上增加了卷积神经网络,由表3可知,CNN-BiLSTM-CRF模型在识别准确率、召回率、F1值上比BiLSTM-CRF模型分别提高7.91、5.97、6.94个百分点,说明通过CNN能够有效对招标物料特征进行局部提取,从而提高招标物料命名实体的识别效果。
实验4将实验3的CNN换为BERT预训练模型,实验表明BERT-BiLSTM-CRF模型比CNN-BiLSTM-CRF模型提高了约8个百分点,主要因为本文的招标物料内容更多涉及一词多义的处理,CNN仅对招标物料局部特征进行提取,难以处理一词多义问题,BERT模型利用多头注意力机制提取句子中的语义信息从而解决这一问题,因此BERT-BiLSTM-CRF模型整体优于CNNBiLSTM-CRF模型。
实验5为了进一步提高招标物料的命名实体识别准确率,本文提出CB-BiLSTM-CRF模型,利用CNN对招标物料五笔字形特征提取,最终F1值达到了95.82%,说明将BERT预训练模型获得的字符向量和CNN模型获得的字形五笔特征相结合可以强化招标物料的语义信息,从而达到更高的识别效果。
最后对本文招标物料名称、胸径、藤长、冠幅等12类实体在CB-BiLSTM-CRF模型和BERT-BiLSTM-CRF模型进行实验做细化对比,两模型在12类实体的F1值结果如表4所示。可以看出,其中名称和胸径相较于其他实体识别效果最好,F1值均达到98%以上,这是因为名称和胸径实体有较为明确的上下文信息以及字形特征;
而品牌这一实体的识别效果最差,其原因是品牌种类繁多,没有特定的字形特征,边界不好确定,但相较于BERT-BiLSTM-CRF模型提高了1.01个百分点。综上所述,从表中可以看出本文模型对招标物料的识别效果有一定的积极影响。
传统招标物料数据的识别过度依赖人工,人为定义的数据识别规则对物料的识别率起决定性作用。随着招标领域物料数据的复杂性、多样性、数据量的不断提升,通过人工定义规则的识别方式已经不能满足需求,本文提出CB-BiLSTM-CRF模型,在提升识别效果的同时降低了人力成本。通过采用不同模型对多类物料数据进行实验,最终使F1值达到95.82%,说明了在招标物料的命名实体识别中,CB-BiLSTM-CRF模型效果更好。同时,本文搭建了在线招标物料命名实体识别网页平台,方便用户快速从文本中提取有效信息。
虽然本文提出的模型在招标物料中达到了95.82%的F1值,但本文仅使用植物类和灯具类两种物料数据,且没有考虑到错别字和别称的问题,接下来将结合错别字和别称的情况在更多种类的物料数据进行实验对比,以提高招标物料的命名实体识别效果。
猜你喜欢 招标实体卷积 基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02公立医院招标采购集中管理模式探索与实践医院管理论坛(2020年11期)2020-07-10卷积神经网络的分析与设计电子制作(2019年13期)2020-01-14前海自贸区:金融服务实体中国外汇(2019年18期)2019-11-25从滤波器理解卷积电子制作(2019年11期)2019-07-04基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20实体的可感部分与实体——兼论亚里士多德分析实体的两种模式哲学评论(2017年1期)2017-07-31两会进行时:紧扣实体经济“钉钉子”领导决策信息(2017年9期)2017-05-04振兴实体经济地方如何“钉钉子”领导决策信息(2017年9期)2017-05-04- 上一篇:卡车-无人机协同救灾物资避障配送问题研究
- 下一篇:余弦自适应混沌被囊体种群优化算法
猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
