首页 > 心得体会 > 学习材料 / 正文
边界注意力辅助的动态图卷积视网膜血管分割
2023-05-06 14:55:23 ℃吕佳,王泽宇,梁浩城
1 重庆师范大学计算机与信息科学学院,重庆 401331;
2 重庆师范大学重庆国家应用数学中心,重庆 401331
视网膜血管的健康状况是诊断眼部疾病乃至全身性疾病常考虑的因素之一,尤其是视网膜血管的萎缩状况或病变层次等是明确疾病严重程度的关键。视网膜血管分割是获取这些关键信息的必要步骤,良好的分割结果有助于准确地诊断眼部疾病[1-2]。然而,由于视网膜血管复杂的网状结构,人工分割存在费时费力和易受主观因素影响等弊端,因此自动分割视网膜血管受到了广泛关注[3]。在视网膜血管自动分割任务中,一方面,由于视网膜图像具有血管和背景对比度低、背景噪声多等特性,导致血管标注不正确或不完整等问题;
另一方面,由于医学数据的收集受到个人隐私、收集成本等因素限制,使得可用于训练的数据很少。这些均限制了模型的泛化性,当面对临床噪声多的数据时,模型容易遗漏血管像素或误分割噪声。而提升模型泛化性的关键在于能最大限度地学习血管的特征信息[4]。
近年来,U 型网络(U-shape network,U-Net)采用跳跃连接融合多尺度特征的方式,在数据量少的医学图像处理任务中取得不错的效果[5],自然地被应用于视网膜血管分割任务。然而,U-Net 在训练过程中会忽略视网膜血管的特性,无法充分提取血管的特征信息,导致分割结果易产生较多断连的毛细血管。为此,研究者针对视网膜血管分割任务对U-Net 进行了诸多改进。Jin 等人[6]将可变形卷积引入到U-Net 中,利用可变形卷积捕获多尺度局部上下文依赖,进一步丰富了特征信息,改善了视网膜血管分割的效果;
Wu等人[1]利用视网膜血管尺度变化大的特点,设计了尺度感知特征聚合模块和自适应特征融合模块,有效提取了视网膜血管的多尺度特征,并引导了相邻层次特征之间的融合;
Zhang 等人[7]结合多核池化和空洞卷积来改进U-Net,通过选择不同的扩张速率,得到了更大的感受野,获取到更多的局部上下文信息。尽管这些方法从不同的角度利用了视网膜血管的特征信息,却忽略了视网膜血管的全局结构信息,而获取结构信息已被证明是提高图像分割性能的有效方法[8]。
图卷积网络(Graph convolution network,GCN)是一种基于图(graph)的特征提取网络,具有较好的结构信息获取能力[9]。Shin 等人[10]将GCN 与卷积神经网络(convolutional neural network,CNN)级联,从CNN 输出的分割图中提取血管骨架来构造图,进一步获取血管的结构信息,提高了视网膜血管的分割性能;
Meng 等人[11]利用注意力优化模块聚合GCN 和CNN,选择视网膜图像中视盘和视杯的轮廓点构造图,以此融合结构信息来提升视盘和视杯的分割性能。然而,上述方法构造的图是独立于分类任务的静态图,难以降低真实数据受噪声的干扰度,导致图的质量较低。由于GCN 的性能高度依赖于图的质量,因此静态图限制了GCN 的性能[12]。本文采取动态图的图构造方法[13]来克服静态图不能调整图的问题,以此捕获视网膜图像更充分的全局结构信息。动态图的原理在于图的邻接矩阵权重能通过反向传播学习调整,以此输出更灵活有效的图。
虽然采用动态图卷积丰富了视网膜血管的全局结构信息,但在上下采样过程中,血管的浅层边界信息仍会被稀释。为了强化边界信息,Zhang 等人[14]将原始分割任务转换为多分类任务,使得模型能更多地关注血管边界信息,但该模型需要针对粗细血管的边界区域进行额外标注,流程过于繁琐。Zhang 等人[15]提出一种只关注血管边界的门控卷积来强调血管边界,虽然模型省去了边界分类的流程,但增加了计算复杂度。而本文采用了一种高效的边界注意力网络来强化视网膜血管的浅层边界信息,其不仅轻量化还能提升视网膜血管的分割性能。
综上所述,针对视网膜血管分割任务中毛细血管断连的问题,本文利用动态图卷积为U-Net 添补了全局结构信息,并采取轻量化的边界注意力网络保留了边界信息,从而达到充分提取视网膜血管特征信息的目的,提升了视网膜血管的分割质量。本文主要贡献为:1) 提出一种边界注意力辅助的动态图卷积视网膜血管分割网络,通过捕获视网膜血管的全局结构信息和边界信息,改善毛细血管断连的情况;
2) 提出基于U-Net 的多尺度动态图卷积,增强动态图卷积捕获全局结构信息的能力;
3) 引入轻量化的边界注意力网络,使模型更加关注视网膜血管的边界区域,以减少边界信息的丢失。
2.1 网络结构
视网膜图像因受光照不均匀以及各种病变因素的影响,背景噪声多且部分血管像素模糊,导致利用简单跳跃连接以及上下采样操作的U-Net 丢失了视网膜血管的大部分全局结构信息和边界信息,无法更有效地区分视网膜图像中的噪声和血管像素,因而造成毛细血管分割遗漏或断连的问题。针对上述问题,本文提出边界注意力辅助的动态图卷积视网膜血管分割网络-边界注意力辅助的动态图卷积U 型网络(boundary attention assisted dynamic graph convolution U-Net,BDGU-Net)。该网络利用动态图卷积,将血管的特征信息存储在动态图中进行推理,这样不仅有效地区分了高度相似的噪声和毛细血管,而且为U-Net提供了更细致的全局结构信息。此外,该模型借助边界注意力网络来加强上下采样过程中被稀释的浅层边界信息,以提高模型的分割能力。BDGU-Net 的网络结构如图1 所示,主要包括主干网络、边界注意力网络和特征融合网络。

图1 边界注意力辅助的动图卷积U 型网络Fig.1 Boundary attention assisted dynamic graph convolution U-shaped network
主干网络包括编码器以及解码器。在编码器中,特征图每经过一次下采样,其尺度减小一半、通道数增加一倍。在解码器中,特征图每经过一次上采样,其尺度增加一半、通道数减少一倍,并与编码器相同尺度的特征图进行跳跃连接,再经过该尺度动态图卷积获取其结构信息。文献[16]证明,小尺度的特征图包含了较丰富的语义信息,大尺度的特征图保留了较足够的结构信息,故不同尺度的特征图之间可以相互补充。因而BDGU-Net 将动态图卷积自底向上地应用于解码器中不同尺度的血管特征图。具体地,本模型将1/8 大小的特征图输入动态图卷积,加强该尺度的结构信息,再将其与原始特征信息相加融合,执行上采样操作,以使融合结构信息的特征图传递至下一解码层中,从而丰富大尺度特征图的结构信息。1/4 大小、1/2 大小以及原图大小的特征图同样采取上述操作,最终捕获到视网膜血管更充分的全局结构信息。特别地,原图大小的特征图不再进行上采样操作,而是直接利用1×1 卷积操作输出对应类别数。边界注意力网络主要借助边界注意力损失引导主干网络定位边界区域,可以被视为一种中间监督。特征融合网络可以更好地融合主干网络和边界注意力网络分别提供的语义信息和边界信息,模型得以保留更多的血管像素。
2.2 动态图卷积
U-Net 通过简单地融合编码器和解码器相同尺度特征图的方式,整合了视网膜血管粗粒度的全局结构信息,即丢失了毛细血管或复杂形态的血管的结构信息,导致U-Net 区分噪声和血管像素的能力较差。本方法在U-Net 解码器中嵌入动态图卷积来增强模型辨别背景和血管像素的能力,使整体的分割性能提高。动态图的原理[17]如图2 所示。首先将解码器提取的血管特征信息构造为加权邻接矩阵表示的图结构,在前向传播的过程中,聚合不同关联度的邻居信息,以此更新中心节点的特征。后在损失函数反向传播的过程中,利用梯度更新自动学习节点之间的依赖关系,调整邻接矩阵,在增加同类别节点特征关联度的同时,降低噪声节点和血管节点间的特征关联度,这样能更容易区分血管像素和背景像素,从而为模型提供细粒度的全局结构信息。动态图卷积分为动态图构造和图卷积计算两个步骤,如图3(a)所示。
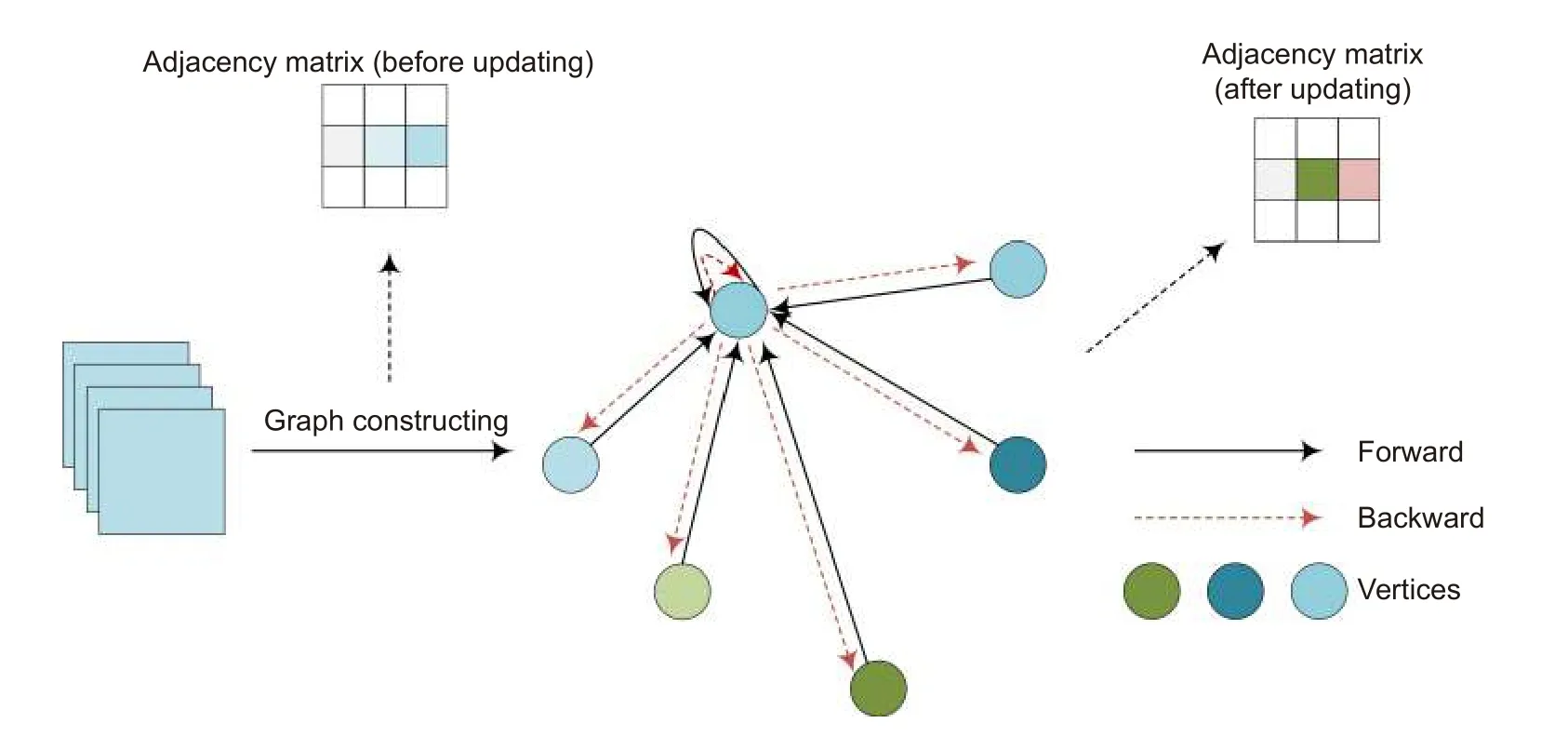
图2 动态图原理Fig.2 Principle of dynamic graph

图3 动态图卷积计算过程和特征融合网络。(a) 动态图卷积计算过程;
(b) 特征融合网络Fig.3 Dynamic graph convolution calculation process and Feature fusion network.(a) Dynamic graph convolution calculation process;(b) Feature fusion network
第一步,动态图构造。给定图G=(V,A),其中V∈RN×C为图节点矩阵,N表示图节点数目,C表示图节点特征的维数;
A∈RN×N为邻接矩阵,表示各节点间的连接关系。给定U-Net 解码器输出的原始特征X∈RW×H×C,W、H和C分别为特征图的宽、高和通道数,首先利用Reshape 函数将X转换为图节点矩阵X′∈RWH×C,再利用1×1 卷积和点积运算(Dot-product)构造邻接矩阵。邻接矩阵的计算公式[13]为

式中:⊗表示点积;
θ(·)包含1×1 卷积和Reshape 函数,θ(X)∈RWH×C;
Wθ和Wρ表示邻接矩阵的权重;
diag(ρ())是对角矩阵,表示二维特征图的通道注意力系数,∈R1×1×C是X经过全局平均池化后的特征,ρ包括1×1 卷积和激活函数Sigmoid。最后利用Softmax 函数归一化邻接矩阵。
第二步,图卷积计算。构造动态图(A,X′)后,利用图卷积公式推理对应的结构信息。图卷积公式[9]为

式中:σ为激活函数,W∈RD×D为原始空间的参数矩阵。
2.3 边界注意力网络
虽然本模型利用动态图卷积扩展了U-Net 提取的特征信息,但在主干网络上下采样的过程中,血管的边界信息仍被逐渐弱化,限制了模型的分割性能。文献[18]提出了一种边界注意力网络,其不仅轻量化且能输出高质量的人像分割图像,故本文遵循其思路设计了一种边界注意力网络来加强视网膜血管的边界信息。该网络通过卷积操作将主干网络的输出投影设为2 通道,将其作为边界注意力图。边界注意力损失(Boundary attention loss,BA Loss)引导边界注意力图定位边界区域,边界区域的标注利用传统的无监督形态学方法提取。然后将输入的图像与边界注意力图拼接成3 通道图(原始视网膜图像经过图像预处理后变为单通道),再经过一个卷积序列提取浅层的细节信息,卷积序列包括一个1×1 卷积、批归一化以及激活函数。
2.4 特征融合网络
语义特征是高层次的特征,边界特征是低层次的特征,它们之间在特征表示层次上存在差异,不能简单地通过元素值的累加或通道的拼接来组合它们。故引入文献[19]的特征融合方法,对于不同层次的两种特征,先将它们的通道拼接,后传递到一个卷积序列中,再利用全局池化、两个1×1 卷积以及激活函数来计算卷积序列输出特征的权重向量,然后将权重向量和卷积序列的输出相乘后相加,起到血管像素特征选择和结合的作用,让模型的分割目标聚焦在血管像素上。该模块结构如图3(b)所示。
2.5 损失函数
考虑到视网膜血管分割是二分类问题,故采用二分类交叉熵作为BDGU-Net 的损失函数:


本文的损失函数是分割损失(segmentation loss,Seg Loss)、边界注意力损失的加权和,如式(5)所示,实验表明α=0.6,β=0.4时效果最好。

3.1 实验环境与参数设置
本实验采用Python 语言编程,基于PyTorch 框架实现,模型在配备64 G 内存的Intel Xeon Silver 4114 CPU 和NVIDIA TITAN V 显卡的计算机上运行,部署环境为Windows10 操作系统。网络训练轮次总数设置为50 轮,batch size 设置为32,采用优化算法Adam 训练整体网络结构,初始学习率设置为0.0005,并利用余弦退火策略辅助训练。
3.2 数据集与数据预处理
为了验证BDGU-Net 的有效性,选用DRIVE、CHASEDB1 和STARE 三个公开数据集进行实验,数据集的示例如图4 所示。DRIVE 数据集来自荷兰的一个糖尿病视网膜病变筛查项目,包含40 张分辨率为565 pixels×584 pixels 的RGB 图像,其中33 张图像未显示任何糖尿病视网膜病变迹象,7 张图像显示轻度早期糖尿病视网膜病变迹象;
CHASEDB1 数据集是由Kinston 大学公开的小规模数据集,从14 名儿童的左右眼拍照采集获得,共包含28 张分辨率为999 pixels×960 pixels 的RGB 图像;
STARE 数据集是由加州大学圣地亚哥分校提供的,包含20 张分辨率为605 pixels×700 pixels 的RGB 图像,其中10 张图像为正常眼底图像,其余10 张图像存在不同程度的病变。

图4 视网膜图像Fig.4 Retina image
上述三种视网膜图像受光照或眼部疾病的影响,图像中的血管像素不清晰,本文采用图像预处理策略[6]来突显血管特征,这样更有利于模型提取血管像素的特征。先把原始的RGB 图像转换为灰度图像,对灰度图像归一化后再对其采用对比度受限自适应直方图均衡化(CLAHE)来增强血管与背景之间对比度,最后采用伽马校正增亮图像中亮度较低的血管区域。此外,实验中还对训练数据集进行增强和扩充,将训练集中的输入图像、图像真实标注以及边界标注对应随机裁剪为尺寸为48 pixels×48 pixels 的切片,再对图像随机旋转,最终预处理结果示例见图5。两种数据集分别切片20000 张,前90%用于训练,后10%用于验证。

图5 数据预处理结果图。(a) 预处理图像切片;
(b) 真实标注切片Fig.5 Data preprocessing results.(a) Pre-processed image slices;(b) Ground truth slices
3.3 评价指标
为了定量评估本文的模型,使用F1 (F1-Score,F1)、灵敏度(SEnsitivity,SE)、特异性(SPecificity,SP)、准确性(ACCuracy,ACC)、AUC (Area Under Curve,AUC)这5 个常用指标来评价模型的性能,前4 个指标计算公式如表1 所示。表1 中的TP、FP、FN 和TN 分别是真阳性(正确分割的血管像素),假阳性(错误分割的血管像素)、假阴性(错误分割的背景像素)和真阴性(正确分割的背景像素)。F1 计算公式中的PR 表示TP 占TP 和FP 总和的比例。AUC是ROC 曲线下的面积,以SP 为横坐标,SE 为纵坐标,其值越接近1,表明模型真实性越高。

表1 评价指标Table 1 Evaluation indexes
3.4 实验结果
3.4.1 消融实验
为了验证本文采取的多尺度动态图卷积的有效性以及边界注意力网络的辅助作用,分别在DRIVE、CHASEDB1 和STARE 三个数据集上设计了3 组消融实验,并用U-Net 对这些方法的分割性能进行定量比较,实验结果见表2。图6 对3 组消融实验的实验结果进行可视化,同时在整张图中选择并放大了一些细节,以便更好地观察微小血管和噪声的分割结果。

表2 消融实验结果Table 2 Ablation experiments results

图6 消融实验效果对比图。(a) 原图及原图细节;
(b) 真实标注;
(c) U-Net;
(d) DGU-Net;
(e) BU-Net;
(f) BDGU-NetFig.6 Comparison of ablation results.(a) Original image and details;(b) Ground truth;(c) U-Net;(d) DGU-Net;(e) BU-Net;(f) BDGU-Net
从表2 和图6 可得到如下观察结果:
1) 本方法在STARE 和CHASEDB1 两个数据集上性能提升较明显。与STARE 数据集上的U-Net 相比,仅引入多尺度动态图卷积的U-Net (multiscale dynamic graph convolution U-Net,DGU-Net)的SP、ACC 和AUC 指标分别增加了0.45%、0.12%、0.15%,仅引入边界注意力的U-Net(boundary attention U-Net,BU-Net)相比U-Net 虽无显著的提升,但其F1、SE指标相比DGU-Net 分别增加了0.21%、3.07%。此外,将两者结合的BDGU-Net 平衡了DGU-Net 和BUNet 的SE、SP 指标之间的差异,相比U-Net 的F1、SP、ACC、AUC 指标分别增加了0.89%、0.37%、0.24%、0.24%。在CHASEDB1 数据集上,BDGUNet 比U-Net 的F1、SE、ACC、AUC 指标分别提升了0.28%、0.94%、0.02%、0.02%。
2) 本方法在DRIVE 数据集上性能相较于U-Net提升有限。DGU-Net 的SP 指标增加了0.12%,BUNet 的SE 指标增加了0.22%,BDGU-Net 除SE 指标比U-Net 低0.3%外,其它指标均略高于U-Net。STARE 和CHASEDB1 数据集与DRIVE 数据集相比,噪声较多,有用的特征更难提取。因此BDGU-Net 在复杂的、噪声较多的数据集上拥有更好的表现效果。
3) 单独引入动态图卷积或边界注意力的网络存在局限性。DGU-Net 在三个数据集上的SE 指标都相对较低,BU-Net 则是在SP 指标上相对较低。因为在监督训练中,通常难在SE 指标和SP 指标之间取得平衡,如果提高分割的灵敏度,可能会有更多背景中的非血管像素被识别为血管像素,这是以降低特异性和影响整体准确性为代价的。反之,如果提高分割的特异性,可能会有较多的血管像素被遗漏,也会影响整体的分割准确性。将动态图卷积和边界注意力结合起来的BDGU-Net 则能平衡分割的灵敏度和特异性,使分割的整体准确性得到提高。如图6(d)、图6(e)和图6(f)所示,DGU-Net 能较好地识别噪声而不能更好地保证血管的连通性;
BU-Net 则相反,其能分割出更多的血管,而噪声的判别能力弱;
BDGU-Net 通过结合动态图卷积和边界注意力,使得分割出的结果既能较好地保证血管的连通性又能区分出噪声。
4) 本文还比较了消融实验中不同网络对单张眼底图像分割的平均处理时间,BDGU-Net 在可接受的时间消耗范围内进一步提高了分割的精度。
3.4.2 损失函数权重对比实验
由于本文方法的损失函数包括BA loss 和Seg loss,为了得到一组较好的损失权重α和β,在已有的经验基础上,设定了4 组权重系数在DRIVE 数据集上进行对比实验。由表3 可以看出来,α=0.4,β=0.6 时,网络的分割灵敏度和特异性较平衡,使该模型在F1 和AUC 指标上表现略好,因此本文将第3 组权重系数作为实验超参数。

表3 不同α和β 系数取值分析Table 3 Value analysis of different α and β coefficients
3.4.3 与其它网络的性能对比
为了综合地评估BDGU-Net 的分割性能,将BDGU-Net 与其它网络进行比较,其中包括非专家观测者在三个数据集上的结果,以便显示自动分割算法的优势。结果分为两个方面进行展示,一个是指标对比,见表4,另一个是可视化对比,见图7。
从表4 可知,在DRIVE 数据集上,Iternet 通过mini-UNet 的多次迭代来加深网络,有效提高了血管分割结果的连通性,SE 提高至83.70%,而SP 比本方法低0.15%,且ACC 也略低于本方法;
MLADUNet 采用多层次注意力模块来利用底层详细信息,有效提高了网络区别噪声的能力,SP 提高至97.88%,而SE 比本方法低0.31%。在CHASEDB1 数据集上,Res2Unet 结合多尺度策略和通道注意力机制,并使用后处理方式,有效提高SE 至84.44%,而本方法的SP 相较其高了0.6%,ACC 和AUC 也略高于Res2Unet。在STARE 数据集上,Yang等[22]提出有效的损失函数针对粗细血管进行精确分割,使SE 提高至79.46%,而SP 比本方法低0.79%,ACC 也低了0.46%。从整体来看,本方法的SP 指标表现较好,而SE 指标略逊于其它网络,ACC 和AUC 指标与Iternet 相差不大。结合图7(c)、图7(d)、图7(e)、图7(f)的对比可知,Iternet 和Res2Unet 的血管分割结果的连通性较好,而MLA-DUNet 和BDGU-Net 区分背景中噪声的能力更强。值得注意的是,在血管结构较复杂的区域,BDGU-Net 也能较好地保证分割血管的连通性。综上,BDGU-Net 既能保持分割血管的连通性又能更好地区分背景中的噪声,可以有效地完成视网膜血管分割任务,表现出较好的泛化性和抗干扰能力。

表4 不同网络在DRIVE、CHASEDB1 和STARE 数据集的指标对比Table 4 Index comparison of different networks in DRIVE,CHASEDB1 and STARE datasets

图7 不同网络效果对比图。(a) 原图及原图细节;
(b) 真实标注;
(c) Iternet;
(d) MLA-DU-Net;
(e) Res2Unet;
(f) BDGU-NetFig.7 Comparison of ablation results.(a) Original image and details;(b) Ground truth;(c) Iternet;(d) MLA-DU-Net;(e) Res2Unet;(f) BDGU-Net
本文从U-Net 丢失了大部分全局结构信息和边界信息,难以进一步提取血管特征信息,造成毛细血管分割遗漏和断连的问题出发,提出一种基于改进UNet 的边界注意力辅助的动态图卷积视网膜血管分割模型。该模型在原始空间采用多尺度动态图卷积,捕获特征图更细致的全局结构信息,同时利用简单高效的边界注意力网络辅助主干网络来增强边界细节信息,从而达到改善视网膜血管分割断连或噪声误分类的目的。然而,在实验过程中,为了使边界注意力网络轻量化,只采用单层的神经网络提取浅层的细节信息,使得边界注意力网络表达有限,缺乏对血管边界信息更准确的把握。因此,提高本模型分割视网膜血管边界的精准性将是我们下一步的工作方向。
猜你喜欢动态图注意力边界让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09拓展阅读的边界儿童时代·幸福宝宝(2021年11期)2021-12-21白描画禽鸟(十五)老年教育(2021年11期)2021-12-12白描画禽鸟(十四)老年教育(2021年10期)2021-11-10白描画禽鸟(十二)老年教育(2021年8期)2021-08-21白描画禽鸟(七)老年教育(2021年3期)2021-03-22意大利边界穿越之家现代装饰(2020年4期)2020-05-20论中立的帮助行为之可罚边界证券法律评论(2018年0期)2018-08-31“扬眼”APP:让注意力“变现”传媒评论(2017年3期)2017-06-13A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
