首页 > 心得体会 > 学习材料 / 正文
面向鲁棒性增强的多任务机器阅读理解*
2023-05-06 20:00:12 ℃谭红叶,行覃杰
(山西大学计算机与信息技术学院,山西 太原 030006)
机器阅读理解MRC(Machine Reading Comprehension)是自然语言处理NLP(Natural Language Processing)的一个重要任务,目的是让模型根据篇章,给出相关问题的答案。机器阅读理解任务主要包括抽取式、生成式、完形填空和多项选择等类型。
随着大规模阅读理解数据集的发布(如SQuAD[1]和DuReader[2])以及BERT[3]等预训练模型的发展,阅读理解模型在一些评测任务上已经超过了人类的表现。但是,这些模型的鲁棒性还不太理想距,即在面对噪声和干扰时,模型的性能会显著下降。目前,阅读理解模型的鲁棒性主要表现在过敏感性、过稳定性和泛化能力3个方面[4]。本文只针对过敏感性和过稳定性2方面进行研究。
按照文献[4],过敏感性指当问题语义未发生变化时,如复述问题,模型会预测不同的答案,表现出对复述问题和原问题微小差异的过度敏感。过稳定性是指模型过度依赖字面匹配,无法区分答案所在句和干扰句,从而预测出错误的答案。模型过敏感性和过稳定性的例子分别如表1和表2所示,表中示例的答案为RoBERTa-w-wm-ext-large[5]模型预测的结果。过敏感性样例中,仅在原问题中添加“多少”一词,问题语义并未发生变化,但模型预测错误;
过稳定性样例中,干扰句(下划线所示句子)并不包含问题的焦点(总部在哪),但是包含与问题相同的片段 “中国光大银行成立”,导致模型抽取了错误的答案。上述2个例子表明,模型无法对给定的篇章和问题进行充分的理解。

Table 1 Over-sensitivity example表1 过敏感性样例

Table 2 Over-stability example表2 过稳定性样例
为了解决上述问题,本文提出了一种面向鲁棒性增强的多任务抽取式阅读理解模型。该模型主要思想为:(1)将答案抽取任务作为主要任务,同时引入证据句判断和问题分类作为辅助任务;
(2)使用硬约束的多任务学习方法,在训练阶段,通过共享不同任务之间的编码器,使模型在抽取答案的同时加深对问题和篇章的理解。在专门的鲁棒性数据集上的实验结果表明,本文所提模型获得了比基线模型更好的结果,可以有效地缓解模型的过敏感性和过稳定性,提升模型的鲁棒性。
2.1 机器阅读理解
阅读理解数据集的发展极大推动了机器阅读理解技术的进步。例如,斯坦福大学通过众包方式推出了大规模抽取式阅读理解数据集SQuAD(StanfordQuestionAnsweringDataset)1.0,其答案是原文中的一个连续片段。随着各种模型性能的不断提高,研究人员开始推出不同的数据集以增强模型的能力。Rajpurkar等人[6]提出了SQuAD2.0,在SQuAD1.0的基础上,在数据中添加了不可回答问题,需要模型具有判断问题是否可以回答的能力。MSMARCO(MicroSoftMAchineReadingCOmprehension)[7]和DuReader是2个来自搜索领域的数据集,其中每条数据的篇章包含多个段落,需要模型从多个段落中抽取出答案,并具有阅读长文本的能力。在CoQA(ConversationalQuestionAnswering)[8]数据集中,数据是通过模仿人类的对话构建的,需要模型对人类的日常交流用语有深刻的理解。HotpotQA[9]数据集要求模型根据篇章中的多个部分经过多跳推理得到最终答案。DROP(DiscreteReasoningOverParagraphs)[10]数据要求对文本篇章进行数字推理后回答问题。常识问答数据集CommonsenseQA(CommonsenseQuestionAnswering)[11]需要模型利用常识或外部知识来回答问题。DuReader-robust数据集是在DuReader的基础上构建的抽取式阅读理解数据集,其中问题均来自搜索引擎中的用户搜索,包括金融、教育、医疗等多个领域,用于测试模型的鲁棒性。李烨秋等人[12]为了测试模型鲁棒性的各个具体方面,在DuReader-robust和DuReader的基础上分别针对敏感性、过稳定性和泛化能力构建了3个测试集。
早期的机器阅读理解模型都是基于特征的。Hirschman等人[13]通过词袋模型,对篇章和问题进行抽取,然后对篇章和问题进行匹配得到答案。Riloff等人[14]通过人工设计的一组规则对篇章和问题进行匹配打分,选取分数最高的句子作为答案。但是,这些方法只能解决简单问题,当数据更加复杂,长度更长,篇章和问题的表达更加多样时,性能会显著下降。
随着深度学习的蓬勃发展以及大规模数据集的不断推出,机器阅读理解技术开始向深度学习发展。Hermann等人[15]通过在LSTM(LongShort-TermMemory)中加入注意力机制,提出了AttentiveReader模型。Seo等人[16]首次提出了双向注意力流网络BIDAF(BI-DirectionalAttentionFlow),采用多阶段、层次化处理,可以捕获原文不同粒度的特征,在SQuAD等数据集上获得了最优的性能。Wang等人[17]对机器阅读理解任务进行分层建模,构建了R-net网络,在一些数据集上的性能超过了人类的。深度学习技术不需要人工进行特征构建,且可以通过注意力机制自动关注篇章和问题中的重要部分,在一些数据集上取得了很好的性能。
近年来,各种大规模预训练语言模型成功运用到了机器阅读理解任务。如:ERNIE1.0(EnhancedRepresentationthroughkNowledgeIntEgration)[18]在BERT(BidirectionalEncoderRepresentationfromTransformers)的基础上将随机掩码策略替换为实体和短语级掩码来学习额外知识;
RoBERTa(RobustlyoptimizedBERTpretrainingapproach)[19]主要通过动态的掩码策略,并且使用了更大规模的数据,获得了比BERT更好的性能;
ALBERT(ALiteBERT)[20]将下一句预测任务替换为句子顺序预测任务,降低了参数量,在保证模型性能的同时训练速度更快;
BERT-wwm(BERTwholewordmasking)[5]使用全词掩码,使模型可以学习到整个词的语义信息。但研究表明,这些模型的鲁棒性仍不太理想。
2.2 多任务学习
多任务学习是近年来训练模型常用的一种学习方法,通过将模型在多个任务上进行训练,挖掘任务之间的关系,使模型可以将其他相关任务的知识应用到目标任务,从而提升模型的泛化能力。多任务学习主要有硬约束和软约束2种框架。硬约束是指模型在多个任务之间共享表示,在模型的输出层针对不同的任务分别构建不同的输出。软约束中不同的任务使用不同的网络,并且参数不同。在网络之间,使用正则化的方法来约束参数之间的相似化。通过多任务学习可以降低模型的过拟合,提高模型的鲁棒性。
Xia等人[21]设计了2个辅助的关系感知任务来预测2个单词之间是否存在关系及其关系类型,通过多任务学习的方式提升了模型的理解能力,获得了更好的性能。李烨秋等人[12]结合答案抽取和掩码位置预测任务构建了多任务学习模型。Liu等人[22]提出了MT-DNN(Multi-TaskDeepNeuralNetworks)模型,通过使用大量不同任务的数据来学习任务之间的相关知识,以帮助模型适应新的领域和任务。钱锦等人[23]在生成式阅读理解中,通过将答案抽取和问题分类作为辅助任务进行多任务学习,在多个数据集上获得了最优的性能。本文通过多任务学习的方式,实现了信息共享,提高了模型的理解能力,提升了模型的泛化能力。
3.1 任务定义
本文针对抽取式阅读理解进行研究,本节给出了抽取式阅读理解、证据句判断和问题分类的形式化定义。
(1)抽取式阅读理解。问题和篇章分别被表示为Q={q1,q2,…,qn}和D={d1,d2,…,dm},其中n和m分别表示问题和篇章的字数(包括标点符号)。目的是预测一个答案A={ai,…,aj},A为篇章中的一个片段,i和j分别表示该片段的起始位置和结束位置。答案计算如式(1)所示:
f1(Q,D)=argmaxP(A|Q,D)
(1)
(2)证据句判断。证据句是指能够为回答问题提供事实证据的句子。本文将答案所在句视为证据句。将篇章表示为句子集合S={s1,s2,…,sk},k表示篇章中的句子数。证据句判断任务旨在判断篇章中最有可能为证据句的句子,具体计算如式(2)所示:
f2(Q,S)=argmaxP(su|Q,S)
(2)
其中,su表示第u个句子。
(3)问题分类。定义为通过问题和篇章来预测问题的所属类别,具体计算如式(3)所示:
f3(Q,D)=argmaxP(yc|Q,D)
(3)
其中,yc表示第c个类别标签。
本文多任务学习模型的整体框架如图1所示,主要包括4个部分:编码器、答案抽取模块、证据句判断模块及问题分类模块。

Figure 1 Architecture diagram of machine reading comprehension model based on multi-task learning图1 基于多任务学习的机器阅读理解模型架构图
3.2 编码器
该部分的主要功能是对问题和篇章进行编码,通过大规模预训练语言模型编码器得到问题和篇章之间的交互表示。
预处理中,对输入的问题和篇章进行分词,然后标记证据句所在位置。在标记证据句的过程中,本文将篇章进行分句处理,并删去长度小于3的句子(视为噪声)。将模型的输入处理成“[CLS]+问题+[SEP]+篇章+[SEP]”的格式,其中,[CLS]和[SEP]为特殊分隔符;
然后对字向量ET、文本向量ES和位置向量EP进行求和,得到预训练模型的输入。具体计算如式(4)所示:
Input=ET+ES+EP
(4)
在此基础上,将Input经过预训练语言模型后得到最后的表示H={h1,h2,…,hl},H∈Rl×D,其中,hk是每个字符的向量表示,l是整个输入的长度,D是向量的维度,篇章表示部分记作Hp∈Rm×D。具体计算如式(5)所示:
H=Model(Input)
(5)
其中,Model为预训练语言模型编码器。具体使用RoBERTa-wwm-ext-large预训练模型,因为它结合了RoBERTa和BERT-wwm的优点,在许多任务上都有着优异的表现。
3.3 模块介绍
(1)答案抽取模块。该模块根据编码器得到的篇章表示Hp来抽取答案。首先,篇章表示Hp通过2个不同参数的线性层后分别得到答案开始位置和结束位置未归一化的概率,然后经过softmax进行归一化,最终分别得到每个位置作为开始位置和结束位置的概率s_logit和e_logit,具体计算如式(6)和式(7)所示:
s_logit=softmax(f1(Hp))
(6)
e_logit=softmax(f2(Hp))
(7)
其中,f1和f2是有可训练参数的线性层,s_logit∈Rm和e_logit∈Rm由2个不同的线性层得到。
(2)证据句判断模块。该模块与答案抽取模块共享编码器,在经过预训练模型后,得到表示H,取出[CLS]处的聚合表示h[CLS],首先通过线性层,再通过softmax函数进行归一化,得到每个句子作为证据句的概率sentence_logit,如式(8)所示:
sentence_logit=softmax(f3(h[CLS]))
(8)
其中,f3是有可训练参数的线性层,sentence_logit∈Rk,h[CLS]∈RD。
(3)问题分类模块。问题分类任务旨在预测问题所属的类别。使用整个文本的聚合表示h[CLS],通过一个独立的线性层,得到问题属于每个类别的概率,最后通过softmax函数进行归一化,如式(9)所示:
qc_logit=softmax(f4(h[CLS]))
(9)
其中,f4是有可训练参数的线性层,qc_logit∈R4。
3.4 优化函数
本文所提出的多任务模型共包括答案抽取、证据句判断和问题分类3个子任务,均使用交叉熵损失函数,具体损失函数如式(10)~式(12)所示:
ye·log(e_logit)]
(10)
esp_loss=ysen·log(sentence_logit)
(11)
(12)
其中,ys和ye分别表示真实答案的起始位置和结束位置的概率向量,ysen为真实的证据句标签向量,C=4表示问题的类别,yc表示真实的类别标签,yqc表示模型的预测标签类别。
本文采用多任务学习的方法,使用硬共享机制,多个任务之间共享输入层和模型层,通过损失函数实现3个任务的结合,可以通过调整辅助任务的权重参数来控制辅助任务对模型总体性能的影响,从而获得更好的性能。模型总的损失函数如式(13)所示:
total_loss=mrc_loss+
α*esp_loss+β*qc_loss
(13)
其中,α、β分别为证据句判断和问题分类任务的损失权重,mrc_loss、esp_loss和qc_loss分别为答案抽取、证据句判断任务和问题分类任务的损失。
4.1 数据集
本文实验使用DuReader-robust作为训练集,该数据集是Tang等人[4]在大规模中文阅读理解数据集Dureader的基础上针对鲁棒性问题进行手工标注构建的,是一个抽取式阅读理解数据集,其答案为篇章中的一个连续片段。本文在DuReader- robust的训练集上进行训练,共14 520条。由于该测试集未公开,使用李烨秋等人[12]在DuReader-robust基础上构建的过敏感测试集和过稳定测试集,过敏感测试集共2 703条,过稳定测试集共490条。具体信息如表3所示。

Table 3 Dataset information表3 数据集信息
4.2 评价指标
本文实验的评价指标使用F1值和EM值进行评估。F1值用来计算模型预测结果和标准答案之间的重合率,EM值用于检测它们之间是否完全匹配。F1值和EM值的计算分别如式(14)和式(15)所示:
(14)
(15)
其中,a′i和a′j分别为预测答案的起始和结束位置,ai和aj分别为标准答案的起始和结束位置。
4.3 基线模型
(1)BERT[3]:基于多层Transformer编码的深度双向预训练模型。该模型通过在大规模语料库上进行预训练,获得了丰富的上下文信息;
在预训练中使用了掩码语言模型和下一句预测2个无监督任务进行训练。BERT在多个NLP任务中都有优异表现。
(2)ERNIE1.0[18]:与BERT相比,ERNIE1.0加入了实体级掩码和短语级的掩码策略,通过不同的掩盖策略增强使模型获得了更多的知识。
(3)ALBERT[20]:ALBERT是在BERT的基础上,通过参数约简和句子顺序预测任务来改进的预训练模型,在多个任务上超越了BERT的性能。
(4)RoBERTa-wwm-ext-large[5]:Cui等人[5]使用中文维基百科、新闻、问答等数据训练了RoBERTa-wwm-ext-large预训练模型。与BERT相比使用了更大规模的数据,还结合了RoBERTa和BERT-wwm的优点,在预训练阶段没有采用下一句预测任务,并且使用了全词掩码(Whole Word Masking )策略。
4.4 实验细节
在问题分类中,Dureader-robust数据集中的问题均为实体型问题。经过对数据集进行分析,对事实型问题又进行了进一步的划分,将问题分为4大类:时间类、数字类(除时间以外)、地址人名类和其他。
主要参数设置:初始学习率为3e-5,字向量维度为 768,隐藏状态大小为 768,隐藏维度为768,最大输入长度为256,doc_stride为128。实验训练批次大小为32,一共训练3轮,权重参数α、β均为0.1。
5.1 实验结果
本文模型和基线模型在过敏感测试集和过稳定测试集上的结果如表4所示。从实验结果可以看出,本文模型对比基线模型在2个测试集上均有性能提升。在过敏感测试集上,F1指标比性能最好的基线模型RoBERTa-wwm-ext-large提高了4%,EM值提升了2.74%。在过稳定测试集上本文模型对比基线模型F1值提高了0.97%,EM值提高了1.63%。说明通过多任务学习,模型的理解能力得到了提升,模型的过敏感性和过稳定性得到了一定的缓解,具有更好的鲁棒性。还可以看出,ERNIE1.0和ALBERT对比BERT模型在过敏感测试集和过稳定测试集上的F1值均有提高,原因是由于ERNIE1.0通过加入不同的掩码策略,捕获到了更多的词汇和语义知识,ALBERT通过多个层间参数共享、Embedding分解以及使用句子顺序预测替代下一句预测任务,不仅减少了参数,还使得模型性能更好。RoBERTa-wwm-ext-large预训练模型不仅使用了更大的训练数据,还结合了多个模型的优点,在3个基线模型中效果最好。
5.2 消融实验
为了验证每个辅助任务的有效性,本文进行了消融实验,在过敏感测试集和过稳定测试集上的消融实验结果如表5所示。可以看出,本文模型中的2个辅助任务对于提升模型鲁棒性均有帮助。除去证据句判断任务后,模型在过敏感测试集和过稳定测试集上F1值分别下降了2.12%和0.74%,这是由于证据句判断任务为模型提供了篇章理解,使模型更加关注答案所在句,可以减少鲁棒性问题带来的干扰,尤其是过敏感性问题。而去除问题分类任务,模型在过稳定测试集上的性能显著下降,F1值下降了约2.45%,说明问题分类任务为模型提供了更多的问题信息,可以辅助模型选择正确的答案类型,问题分类任务能更好地改善模型的过稳定性。
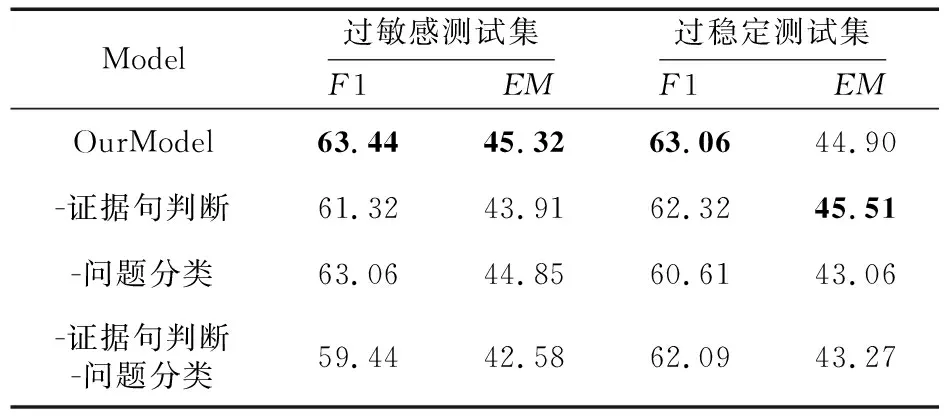
Table 5 Model ablation experiment results on test sets表5 模型在测试集上的消融实验结果
5.3 样例分析
表6给出了2个样例。在样例1中,本文模型可以正确识别问题类别并回答正确,而RoBERTa-wwm-ext-large模型回答错误。在样例2中,由于问题与干扰句(下划线所示句子)高度相似,导致模型从干扰句中抽取了错误答案,但本文模型并未受到干扰句的影响,表明本文所提模型具有更好的鲁棒性。

Table 6 Comparison of model prediction results表6 模型预测结果对比
本文主要针对阅读理解模型的过敏感性和过稳定性进行了研究。通过多任务学习的方法,将证据句判断和问题分类融入到模型中,从问题和篇章2方面增强了模型的理解能力。实验结果表明,本文模型有效地提高了鲁棒性,在过敏感测试集和过稳定测试集上均获得了比基线模型更好的性能。在未来的工作中,将对鲁棒性问题进行更深层次的研究,探索提高鲁棒性更有效的方法。
猜你喜欢多任务集上鲁棒性Cookie-Cutter集上的Gibbs测度数学年刊A辑(中文版)(2020年2期)2020-07-25荒漠绿洲区潜在生态网络增边优化鲁棒性分析农业机械学报(2020年2期)2020-03-09链完备偏序集上广义向量均衡问题解映射的保序性数学物理学报(2019年6期)2020-01-13分形集上的Ostrowski型不等式和Ostrowski-Grüss型不等式井冈山大学学报(自然科学版)(2019年4期)2019-09-09基于确定性指标的弦支结构鲁棒性评价中华建设(2019年7期)2019-08-27基于中心化自动加权多任务学习的早期轻度认知障碍诊断中国生物医学工程学报(2019年6期)2019-07-16基于判别性局部联合稀疏模型的多任务跟踪自动化学报(2016年3期)2016-08-23基于非支配解集的多模式装备项目群调度鲁棒性优化项目管理技术(2016年12期)2016-06-15非接触移动供电系统不同补偿拓扑下的鲁棒性分析西南交通大学学报(2016年6期)2016-05-04基于多任务异步处理的电力系统序网络拓扑分析电测与仪表(2016年5期)2016-04-22猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
