首页 > 心得体会 > 学习材料 / 正文
基于细粒度实体分类的对比研究
2023-01-15 12:10:07 ℃周 祺, 陶 皖
(安徽工程大学 计算机与信息学院,安徽 芜湖 241000)
在自然语言处理(Natural Language Processing,NLP)中,实体分类是指为每一个实体分配一个指定的标签,这是一项非常重要而又基础的工作,在知识图谱的构建中扮演着重要的角色,作为构建知识图谱的基础性工作,实体分类的质量好坏直接影响整个知识图谱的可信度和可用性。传统的命名实体识别[1](Name Entity Recognition,NER)作为实体抽取的子任务为后续的工作奠定了坚实的基础,即将文本中的指称(即实体在具体上下文中的一段指代)抽取出来,并判断其在上下文中的类型为人、位置、组织、其他等粗粒度类型的过程。近年来,传统的命名实体识别被扩展到更深层次的细粒度实体类型。由于上游分配粗粒度的实体类型,后续选取实体间的候选关系就会复杂,相应的关系抽取任务会变得愈加困难,于是就促进了细粒度实体分类任务的研究。通过细粒度实体分类概念的引入,有效地将粗粒度的实体类型标签细化、层次化,从而使得下游任务(关系抽取、事件抽取、问答系统、实体推荐等)的工作效率降低,提高工作效率。
细粒度实体分类[2](Fine-grained Entity Typing,FET)在给定实体指称的情况下,依据其上下文给实体指称赋予一个或多个实体类型。在FET中,能够对目标实体类型进行更细致地划分,同时保证类型之间存在一定的层次关系。细粒度的实体类型表示可以为其他 NLP 任务提供更多的语义信息,有助于增强后续关系抽取和事件抽取等任务的指示性,提高问答系统、实体推荐等下游任务的工作效率。
传统的FET任务通常采用人工标注语料的方式,费时费力。随着实体类型数据集的不断增大,人工标注类型标签的难度增加、代价高昂,而且容易出错。为此将深度学习中的神经网络方法[3-5]运用到细粒度实体分类领域,可充分利用深度学习方法从大量训练语料中学习不同语料的语义特征,代替人工标注,从而提高细粒度实体分类的准确率。然而现有的基于神经网络的细粒度实体分类模型大多需要远程监督[6](Distant Supervision)的参与,由于远程监督链接到知识库中实体指称的所有标签,召回过程不可避免地会引入噪声问题,但过多的噪声使得训练模型性能变差,影响分类精度。为了缓解噪声标签产生的负面影响,有学者提出细粒度实体分类的标签噪声处理方法,如剪枝噪声标签[7]、划分数据集[8]等,能够有效地改善FET任务处理噪声标签的鲁棒性,促进了细粒度实体分类的进一步研究。
Lee等[9]首次在问答系统中对细粒度命名实体识别任务进行处理,提出利用条件随机场(Conditional Random Field,CRF)检测命名实体的边界,并使用最大熵(Maximum Entropy,ME)对实体进行分类,同时他们定义了147种细粒度的命名实体类型。但对于细粒度的语义命名实体识别与分类还没有系统的研究,因此Ekbal等[10]依赖大型文本语料库,获取细粒度的语义类型和实例,构建了细粒度命名实体识别与分类的数据集。为了扩展命名实体类型表示,Sekine[11]使用日本百科全书的知识创建了200种扩展命名实体类型,其中包含了扩展命名实体的丰富描述以及一系列的属性设计。与上述工作不同的是,Ling等[2]针对细粒度实体分类任务,创建了经典数据集FIGER,将本来只划分为5~6种类型的实体扩展到112种类型标签,通过远程监督的方式,获取维基百科词条中的实体类型信息,并根据CRF划分实体边界,最终由感知机算法完成多类别多标签任务,开辟了针对细粒度实体分类领域的新方法,为后续的研究工作提供了便捷。针对FIGER数据集中类型数量相对较少,一个实体通常只映射到一个类型的问题,Yosef等[12]提出了在不同层次、数百种类型的基础上,利用层次分类法对来自WordNet中的大量实体类型自动计算扩展实体指称的类型,得到了非常精细的505种实体类型,形成了一个多标签的分级分类系统HYENA。略显不足的是,HYENA中的类型均来自WordNet中的子集,缺少重要的实体类型。为了弥补这一缺陷,FINET[13]不再限制实体类型,提取整个WordNet中超过16 000种类型,其中包括个人、组织和位置等。以往的研究大多依赖于人工标注的特征,而Dong等[14]首次采用深度学习的方式,使用词嵌入作为特征,通过监督方法将网页中的内容提取与现有知识库中的先验知识相融合,能够有效地提高识别实体类型的准确率。上述工作均为细粒度实体分类领域的研究奠定了基础,证实了其存在价值及重要意义,并为后续实验创建了基础实验数据集。
由于实体指称在知识库中所对应的类型较多,一般采用人工标注的方式保证样本的准确率,但这样人工成本耗费过多。随着知识库规模的急速增长,人工标注的方式已经无法跟上数据更新的速度,因此使用神经网络方法代替部分人工过程,以便提高细粒度实体分类的准确率和召回率。
2.1 基于卷积神经网络的细粒度实体分类
卷积神经网络(Convolutional Neural Network, CNN)[3]通常由输入层、隐藏层和输出层组成。首先在输入层处理多维数据,其次在隐藏层中可以利用卷积层、池化层和全连接层对输入数据进行特征提取、特征选择以及信息过滤,最后在输出层使用逻辑函数或softmax函数输出分类标签。
为提取实体信息用于知识库补全领域,Jia等[15]提出一种学习实体指称及其上下文联合表示的卷积神经网络联合模型(Convolutional Neural Network Joint Model, CNNJM),在词嵌入平均化的基础上进行一层卷积,通过最大池化操作获得最重要的特征,类似思想也用于句子分类[16]、事件抽取[17]领域中,CNNJM更关注于实体本身的特征信息。然而实体指称的上下文蕴含着更丰富的信息,于是Murty等[18]通过对实体指称的上下文及位置信息进行卷积操作,之后进行最大池化处理,提取更多的上下文特征信息,有利于提高细粒度实体分类的准确率。
2.2 基于循环神经网络的细粒度实体分类
考虑CNN网络层次之间的关联性不强,且无法很好地学习自然语言数据的长距离依赖和结构化语法特征,因此卷积神经网络在后期自然语言处理中的应用要少于循环神经网络(Recurrent Neural Network,RNN)[4]。RNN以序列数据为输入,在序列的演进方向进行递归操作,将所有循环单元按链式连接,主要包括输入层、隐藏层和输出层,隐藏层中添加了记忆细胞模块。与CNN有所不同的是,CNN隐藏层之间的节点是无连接的,而RNN会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点是有连接的。
研究证明,RNN对符合时间顺序、逻辑顺序等序列特性的数据十分有效,能挖掘数据中的时序信息以及语义信息,但是由于权重累加过大,无法进行长期记忆的学习,可能导致结果失真、运算效率降低,因此长短期记忆(Long Short-Term Memory,LSTM)[5]网络应运而生。LSTM网络通过精妙的输入门、遗忘门和输出门控制将短期记忆与长期记忆结合起来,选择性地记录或遗忘输入的信息,有利于提取重要的特征信息,得到更好的实验结果。
为了达到更高精度识别实体、细化实体类型的效果, Shimaoka等[19]创新地使用LSTM学习实体指称的上下文表示,同时引入注意力机制,为双向长短期记忆网络(Bi-directional LSTM,BiLSTM)编码的上下文序列计算注意力权重,识别更具表达类型标签的信息,并使分类行为更具可解释性。随后,Shimaoka等[20]将先前未考虑到的人工标注特征与模型学习到的特征结合在一起形成互补的信息,再次提高细粒度实体分类任务的准确率和召回率。根据知识库(Knowledge Base,KB)中有关实体的丰富信息,Xin等[21]提出了基于知识库的注意力神经网络模型。该模型将实体指称的上下文向量投入BiLSTM,通过计算注意力权重,输出上下文表示。与此同时,还将注意力机制运用到实体指称表示和来自知识库的实体表示,既考虑了实体指称与上下文的关系,也能够把实体指称与知识库中相关实体的关系代入其中。鉴于FIGER、OntoNotes中的实体类型仍不够精细,Choi等[22]提出了超细粒度实体分类(Ultra-Fine Entity Typing,UFET),采用两层独立的BiLSTM处理上下文,并通过注意力机制和多层感知机(Multi-layer Perceptron,MLP)算法生成实体指称的上下文表示,有效地改进了细粒度实体分类的效果。同时创建了三层的超细粒度实体类型数据集UFET,包括9种通用类型、121种细粒度类型和10 201种超细粒度类型。
由于LSTM的强大功能,将其应用到自然语言处理领域的效果良好,此后的细粒度实体分类任务大多采用LSTM处理实体指称的上下文向量,以获取重要的上下文语义特征,为实体指称分配细粒度实体类型提供指示性信息。
现有的大多数细粒度实体分类模型采用基于神经网络的实体分类模型,利用远程监督方法首先将语句中的实体指称链接到知识库中的实体,再把KB中实体的所有类型标签分配给实体指称的候选类型集。由于采用远程监督方法,分配类型标签时未考虑实体指称的上下文,会将无关的实体类型标签引入训练数据中,把这些无关的类型标签视为标签噪声。远程监督在对实体指称进行细粒度实体分类时会受到标签噪声和相关类型的限制,从而加大了后续分类模型对实体指称进行正确分类的难度,严重影响了细粒度实体分类模型的准确性和可信性。因此,对标签噪声进行有效处理,能净化训练数据集,使分类模型训练时能够高效学习实体类型标签,优化分类模型的准确性。本节介绍基于噪声处理的细粒度实体分类,主要分为基于规则划处理数据集、优化损失函数两部分。
3.1 基于规则处理数据集
由于FIGER[2]和HYENA[12]的训练集和测试集都是从Wikipedia中利用远程监督自动获取的,未经过任何的过滤和挑选。因此Gillick等[7]通过在训练集上采用启发式剪枝的方法来解决训练数据中出现的多余标签,用于完善训练数据的启发式方法删除了与单个实体关联的同级类型,仅保留了父类型;
删除与在该类型集上训练的标准粗粒度类型分类器的输出不一致的类型;
删除出现次数少于文档中的最小次数的类型。经过启发式规则能有效地改善人工标注数据的性能。但通过启发式规则剪枝噪声,会导致训练数据样本量减少,影响模型的整体性能,因此Ren等[8]提出自动细粒度实体分类模型(Automatic Fine-grained Entity Typing,AFET),对带有正确类型标签的实体指称和带有噪声标签的实体指称分别进行建模训练,另外还设计了一种新的部分标签损失算法,能利用噪声候选类型集中与实体指称相关的候选类型建模真实类型,并利用为指称所提取的各种文本特征逐步估计出最佳类型。然而,去噪过程和训练过程没有统一,这可能会导致误差传播,带来更多的复杂性。于是Zhang等[23]提出一种基于路径的注意力神经网络模型( Path-based Attention Neural Model,PAN )可以选择与每种实体类型相关的语句,动态减少训练期间每种实体类型的错误标记语句的权重,通过端到端的过程有效地减少类型标签噪声,并能在有噪声的数据集上实现更好的细粒度实体分类性能。为进一步改进噪声数据处理的效果,Abhishek等[24]参考AFET,构建了AAA模型,将训练数据分为干净集和噪声集,若训练数据实体的多个标签属于同一类别将其分为到干净集,反之则划分到噪声集。同时能联合学习实体指称及其上下文表示,并且在训练数据时使用变形的非参变量铰链损失函数,还运用迁移学习提高模型的有效性。
3.2 优化损失函数
3.2.1 铰链损失函数
铰链损失(Hinge Loss)函数是机器学习领域中的一种损失函数,可用于“最大间隔(Max-margin)”分类,经典公式如下:
L(y,y′)=max(0,marg in+y′-y)
(1)
其中,y是正例标签的得分,y′是负例标签的得分,两者间的差值用来预测两种预测结果的相似关系。
以往对细粒度实体分类中训练数据的噪声进行处理时将其剪枝或划分为不同的数据集,但是未充分考虑到细粒度实体分类系统处理噪声数据时的鲁棒性。于是Yogatama等[25]在WSABIE[26]的基础上,提出了学习特征和标签联合表示的模型K-WSABIE,将特征向量和标签映射到同一低维空间,学习特征和标签的联合表示。与此同时,在K-WSABIE中引入铰链损失函数,如下:
L(y,y′)=R(rank(y))max(0,1-y+y′)
(2)
其中,y和y′含义如上,R(rank(y))使得正例标签的得分高于负例标签,彼此之间不产生竞争,有效提高模型应对噪声数据的鲁棒性。
为减少与上下文无关的噪声标签影响,Dai等[27]利用实体链接[28-29]改进细粒度实体分类模型,根据上下文、指称的字符以及用实体链接从知识库中获得的类型信息结合在一起灵活地预测类型标签,同时设计了一个变形的铰链损失函数防止训练后的模型过拟合弱标记数据,如下:
L(y,y′)=max(0,1-y)+λ·max(0,1+y′)
(3)
其中,y和y′含义如上,λ为超参数,灵活地调整对负例标签的惩罚。
由于以往方法对实体指称独立建模,仅依据上下文分配实体类型标签,可能会妨碍信息跨越句子边界传递信息,为此Ali等[30]提出了一个基于边缘加权的注意力图卷积网络(Fine-Grained Named Entity Typing with Refined Representations,FGET-RR)。FGET-RR不仅分析具体的上下文信息,还侧重于对语料库中特定标签的上下文进行分析。另外,对于干净数据和含噪声数据分别设计铰链损失函数,如下:
Lclean=ReLU(1-y)+ReLU(1+y′)
(4)
Lnoisy=ReLU(1-y*)+ReLU(1+y′)
y*=arg maxy
(5)
3.2.2 交叉熵损失函数
交叉熵损失函数(Cross Entropy Loss)在机器学习中主要用于衡量真实概率分布与预测概率分布之间的差异性,交叉熵的损失值越小,代表模型的预测效果就越好,如下:

(6)
其中,p为真实概率分布,q为预测概率分布。
与前人不同的是,Xu等[31]对原本细粒度实体分类的多标签分类问题,转换为单标签分类问题,并且使用变形的交叉熵损失函数和分层损失函数来分别处理无关噪声标签以及过于具体的标签。变形的交叉熵损失函数根据实体指称的上下文自动过滤不相关的类型,如下:
(7)
其中,N为实体指称的数量,p(yi)为预测的概率分布,当实体指称对应多个类型标签时,只选取具有最高概率的标签。分层损失函数能调整预测相关类型的步骤,使模型了解实体类型的层次结构,预测真实类型的父类型会比其他不相关的类型效果好,从而减轻过于具体标签的消极影响。
在NFETC[31]的基础上,为避免文献[8、24、31]中使用部分标签损失的确认误差累积影响,Chen等[32]提出使用压缩隐空间簇(NFETC-Compact Latent Space Clustering,NFETC-CLSC)来规范远程监督模型。对于干净的数据,压缩相同类型的表示空间;
对于有噪声的数据,通过标签传播和候选类型约束来推断它们的类型分布,激发出更好的分类性能。以KL散度计算远程监督损失值,如下:
(8)
其中,B为干净数据训练时的批大小,J为目标类型数,yij为预测类型分布。
针对文献[31]将细粒度实体分类转化为单标签分类问题,此方法未必完全正确,于是Zhang等[33]提出了一种统一处理所有训练样本的基于概率自动重标记的方法(NFETC-Automatic Relabeling,NFETC-AR)。在训练过程中为每个样本分配所有候选标签上的连续标签分布,并且将连续标签分布作为训练参数的一部分通过反向传播算法进行更新,达到预测分布与伪真标签分布之间的最小化KL散度(Kullback-Leibler Divergence)的目的,最后取伪真标签分布中值最大的标签作为唯一的伪真标签,具体KL散度如下:
(9)
其中,N为实体指称的数量,T为类型数,pij为连续标签分布。
不仅要考虑标签的层次结构,Xin等[34]从语言角度提出了以无监督的方式,运用标签含义衡量上下文句子与每个远程监督获得的标签之间的兼容性,将模型分为两部分:实体分类模型(Entity Typing Module,ET)和语言增强模型(Language Model Enhancement, LME)。ET 通过交叉熵函数,最小化真实类型概率与预测类型概率的差异,如下:
(10)
LME利用一个语言模型和一组标签嵌入来判断标签与上下文句子之间的兼容性,减少由远程监督产生的噪声。

(11)
在本节将详细描述细粒度实体分类任务中所用到的实验数据集、评价指标以及部分文献的实验结果对比。
4.1 常用数据集
在细粒度实体分类任务中,主要用到以下3个数据集:FIGER[2]、OntoNotes[7]、BBN[37]。其中FIGER和BBN为2层数据集,OntoNotes为3层数据集,其他数据如表1所示。
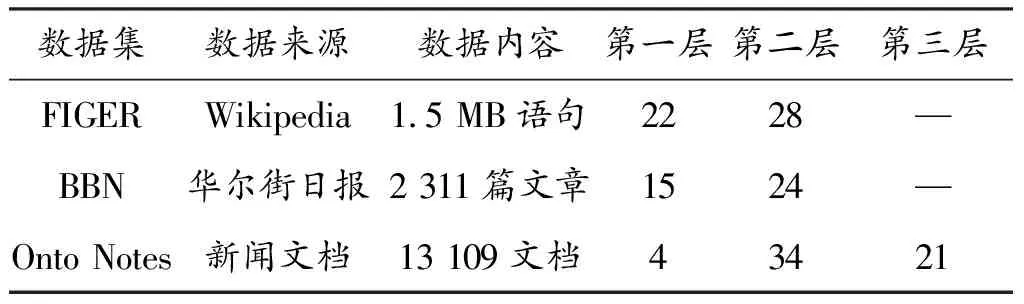
表1 细粒度实体分类中常用的数据集
4.2 评价指标
评价细粒度实体分类任务沿用Ling等[2]提出的3个指标:准确率(Accuracy,Acc)、宏观平均F1值(Macro-averaging F1-Measure,Macro F1)以及微观平均F1值(Micro-averaging F1-Measure,Micro F1):
(12)
宏观平均F1值是宏观精确率(Macro Precision,Pma)和宏观召回率(Macro Recall,Rma)的平均值。
(13)
(14)
微观平均F1值是微观精确率(Micro Precision,Pmi)和微观召回率(Micro Recall,Rmi)的平均值。
(15)

(16)
4.3 细粒度实体分类方法的对比研究
为比较以上细粒度实体分类方法的性能表现,本文在相同数据集上将各种方法的实验结果列出进行对比研究,如表2所示。选取的细粒度实体分类方法有以下几类:经典方法FIGER[2]、HYENA[12];
基于RNN的细粒度实体分类方法Attentive[19];
对于噪声处理方面,选取启发式剪枝噪声方法CFGET[7],根据规则划分数据集方法AFET[8]和AAA[24],优化铰链损失函数方法FGET-RR[30],优化交叉熵损失函数方法NFETC[31]、CLSC[32]、AR[33]和LME[34]进行对比分析。
由表2可以看出,早期提出的经典细粒度实体方法(如FIGER、HYENA)主要集中在将原始的粗粒度的命名实体类型扩展到细粒度的实体类型识别上,因此在3个数据集上的性能表现较差,特别是HYENA将所有实体类型划分为9层、共计505种的细粒度类别,难度大,因此最终的准确率、Macro F1值和Micro F1值相对较低。引入神经网络模型后,Attentive创新性地使用LSTM和注意力机制,使得模型的性能表现有大幅提高,在FIGER数据集上,准确率提高约12%,Macro F1值提高约10%,Micro F1值提高约10%;
在OntoNotes数据集上,准确率能够提升近15%,Macro F1值提高近14%,Micro F1值提高近7%。在处理标签噪声方面,CFGET采用剪枝训练集噪声的方法,但由于训练集规模的减小,在数据集上的表现较差,与FIGER实验结果相近。而AFET和AAA根据类型路径划分干净数据集和含噪声数据集,能够有效地提高实体分类的准确率、Macro F1值和Micro F1值,尤其是AAA加入注意力机制,提取更为重要的特征信息,在3个数据集上表现良好,与Attentive相比,在FIGER数据集上,准确率提高约6%,Macro F1值提高约2%,Micro F1值提高约2%;
在BBN数据集上,准确率能够提升近12%,Macro F1值提高近1%,Micro F1值提高近3%。FGET-RR采用图卷积网络分析上下文信息,并对干净数据和含噪声数据分别设计损失函数,在FIGER、BBN、OntoNotes数据集上的性能能够得到显著的提升。CLSC、AR都是在NFETC的基础上做出相应改进,实验结果表明AR对所有标签通过最小化预测标签与伪真标签之间的KL散度进行概率更新,最终在FIGER数据集上,较NFETC准确率提高约2%,Macro F1值提高约2%,Micro F1值提高约1%;
在BBN数据集上,较NFETC准确率提高约4%,Macro F1值提高约2%,Micro F1值提高约3%。LME从语义角度,主要考虑了语言增强模型,未对预测分类模型做出改进,因此LME在3个数据集上的性能表现不如NFETC。

表2 细粒度实体分类性能比较
因此,由上述分析可以看出,在细粒度实体分类领域中采用BiLSTM处理实体指称上下文,并通过注意力机制提取更为重要的特征,同时利用ELMo、BERT等大规模的预训练模型代替原有的词嵌入,有助于提高分类的准确率。另外,为规避远程监督产生的噪声问题,以无监督的方式,选取伪真标签中最大值的标签,也能显著改善分类效果。
对现有的细粒度实体分类方法以及基于噪声标签处理的方法进行了详细介绍,下面对未来细粒度实体分类的发展趋势和研究热点进行探讨,主要包括以下两个方面。
(1) 目前,基于神经网络的细粒度实体分类大多数都是监督学习,少部分以无监督的方式也取得良好的实验结果。未来以半监督方式,通过训练有标注数据,在验证集上验证无标注数据以获得伪标签数据,将标签数据与伪标签数据结合再次进行训练或以无监督方式,不断优化相似类型标签之间的距离都是可研究的方向。
(2) 对于细粒度实体分类的噪声处理,大多利用远程监督的方法,使得模型关注于实体指称及其上下文,并采用词嵌入、BiLSTM处理指称和上下文向量。LSTM的变体GRU利用更新门和重置门控制输入值、记忆值和输出值,结构较LSTM更为简单,能够简化神经网络,因此利用GRU处理实体指称或上下文的实验有待尝试。另外,利用大规模的预训练模型ELMo、BERT等增强原有处理上下文的BiLSTM方法。现在可挖掘其他大型语料库的信息作为原来只基于实体指称上下文方法的一种补充,提取更优价值的信息,有利于提高实体分类模型的准确率。
本文对细粒度实体分类方法进行了详细叙述,介绍了现有的基于不同神经网络的细粒度实体分类方法以及基于噪声处理的细粒度实体分类方法,并对常用的数据集、评价指标和细粒度实体分类方法的性能表现进行了整理归纳,同时分析了未来发展趋势和研究热点。
猜你喜欢 准确率噪声标签 “白噪声”助眠,是科学还是忽悠?电脑报(2022年24期)2022-07-01乳腺超声检查诊断乳腺肿瘤的特异度及准确率分析健康之家(2021年19期)2021-05-23多层螺旋CT技术诊断急性阑尾炎的效果及准确率分析健康之家(2021年19期)2021-05-23不同序列磁共振成像诊断脊柱损伤的临床准确率比较探讨医学食疗与健康(2021年27期)2021-05-13基于声类比的仿生圆柱壳流噪声特性研究舰船科学技术(2021年12期)2021-03-29颈椎病患者使用X线平片和CT影像诊断的临床准确率比照观察健康体检与管理(2021年10期)2021-01-03不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09要减少暴露在噪声中吗?饮食科学(2016年7期)2016-07-27让衣柜摆脱“杂乱无章”的标签Coco薇(2015年11期)2015-11-09科学家的标签少儿科学周刊·少年版(2015年2期)2015-07-07猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
