首页 > 心得体会 > 学习材料 / 正文
基于PSO-RFR的热连轧轧制力预测模型研究
2023-02-04 11:15:06 ℃苏 楠,任 彦,高晓文,杨 静
(内蒙古科技大学信息工程学院,内蒙古 包头 014010)
热轧板带钢在家用电器、车辆制造、船舶制造等多个行业广泛应用[1],高品质的带钢产品越来越受深加工制造者及制造厂商青睐,但下游生产企业对带钢产品的厚度、宽度、凸度等指标要求越来越高。当前轧机普遍采用了自动板型控制系统[2]来解决板型的控制问题提高了热轧带钢产品产出品质。热连轧生产主要包括粗轧、精轧、层流冷却、卷曲四个部分,其中精轧环节决定了最终带钢板型的好坏。由于热轧环节设备设定变量较多、执行机构数量多且检测环节存在时延,使得板形控制变得更加复杂。板形控制中辊缝与弯辊力直接影响最终产出带钢的板形,而轧制力的设定值影响了辊缝与弯辊力设定值的求解[3]。在轧制过程中,轧制参数相互之间耦合严重,轧制力受来料厚度、变形抗力及板带张力等多种生产过程关键参数的制约。
热轧生产过程存在参数种类多、强耦合、非线性等问题,传统数学机理模型制约了轧制力控制精度的进一步提高。近些年来,大数据技术的蓬勃发展为解决该问题提供了可能,越来越多的学者将人工智能技术应用于热轧控制过程中。马威等采用多层感知器(Multi-Layer Perceptron,MLP)模型对宝钢1880热连轧机组轧制力进行预测[4]。吴倩等采用了GA-BP神经网络与敏感性分析对带钢厚度进行了预测[5]。王春华等使用支持向量回归(Support Vector Regression,SVR)模型对轧制力进行了预测[6]。冀秀梅等使用极限学习机在中厚板轧制中对轧制力进行预测[7]。Parvizi Ali等采用人工神经网络对负荷和转矩进行预测[8]。Jingyi Liu等采用多层极限学习机模型对热连轧轧制力进行预测[9]。
本文以某钢铁企业板材厂热连轧生产过程为对象开展轧制力预测模型的研究,该厂二级控制系统轧制力采用传统轧制力机理模型[10]。该模型满足了当前热轧生产过程的要求,但是受生产过程环境变化、检测干扰等因素的影响,机理模型仍存在预测精度较差、解算耗时、预测结果波动大等缺点。随着生产过程增质增效的提出,轧制力模型预测精度需进一步提升。
考虑热轧生产过程不确定性、模型预测精度、生产实时性等因素,本文采用了随机森林回归(Random Forest Regressor,RFR)算法建立了轧制力预测模型,利用粒子群算法(Particle Swarm Optimization,PSO)优化了RFR模型中的超参数,解决了RFR中超参数设定复杂的问题。实验结果表明,在轧制力预测中RFR模型相较SVR模型和MLP模型预测精度与速度都有所提高。
轧制生产中在采集记录数据时,由于通信系统故障、电磁干扰、数据堵塞等原因会使采集数据中包含少量的异常值。孤立森林算法是由周志华等提出[11],是一种基于集成学习的连续数据无监督异常值检测方法。该算法无需计算距离或密度,具有运算快、抗噪能力强、稳定性好的优点,适用于海量数据的异常值检测。该算法通过检测样本中的孤立点来确定异常值,算法分为训练和检测两个阶段,其具体实现过程如下:
1)训练阶段:使用数据集样本构建孤立树,构建过程具体步骤如下所示:
①从原始数据中随机选取m个样本作为数据集;
②从数据集中随机选取一个特征,在该特征最大值与最小值间随机选取一个切割点p;
③在p点形成一个超平面,将数据集进行二分割,数据集中小于p的数据划分至左侧子节点,大于等于的数据划分至右侧子节点;
④分别在新分割的左右两侧子节点数据重复②③步骤,直至数据不可分或达到最大分割深度;
⑤重复上述过程,构建t棵孤立树。
2)检测阶段:将被测样本x代入孤立树中,并计算由根节点到样本所在节点的路径长度,遍历t棵树得出平均路径长度h(x)。对所有被测样本点的平均路径长度做归一化,得到一个0~1之间的异常分数,越接近1异常的可能性越高。异常值分数计算公式如下所示
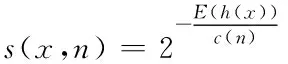
(1)
式中:n表示孤立树分化的节点个数,E(h(x)为样本x的路径长度的期望值,h(x)表示样本x的平均路径长度

(2)
式中:c(n)表示n个样本构建的孤立树的平均路径长度。H(i)=ln(i)+γ,γ是欧拉常数。
在轧制环节中影响轧制力的相关因素较多,主要有轧机的轧制速度、精轧入口厚度、精轧出口厚度,精轧入口宽度、精轧出口宽度、轧辊半径和精轧入口温度等23个主要参数。为了降低模型计算复杂程度及提高预测精度,采用相关系数方法[12]分析影响轧制力的主要参数,选取轧制速度,精轧入口厚度,精轧出口厚度,精轧入口宽度,精轧出口宽度,变形抗力,精轧入口温度,精轧出口温度作为轧制力预测模型的输入。
3.1 轧制力数学机理模型
轧制力数学机理模型公式为

(3)
式(3)中:P为机理模型计算出的轧制力,kN;
km为变形抗力,MPa;
αP,βP为前后张力系数;
tf,tb为前后张力;
Ld为接触弧长度,mm;
BF为精轧目标宽度,mm,QP外摩擦影响系数。
轧辊与钢带的接触弧弧长

(4)
式(4)中:Rd为工作辊变形半径,mm;
H,h为轧机入口和出口厚度,mm。
摩擦系数为

(5)

该机理模型已应用于实际的轧制力计算,然而在推导过程中存在一些假设与简化,因此其预测精度在生产中仍有提升的空间。
3.2 RFR算法
随机森林回归算法是由Leo Breiman提出的一种由多个决策树集成的集成学习算法[13]。RFR算法是使用Bagging方法集成CART回归决策树的强学习算法。RFR使用Bootstrap重抽样从原始训练集中有放回抽取多个子训练集,并使用每个子训练集构建其决策树。RFR算法的预测结果由所有决策树预测结果取平均所得。RFR模型结构如图1所示。
RFR模型的具体实现过程如下:

2)使用CART算法构造q棵决策树(X,Sθ1n),(X,Sθ2n),…,(X,Sθqn)。构建过程不进行剪枝操作使每棵决策树都能在限定范围内最大延伸。单个回归树的预测值1=(X,Sθ1n),2=(X,Sθ2n),…,q=(X,Sθqn)。
3)随机森林回归模型的输出可由构建的q棵决策树预测结果求取平均值得出。如式(6)所示
=1q∑qk=1k=1q∑qk=1(X,Sθkn)
(6)

图1 随机森林回归结构图
3.3 超参数优化
轧制力作为热连轧板型控制的重要指标,其设定值会影响初始辊缝的设定,因此准确预测轧制力对热轧的板型控制至关重要。RFR模型需设定决策树数量和决策树的最大深度,决策树的数量和深度会影响算法的预测速度和拟合能力,因而存在因非最佳参数导致RFR模型预测精度受影响。本文采用PSO算法搜寻最优的决策树棵树q和最大深度n_deep,确保RFR算法具有最优的预测速度和预测结果。
PSO是一种启发式群智算法,是由EBERHART和KENNEDY通过模拟鸟群捕食行为所提出[14]。算法将鸟群简化为一群粒子,每一个粒子都被视为搜索空间中的一个个体,粒子所处位置即对应优化问题的解,粒子在空间中的运动即为搜索最优解的过程。粒子飞行的速度可由个体历史最优位置和种群历史最优位置动态调整,通过不断迭代与更新得到满足条件的最终解。
算法流程如下:
1)设置最大迭代次数m、种群规模n,随机初始化速度和位置,粒子的最大速度和位置为整个搜索空间。
2)定义适应度函数,个体最优解pbesti为每个粒子根据适应度值搜寻到的最优解,从个体最优解中找到当前代数的全局最优解gbesti,与历史数据对比并更新pbesti和gbesti。
3)迭代过程中粒子根据局部最优和全局最优解更新粒子速度与位置,更新公式如下所示

(7)

(8)
4)终止条件:①达到最大迭代次数;
②满足相邻代数之间误差小于定值。
基于PSO-RFR模型的轧制力预测流程如图2所示。
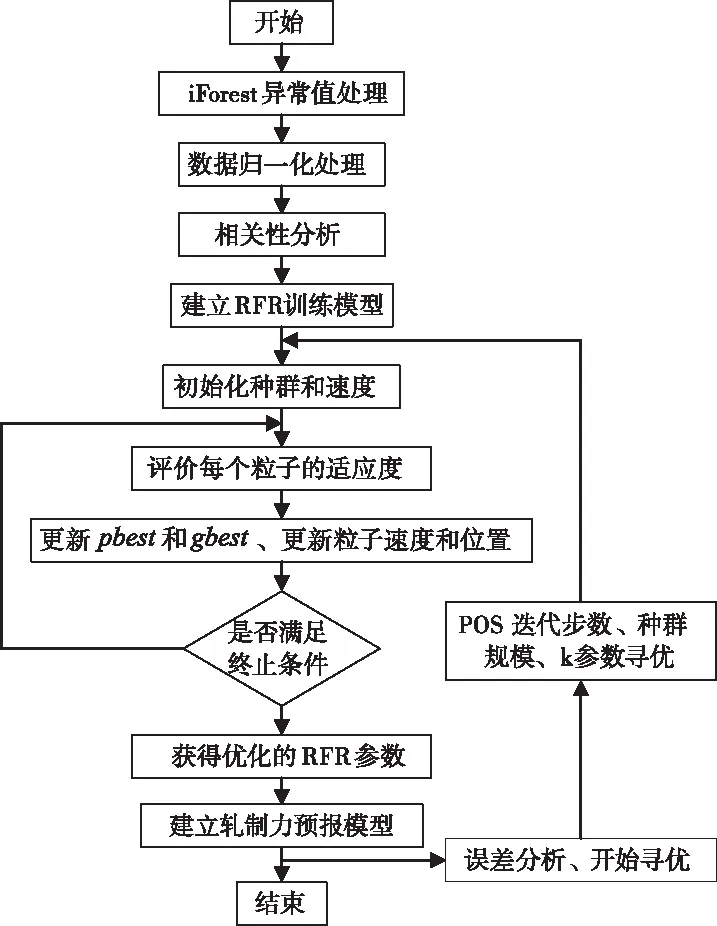
图2 PSO-RFR轧制力预测流程图
本文数据源于某板材厂2250mm热轧产线,选取了2019年3月6日到8月20日的SPCC钢种数据进行分析处理。为验证本文所提方法的合理性及有效性,以2250mm热连轧生产现场采集的2873组SPCC带钢的轧制数据为样本。
经过孤立森林异常值处理后得到2675组轧制数据。由于模型输入参数量纲不一致会影响模型预测性能,因此对模型训练数据进行归一化处理。再使用相关系数法确定RFR模型的输入数据。热连轧生产中采集部分相关数据见表1。

表1 轧机部分主要参数
将预处理后的数据分为两部分,将70%的样本数据作为训练集,将30%的样本数据作为测试集。训练集用于构建预测模型,测试集用于测试构建的预测模型的预测能力。
本文采用Python语言,构建了基于PSO-RFR的轧制力预测模型。粒子群算法中粒子个数n=20,粒子代数m=50,适应度函数为均方误差函数。经过粒子群优化后得到RFR模型的最佳棵数q=91与最佳深度n_deep=252,使用该参数构建RFR模型并对轧制力进行预测。
图3为PSO-RFR轧制力预测值、实测值与机理模型计算值对比图,为了便于观察,选取了前50组数据进行绘制。由图中可知,本文提出的PSO-RFR模型相比基于数学机理模型,本文提出的PSO-RFR模型在轧制力预测中预测精度更优。对测试集中802块样本数据的预测结果进行分析,发现预测误差在±5%内的命中率为97.7%。PSO-RFR的预测曲线与实测曲线基本吻合,能够满足生产中对轧制力预测的需求。一般而言,测试集在模型构建中并没有参与参数寻优,所以测试集的预测结果更能反映预测模型的预测性能。

图3 PSO-RFR轧制力预测值、实测值与机理模型计算值对比图
为了验证本文所提方法的有效性,将PSO-RFR模型与支持向量回归(SVR)模型和多层感知器(MLP)模型进行了对比。
SVR轧制力模型惩罚值设为39.23、松弛因子设为1.83、使用多项式核函数。由图4可知,黑色虚线所夹区域中数据的误差范围在±5%以内,本文所构建PSO-RFR预测模型预测结果中97.7%落在±5%内,SVR预测模型的误差89.8%落在该范围内。通过散点图与误差统计体现了PSO-RFR模型在热连轧轧制力预测中的优势。

图4 PSO-RFR与SVR轧制力预测对比图
MLP轧制力模型有2层隐层,激活函数使用ReLU函数。由图5可知,MLP模型的预测效果弱于PSO-RFR模型预测效果。经统计MLP模型误差90.9%落在±5%范围中,更进一步体现了PSO-RFR模型在轧制力预测中的优势。

图5 PSO-RFR与MLP轧制力预测对比图
为评估预测模型的预测性能,选用平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2)三项性能指标对所建立的PSO-RFR、MLP、SVR预测模型进行评价,评价结果如表2所示。R2表明了模型的拟合能力,越接近1表明模型拟合程度越高。PSO-RFR模型的R2指标均优于其它两种预测方法,表明该方法具有较好的拟合能力。MAE与RMSE都小于其它预测方法,表明了PSO-RFR模型改善了小样本数据在轧制力预测中存在的不足,即小样本数据中样本数据分布不均衡导致训练模型在新数据预测时性能变差的问题。PSO-RFR相较于其它两种方法预测时间最短,相较其它方法适用于高速的连轧生产。本文构建的RFR预测模型提高了预报模型的准确率,为热轧操作者生产控制提供了参考依据。

表2 三种建模方法的预测结果对比
轧制力是热轧环节中的重要参数,对最终板形有很大的影响。本文采用孤立森林算法对现场生产数进行预处理,提出了RFR轧制力预测模型,并采用了PSO算法对RFR模型中超参数进行优化。结果表明,本文所提模型预测误差在±5%内的命中率为97.7%,单次预测耗时1ms,相较于SVR,MLP模型具有预测精度高、预测时间短的优点。该模型能很好地预测轧制力的变化规律,并满足生产过程在线预测轧制力的要求。本文的研究对传统机理模型不能处理非线性、多变量轧制力预测问题提供了新的研究方法。
猜你喜欢 决策树机理粒子 碘-125粒子调控微小RNA-193b-5p抑制胃癌的增殖和侵袭昆明医科大学学报(2022年1期)2022-02-28隔热纤维材料的隔热机理及其应用建材发展导向(2021年14期)2021-08-23周礼与儒学的机理当代陕西(2020年23期)2021-01-07基于膜计算粒子群优化的FastSLAM算法改进新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25Conduit necrosis following esophagectomy:An up-to-date literature reviewWorld Journal of Gastrointestinal Surgery(2019年3期)2019-04-24金属切削中切屑的形成机理智富时代(2018年8期)2018-09-28金属切削中切屑的形成机理智富时代(2018年8期)2018-09-28决策树和随机森林方法在管理决策中的应用电子制作(2018年16期)2018-09-26决策树学习的剪枝方法科学与财富(2016年32期)2017-03-04决策树多元分类模型预测森林植被覆盖电子制作(2017年24期)2017-02-02- 上一篇:智慧物流越库最佳调度方案仿真
- 下一篇:基于随机L-BFGS的二阶非凸稀疏优化算法
猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
