首页 > 心得体会 > 学习材料 / 正文
基于数据挖掘的思政教师教学能力评估模型设计
2023-03-04 19:40:13 ℃陈晨
(陕西工业职业技术学院, 马克思主义学院, 陕西, 咸阳 712000)
学校思政课的核心是帮助学生坚定理想信念,树立正确人生观和价值观,在学生成长过程中发挥重要指导作用[1]。为获得有效的评估结果,需要建立思政教师教学能力评估模型。国外学者大多从教师人格因素和有效教学2个方面进行研究,而四五千年前的学者则主要从教师的声音、外表、热情、信任等方面进行研究。文献[2]制定出教师教学能力评价的因素集,分解后得到能力层次结构图,通过各要素的隶属关系最终确定8个核心要素,以此作为教学评价指标。文献[3]利用灰色关联分析法构建绩效评价模型,经过指标权重优化后,评价结果更加客观准确。此外,评估方法也含有定量分析的内容,但只是指标因素与教师教学能力之间简单的线性统计关系,缺少高精度评价结果。数据挖掘技术是从数据库中提取潜在信息,在没有先验规则的前提下,深入挖掘数据价值[4]。目前,数据挖掘应用范围非常广泛,在多个领域都做出巨大贡献[5]。因此,本文基于数据挖掘,设计思政教师教学能力评估模型,在大数据支持下提高思政教师教学能力定量评估的可靠性和有效性。
1.1 划分思政教师教学能力聚类
本次构建的思政教师教学能力模型指标,主要从课前、课中和课后3个方面进行选取[6-7]。根据属性距离计算聚类相似性,按照相似性将剩余数据样本归类到初始中心,进而得到具有相似性的聚簇。重复上述聚类过程,直至标准函数收敛,计算式为
(1)
式中,B表示标准函数,ai表示数据样本,ck表示聚类初始中心,k表示聚类中心个数。对于聚类算法而言,选择合适的聚类数是算法的中心环节,只有选择最佳聚类数,才能最大程度实现聚类结果的相似度,以此为基础开展分析研究[8]。本次模型设计利用轮廓系数,选择最佳聚类数。轮廓系数的计算式为
(2)
式中,λi表示轮廓系数,d1表示凝聚度,为同一聚簇样本到其他样本的平均距离,d2表示分离度,为不同聚簇样本到所有样本的平均距离。d1越小,则样本聚簇性越好;
d2越小,则样本聚簇性越差。根据式(2)计算得到所有λi,再对λi取平均值,得到平均轮廓系数,
(3)
式中,λk表示平均轮廓系数,s表示样本数量。理论上,λi取值范围为(1,-1),λk越接近1,则样本的聚类分簇越合理;
反之,λk越接近-1,则说明分簇越不合理;
若λk接近于0,则认为当前样本位于2个聚簇的边界。通过上述判断方式,可以得到最大λk时的k值为最佳聚类数。在确定最佳聚类数的基础上,进一步得到最大迭代次数,其过程可表示为
|Bn-Bn-1|<ε
(4)
式中,Bn和Bn-1分别表示最大迭代次数n与前一次n-1的标准函数,ε表示极小数。当迭代次数满足上述条件时,则说明迭代达到最大值,此时输出结果为最佳聚类数k的迭代终止结果[9]。利用迭代终止时输出的结果,完成对思政教师教学能力聚类的划分,以此为分析数据挖掘关联的能力评估指标。
1.2 基于数据挖掘关联能力评估指标
根据思政教师教学能力评估指标的特点,本次模型设计利用数据挖掘技术的关联规则算法,建立各评估指标与思政教师教学能力的关系规则[10-11],比较最小支持度阈值并进行项集连接,记录所有候选项集的支持度,支持度的计算公式为
(5)
式中,SUP(H→G)表示数据H、G关联性的支持度,P(H∪G)表示H、G同时发生的概率,n表示总事务数量。根据候选项集支持度,逐层搜索并依次进行迭代,遍历所有项集,直至不在产生更大的频繁项集[12]。在数据集中找出频繁项集后,直接根据最小置信度阈值制定关联规则,置信度的计算公式为
(6)
式中,CON(H→G)表示数据H、G关联性的置信度,P(H∪G)含义与式(5)相同,P(H)表示H发生的概率。利用能力评估指标属性及其变化范围,确定数据挖掘关联规则,从中选取置信度高的关联规则结果,以此确定各评估模型对教学能力的影响程度。
1.3 构建教学能力评估模型
为更好地确定各基础因素的权重关系,利用一致矩阵两两比较相同层次的因素,减少因性质不同而带来的比较性差异[14]。假设因素x比因素y更为重要,则比较结果表示为βxy;
反之,因素y比因素x更为重要,则比较结果表示为βyx,则有:
(7)
式中,βyx表示最小特征值,各因素两两比较结果构成判断矩阵,经一致性检验后才可进行权重计算[15]。首先实施层次单排序,计算每一层次因素相对于前一层的权重向量,记为ω。将ω带入判断矩阵α,得到最大特征根,计算公式为
(8)
式中,γmax表示最大特征根,m表示判断矩阵阶数,(α)i表示判断层次数,(ω)i表示聚类指数。利用γmax计算一致性指标与比例,公式为
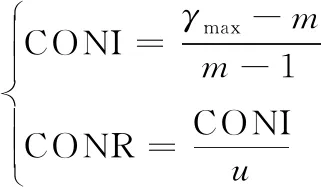
(9)
式中,CONI表示一致性指标,CONR表示一致性比例,u表示平均随机一致性,取值与阶数m有关。经过一致性检验后,对所有因素实施层次总排序,得到整个评估模型的权重。综合上述过程,完成对思政教师教学能力评估模型的设计。
为了分析基于数据挖掘的思政教师教学能力评估模型的有效性,与现有模型进行对比,测试模型应用效果。
2.1 实验准备
首先搭建实验分析平台,具体参数和配置如表1所示。

表1 思政教师教学能力评估的实验分析平台
本次实验中聚类数k与λk表示平均轮廓系数的关系。确定各聚类的教学能力值,如图1所示。
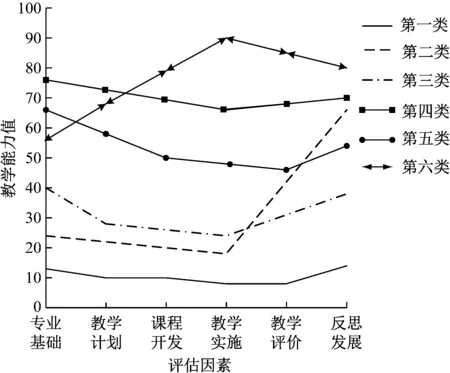
图1 不同聚类教学能力比较
根据不同聚类的教学能力,进一步分析能力指标的影响强度,确定各评估指标的权重。
2.2 思政教师教学能力评估效果测试
为了分析基于数据挖掘的思政教师教学能力评估模型的优势,与现有评估模型进行对比,计算每所学校思政教师教学能力的评估精度。通常情况下α取值为1,此时对精确率和召回率的重视程度相同,即F1值越大,模型越有效。不同模型的测试结果见表2。
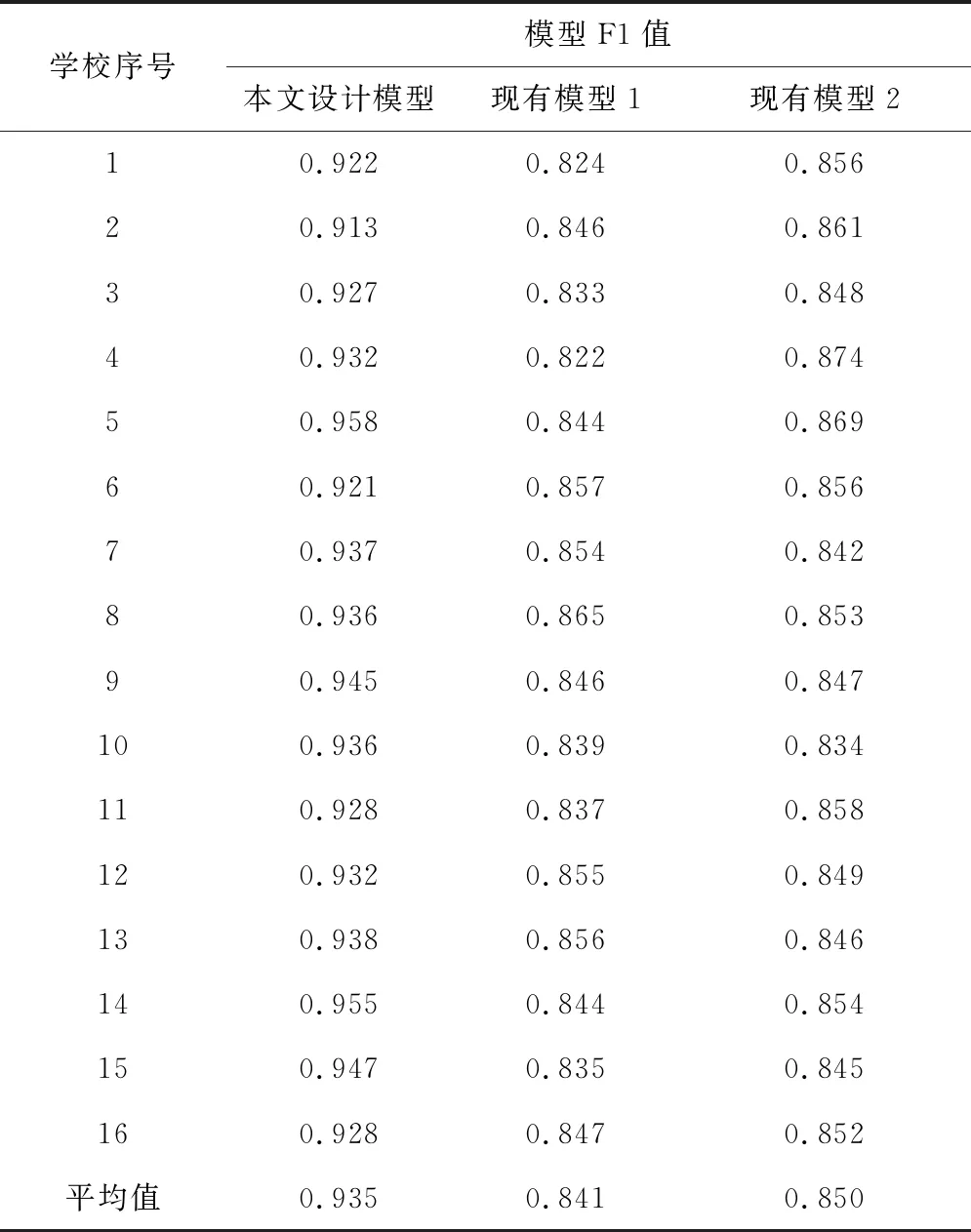
表2 模型F1值对比结果
根据表2的模型对比结果,此次设计模型在精确率和召回率上均具有一定优势。进一步比较F1值,基于数据挖掘构建的模型的F1值为0.935,比现有模型高出0.094和0.085,证明模型输出结果的精度较高,具有较好的质量,评估效果得到改善。
本次研究基于数据挖掘设计思政教师教学能力评估模型,实验结果表明提高了模型精度,获得更好的评估结果。本研究的创新之处在于主要从思政教师自身能力的角度对模型进行设计,还存在进一步发展空间,未来研究可扩大指标选取范围,例如从学生评价等方面完善评估指标,提高模型评价质量。
猜你喜欢 数据挖掘聚类样本 用样本估计总体复习点拨中学生数理化·高一版(2021年2期)2021-03-19探讨人工智能与数据挖掘发展趋势大众投资指南(2021年35期)2021-02-16数据挖掘技术在打击倒卖OBU逃费中的应用浅析中国交通信息化(2020年1期)2020-07-27基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-08基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26随机微分方程的样本Lyapunov二次型估计数学学习与研究(2017年3期)2017-03-09基于Spark平台的K-means聚类算法改进及并行化实现互联网天地(2016年1期)2016-05-04村企共赢的样本中国老区建设(2016年1期)2016-02-28基于改进的遗传算法的模糊聚类算法智能系统学报(2015年4期)2015-12-27高级数据挖掘与应用国际学术会议智能系统学报(2013年1期)2013-01-28猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
