首页 > 心得体会 > 学习材料 / 正文
一种基于WaveNet的藏语语音合成方法
2023-05-05 20:50:04 ℃丁云涛,才让卓玛,贡保加,才智杰
(1. 青海师范大学计算机学院,青海 西宁 810016;
2. 西南民族大学计算机科学与工程学院,四川 成都 610041;
3. 藏语智能信息处理及应用国家重点实验室,青海 西宁 810008)
语音合成是智能人机语音交互的核心技术,它的研究对智能机器人、人机语音通讯系统及自动控制等的研制具有重要的理论意义和实用价值。国内外对语音合成的研究可追溯到18世纪,其发展历程主要经过机械装置语音合成、电子器件语音合成、基于计算机技术的语音合成等三个阶段[1]。随着计算机硬件和技术的发展,基于计算机技术的语音合成从合成技术角度通常将语音合成分为波形合成法[2]、参数合成法[3]、规则合成法[4]和基于神经网络的语音合成法[5]。其中,基于神经网络的语音合成方法由于自主学习和反向传播的能力[6],大大减少了语音合成的错误率,更贴近于人声。因此,基于神经网络的语音合成方法已经成为当前语音合成的主流方法[7-10]。
藏语语音合成作为中文信息处理的重要组成部分,同时也是藏语智能人机语音交互的重点和难点。现如今,神经网络技术的发展不仅降低了藏语语音合成的门槛,同时提高了语音合成的质量。2019年文献[11]融合seq2seq模型和注意力机制,提出了基于griffin-lim[12]声码器藏语语音合成方法,使得藏语语音合成进入了新时代。
griffin-lim声码器高效、算法简单,但却存在语音保真度低、人工合成痕迹明显的问题。2017年DeepMind提出的WaveNet[13]能够通过直接学习到采样值序列的映射,合成接近原始音频效果的语音。鉴于此,该文提出了基于WaveNet的藏语语音合成方法。
藏语语音合成技术作为中文信息处理的重要分支,尽管起步较晚,但也逐步从基于波形拼接的藏语语音合成[2]和基于统计参数的藏语语音合成[14]进入到基于神经网络的藏语语音合成[11,15]时代。
目前,基于神经网络的藏语语音合成主要采用griffin-lim声码器[16,17],通过注意力机制使用编码器-解码器结构提取藏文文本特征来预测mel频谱,最后使用griffin-lim声码器实现藏语语音的合成。

图1 基于WaveNet的藏语语音合成模型
griffin-lim声码器是一种已知幅度谱,通过迭代生成相位谱,并用已知的幅度谱和计算得出的相位谱,重建语音波形的方法。这种声码器不需要训练,不需要预知相位谱,而是通过帧与帧之间的关系估计相位信息。
WaveNet作为一种可训练的基于深度神经网络的声码器,可以用于语音生成建模,它是一个完全的概率自回归模型,即可基于之前已经生成的所有样本,预测当前音频样本的概率分布。在语音合成的声学模型建模中,WaveNet利用因果卷积、带洞因果卷积与相应激活函数的结合,可以更好的学习语音中的相位、振幅等特征信息,具有很好的合成效果。从语音合成质量来说,WaveNet声码器的自回归特性及其在时域上更强的感知能力和感知范围[18,19],使得合成出的语音更能贴近人声,弥补了griffin-lim保真度较低且有着较为明显的人工合成痕迹问题[18]。
藏语作为我国广大藏区藏族使用的语言,其语音不仅具有鲜明的地域性,而且语法丰富多样。例如,分布在中国西藏自治区和青海、四川、甘肃等地的藏族使用着不同的方言(卫藏方言或康巴方言或安多方言),且有些方言同汉语普通话一样有声调,但有些藏语方言没有声调。藏文字以字根(或称基字)为中心由辅音字母和4个元音组成,呈二维结构,其既不同于汉字或拼音,也不同于一维结构的英文。因而合成藏语语音,需要更多地考虑藏语言文字本身的声韵特征信息。鉴于此,该文用带有注意力机制(attention mechanic)[20]的特征提取结构来提取藏文特征和频谱特征,根据频谱特征使用WaveNet声码器合成藏语语音波形。实验数据证明,在相同语料下该文方法能获得更好的合成语音。
3.1 文本特征提取
文本特征在语音合成过程中不可或缺,因此该文首先对文本进行预处理后,之后使用卷积运算提取文本特征,并通过注意力机制给文本特征赋予相应权重完成文本特征提取,具体过程简述如下:
首先,将文本数据经字符编码转换为相应的词向量,以此作为后续的输入。


表1 one-hot编码

表2 线性变换
其次,利用三个1维卷积层对词向量提取文本特征。具体参数设置如图2所示。
考虑到一维滤波器可以更好的检测文本特征相关度的高低,因而在每一层卷积层中使用了512个一维滤波器提取文本特征(512与之前的词向量特征深度对应),每一层卷积层都通过relu激活函数来实现非线性激活。

图2 卷积层
最后,使用注意力机制给文本特征赋予相应的权重,使得文本特征经训练后更符合人耳特性,其原理如图3所示。
图3中h1,h2,…,ht为文本特征向量(即经过BiLSTM编码之后的输入),a1,a2,…,at为权重向量(即注意力权重)。该过程是将句子中每一个文本特征向量的序列与权重向量进行乘积,得到文本特征权重向量ct,进而将ct合并为一个c矩阵作为LSTM(decoder)的输入。训练时BiLSTM将文本特征序列编码为隐藏的特征,LSTM将赋予注意力权重的文本特征序列解码为相应频谱特征,权重向量大小随着BiLSTM和LSTM的训练得到更新。
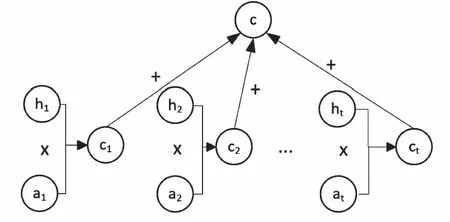
图3 注意力权重赋值
3.2 频谱预测
考虑到mel频谱更符合人类的听觉系统[18],该文选择mel频谱作为频谱特征进行频谱预测。通过建立一个自回归的神经网络实现频谱的多帧预测,其主要步骤如下:
1)将解码后的频谱特征矩阵通过线性投影的方式预测一帧mel频谱向量。该过程中,线性投影的内部结构是一个带有1024个隐藏单元的隐藏层,考虑到全连接可以减少特征位置带来的影响,使得预测的mel频谱更贴近实际的mel频谱,从而在发音上更接近原始音频。因此,该文用全连接映射实现线性投影预测得到一帧mel频谱。
2)将获得的该帧mel频谱向量通过后处理层(post-net)的残差卷积运算使该帧mel频谱向量更加精确。其中,post-net的内部结构由5个1维卷积层组成,为了避免由于卷积层数过深导致神经网络的梯度传播会出现梯度爆炸等问题,该文利用残差网络(residual network)[21],通过跳层连接形式,使得深层网络卷积的训练效果更好[22]。
3)预处理层(pre-net)将该帧的mel频谱实现非线性变换转换频谱矩阵维度。该过程中,pre-net内部结构由2层带有256个隐藏单元的relu全连接层组成,第一层与第二层之间使用0.5的衰减率(即第一层与第二层之间的连接个数随机减半)来减少过拟合,提高泛化能力,从而实现非线性变换。
4)将频谱矩阵与新解码的频谱特征矩阵进行拼接,获得下一帧的频谱特征矩阵。例如新解码的频谱矩阵其维度为1024*1,原频谱矩阵的维度为512*1,通过拼接作为下一帧的频谱矩阵,其维度为1536*1的矩阵。
完成步骤4)后返回步骤1),重复此步骤,直到mel频谱预测完全。

图4 原声

图5 带post-net

图6 不带post-net
3.3 波形合成
WaveNet作为神经网络声码器,其内部结构由因果卷积、带洞因果卷积层的一维卷积层以及门控激活函数(tanh,sigmoid)构成。其中,因果卷积保证了频谱信息的时序性,带洞因果卷积扩大了频谱卷积的感受野,而门控激活函数tanh和sigmoid分别学习音频特征中的相位、频率信息和振幅信息。
在藏语语音波形合成中,WaveNet将预测的Mel频谱矩阵通过因果卷积生成新的频谱矩阵,对频谱矩阵通过带洞因果卷积和一系列的门控激活函数进行粗粒度卷积。通过自回归特性恢复丢失相位信息后用softmax函数输出采样点的后验概率[23]。其中,自回归特性是通过前t-1个波形采样点来预测第t个采样点,其概率式(1)如下所示:
(1)
该文实验结果采用了客观分析和主观评价两种方式,其中客观分析首先分析了训练步数/百分比损失图得出该模型训练的有效性,接着对比分析频谱图的共振峰清晰度与幅度进而得出客观结果,主观分析通过MOS(Mean Opinion Score)值分析对比语音的自然度、清晰度。
实验语料采用青海师范大学藏文信息处理重点实验室的语料,包含2400句专业藏族播音女声,采样率为16000Hz,采样精度为16bits。考虑到语音信号的非平稳特性,在预处理中使用汉明窗,帧长50ms,帧移12.5ms。训练步数设置为100000步。
4.1 客观分析
训练步数/百分比损失图可以清晰地看出模型的拟合程度,如图7(训练步数为100000步)所示:随着训练步数的增加,百分比误差也不断地降低,在60000步后趋于平缓,达到0.7%的损失,得到了较好的训练效果。

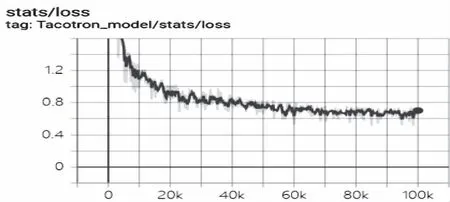
图7 训练步数/百分比损失图

图8 基线模型

图9 该文模型
清楚的看出该文模型在共振峰的清晰度上相比较基线模型更加清晰,在高频区有更多的细节描绘,更加贴近原声。反观基线模型,可以看出在一些共振峰上相比较原声模型并不连续,且在高频区缺乏细节描绘。因而该文的模型相较于基线模型的藏语语音合成有着更好的表现。
图10 原声
4.2 主观分析
从语料库随机抽取出5句安多藏语作为测试数据,并将文献[11]作为该文基线模型与该文模型进行了对比分析。对比依据来自10位不同的专业、不同层次懂藏语的测试员对测试数据从自然度、清晰度进行MOS打分,具体结果如表3和图4所示。
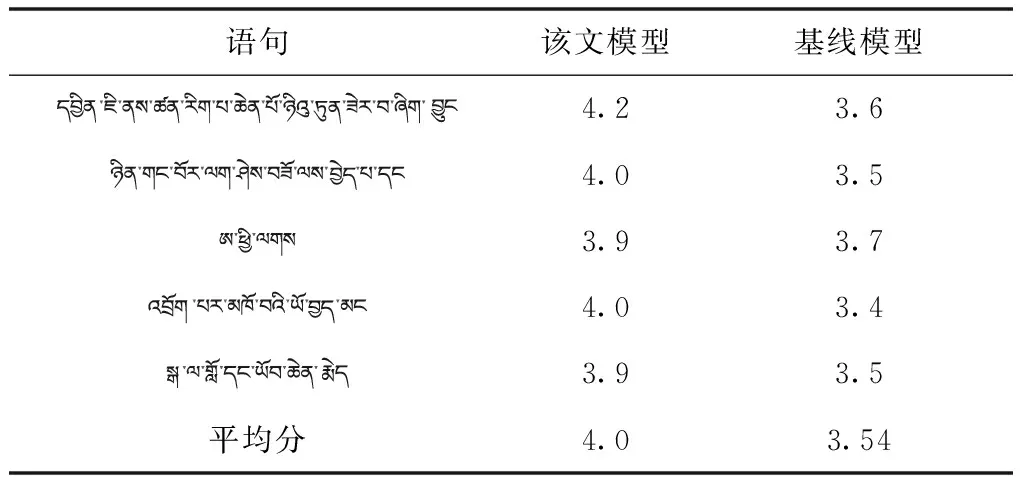
表3 MOS值
由上表3可见,测试员普遍认为该文模型相较于基线模型在自然度与清晰度上有着更好的MOS值。
该文在文献[11]的基础上,使用一维卷积层提取文本特征,添加了post-net对mel频谱进行进一步处理使其预测结果更贴切实际,最后使用WaveNet代替了griffin-lim算法合成藏语语音。从主观、客观实验证明,该文的模型效果更佳,合成的语音效果在自然度、清晰度上更佳贴近原声。
相较于汉语、英语的语料,藏语的语料非常的稀缺和现有声码器存在的问题,后续研究中还需地不断地扩大藏语语料库规模和改进WaveNet声码器的合成速率。
猜你喜欢码器藏语频谱浅谈藏语中的礼仪语客联(2022年2期)2022-04-29一种用于深空探测的Chirp变换频谱分析仪设计与实现空间科学学报(2021年6期)2021-03-09DataMan 370系列固定式读码器传感器世界(2019年5期)2019-08-07一种基于稀疏度估计的自适应压缩频谱感知算法测控技术(2018年7期)2018-12-09藏语拉达克话的几个语音特征西藏研究(2017年3期)2017-09-05藏语地理分布格局的形成原因西藏研究(2016年5期)2016-06-15一种快速准确适用性广的伪随机扰码识别方法电子科技大学学报(2015年4期)2015-10-09康耐视 DataMan®8050系列手持式读码器自动化博览(2014年4期)2014-02-28一种基于功率限制下的认知无线电的频谱感知模型电子设计工程(2014年19期)2014-02-27基于Labview的虚拟频谱分析仪的设计电子设计工程(2014年18期)2014-02-27猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
