首页 > 心得体会 > 学习材料 / 正文
融合CNN-SAM与GAT的多标签文本分类模型
2023-05-07 14:00:17 ℃杨春霞,马文文,陈启岗,桂 强
1.南京信息工程大学 自动化学院,南京 210044
2.江苏省大数据分析技术重点实验室,南京 210044
3.江苏省大气环境与装备技术协同创新中心,南京 210044
多标签文本分类(multi-label text classification,MLTC)作为自然语言处理(natural language processing,NLP)文本分类的核心任务之一,旨在从文本内容中快速、准确地挖掘出更为详细的标签信息,其在情感分析、新闻分类、问答任务等应用场景均有广泛应用。伴随着移动社交平台与互联网的飞速发展,网络文本的数量爆发式增长,大量未经规范化的文本数据与用户交互数据无疑增加了分类研究的难度。因此,为了更高效地分析处理文本数据,满足用户需求,需要进一步完善和提高分类技术的研究。
相比于单标签文本分类任务而言,MLTC任务就是根据文本数据信息,为其自动分配出与之相关联的多个标签,如一篇体育新闻可能同时属于“篮球”“足球”和“乒乓球”等多个主题,准确分类的关键在于是否能从上下文语义信息中准确挖掘出与主题相关的关键特征。目前针对文本主要特征的提取常使用卷积神经网络(convolutional neural network,CNN)[1-2]或注意力机制[3-4]模型,并且均取得不错的分类效果。然而CNN在利用卷积层提取信息时,只考虑其局部邻近词汇的语义信息,忽略了文本单词之间长距离信息依赖关系。相反,注意力机制可以很好捕捉全局词与词之间的依赖关系,为文本中每个词赋予相应的权重,突出文本中关键词信息的表示,但缺乏局部上下文语义信息之间的联系,这表明单一地从局部或者全局捕获文本信息并不是最优的。
除了对文本信息的提取,最近,肖琳等人[5]将特定文本标注的标签信息融入文本信息中,并取得不错的效果,这初步表明基于语义联系的标签信息的融入对提高多标签分类效果有一定帮助,从而也进一步验证了Zhang等人[6]所提出不同标签之间的关联性可以有效提升模型的分类性能的结论。但是仅仅局限于特定文本标签之间的语义联系,一方面部分标签之间存在的紧密连接关系可能会丢失,另一方面也不能体现出不同标签之间的关联程度。因此,如何挖掘全局标签之间的依赖关系是目前需要尽快解决的一个问题。
针对以上两个问题,本文提出融合CNN-自注意力机制(self attention mechanism,SAM)与图注意力网络(graph attention network,GAT)的多标签文本分类模型(CS-GAT),主要贡献如下:
(1)本文利用多层CNN与SAM分别提取文本的局部与全局特征信息并进行融合,获取更为全面的特征向量表示。
(2)本文将不同文本标签之间的关联性转变为具有全局信息的边加权图,然后利用多层GAT充分挖掘全局标签之间的关联程度。
(3)模型在三个公开英文数据集上进行实验,并与相关的五个主流基线模型作对比,实验结果表明,本文提出的CS-GAT模型的分类效果明显优于基线模型。
由于早期机器学习方法效率不高,近年来MLTC任务的研究更青睐于深度学习中神经网络的研究方法。
文本的类别特征通常由上下文中某几个短语或词语来确定,CNN通过对文本连续词序列信息进行卷积、池化操作来获取文本局部主要特征信息,如Kim[7]首次利用CNN的卷积、池化层对文本特征进行最大化提取,提高了文本在多个领域的分类效果。Liu等人[8]在考虑样本标签数量大、数据稀疏等问题后利用CNN解决MLTC问题,将动态池化层从不同角度提取文本主要特征,使得提取效果有了显著提升。虽然CNN在以上分类任务的研究中均取得不错的效果,但缺乏对文本全局信息的考量,如“大量温室气体的排放导致全球气候变暖,随着美国退出了《巴黎协定》,这可能会进一步加剧这个问题”,CNN可以将其捕获为“气候变暖”“美国退出《巴黎协定》”等局部信息。但从全局来看,如“大量”“退出”“可能”和“加剧”等词语既可以更加突出文本的主要特征信息,又能在一定程度上削弱无关信息所带来的影响,而CNN却无法将这些全局权重信息分配给对应的特征。
对于全局信息的捕获,在早期的机器翻译模型中,Attention机制通过重点关注与当前翻译词相关的词汇信息来提高当前词翻译的准确度,从而提高模型的性能。基于此原理,You等人[9]使用SAM提取文本特征,Yang等人[10]利用SAM作为编码器提取文本全局交互信息,均验证了SAM可以有效捕获文本内容贡献的差异性。然而SAM只考虑全局词之间的依赖关系,却忽略了局部邻近词汇之间的语义联系。于此,本文同时利用多层CNN与SAM对文本信息进行提取、融合,充分获取具有文本局部与全局特征的向量表示。
在考虑文本内容信息的同时,Xiao等人[11]将文本标注的标签信息融入文本信息中,虽然取得不错的效果,却忽略了全局标签之间的依赖关系。在此基础上,You等人[12]提出AttentionXML,通过构建浅而宽的概率标签树来捕获与每个标签最相关的文本部分。Huang等人[13]提出随机游走模型,采用广度优先游走和深度优先游走对标签节点进行采样。Xiao等人[14]提出头-尾网络,将文本中出现频率高的标签信息转移到出现频率低的标签信息,提高了尾部分类器的泛化能力。以上方法虽然考虑了全局标签之间的相关性,但主要有效解决了尾部标签所产生的影响,而对于不同标签之间的关联程度仍没有得到很好的处理。在单标签文本分类任务中,Yao等人[15]依据文档-词、词-词之间的联系构建一个异构图,然后利用图卷积神经网络很好地捕获了全局词共现关系。受此启发,本文将不同文本标签-标签之间的关联性转变为具有全局信息的边加权图,然后利用GAT的注意力机制代替图卷积神经网络的静态归一化卷积运算来挖掘全局标签之间的相关联程度。
本文提出的CS-GAT模型分别由文本与标签词嵌入层、BiLSTM层、融合局部与全局的文本特征提取层、标签图注意力层、标签文本交互层,自适应融合层、模型训练组成,其总体框架如图1所示。

图1 模型框架Fig.1 Framework of model
2.1 任务定义
给定训练集{(C1,y1),(C2,y2),…,(Cm,ym)},其中Cm表示第m个文本,每个文本由一系列词向量{w1,w2,…,wn}所表示,ym为第m个文本对应的标签类别,ym∈{0,1}k,其中k表示所有文本包含的标签种类总数。本文的MLTC任务是通过训练集对CS-GAT模型的训练,能够将新的未标记的样本分类到k个语义标签中。
2.2 文本与标签词嵌入层
本文采用Glove[16]预训练词向量对文本与标签中的词进行初始化向量表示,对于文本Cm,N∈Rn×d即将文本信息经过词嵌入层后被映射为一个低维稠密向量矩阵,矩阵的大小为n×d,其中n表示文本中词的数量,d表示每个词向量的维度。同理,标签也由词嵌入向量矩阵l∈Rk×d表示。根据Glove模型的共现特性,文本与标签初始化后词向量之间仍具备一定的语义联系。
2.3 BiLSTM层
双向长短期记忆网络(bi-directional long shortterm memory,BiLSTM)可以捕捉文本上下文双向语义依赖关系。当t时刻输入的文本词向量为wt,则单向LSTM序列中t时刻的隐层状态ht计算过程如下:
式中,ft、it、ct、ct、ot分别为t时刻遗忘门、输入门、临时细胞状态、细胞状态与输出门值,W与b分别为对应的权重矩阵与偏差项,σ为sigmoid激活函数,tanh为双曲正切激活函数。
刻词向量正反向信息表示与进行拼接,得到BiLSTM的输出表示H,使每个单词获取具有上下文语义信息的表示,计算式为:
2.4 融合局部与全局的文本特征提取层
为了更全面地提取文本特征信息,本文集成了多层CNN与SAM各自的优势,分别从局部与全局两个角度对文本信息进行建模。
2.4.1 局部信息提取层
CNN凭借其适应性强[17]、结构简单、计算复杂度低等优势广泛应用于NLP各个领域中,本文也将利用其提取文本局部主要特征信息,模型结构如图2所示。

图2 CNN模型Fig.2 CNN model
本文选用3个不同长度,宽度均与词向量长度相同的卷积核通过滑动窗口的移动对BiLSTM的输出H进行局部特征提取,特征图表示为:
式中,wc为权重矩阵,m为卷积核的滑动步长,表示从词向量矩阵第i个位置开始移动m个词向量所组成的矩阵表示,b为偏差项,f为sigmoid激活函数,vi表示第i个位置的卷积特征值。
为提取文本中的N-gram主要特征,将利用最大池化层对特征图压缩并提取其主要特征信息,然后将不同卷积核提取到的特征向量进行拼接,形成特征序列ec。
由于考虑最终的输出与SAM输出进行融合,因此将拼接后的向量ec经过全连接层改变其维度,获取文本最终局部特征表示ec=linear(ec)∈Rn′×2dh。
2.4.2 全局信息提取层
在MLTC任务中,SAM实质是在权衡上下文全局信息后为文本中每个词赋予相应的权重,权重值越大的词在分类任务中发挥的作用就越大,分类效果也就越好。
本文将BiLSTM的输出H作为SAM的输入,然后将其分别与三个待训练的参数矩阵WQ、WK、WV相乘得到查询矩阵Query、被查询矩阵Key以及实际特征信息矩阵Value:
然后将Query与Key矩阵做内积运算并进行归一化处理,得到每个词向量对应的得分。接着使softmax激活函数处理得到的每个词的权重比例与实际特征信息Value矩阵相乘,获取具有全局信息的词向量表示ea。
式中,dk为向量的维度,主要为了防止内积值随着向量的维度增大而增加,进而使梯度趋于稳定。
2.4.3 特征融合
在获取文本局部、全局特征表示后,本文将两者进行融合,得到包含局部和全局的语义特征向量X:
将局部与全局特征点组合成特征向量X∈Rn′×2dh作为多标签文本分类实例特征表示,既可以从融合的特征向量中获得最具差异性的信息表示,又可以增强模型的特征表达能力。
2.5 标签图注意力层
由于每个文本均包含两个及以上的标签,不同文本的标签之间可能存在依赖关系或相关性。基于此,根据共现原理,本文由图G=(V,E)来挖掘标签-标签之间存在的关联性。其中V为标签的节点表示,E表示标签-标签之间的关联程度。因此,由图G的拓扑结构所构成的邻接矩阵表示为:
式中,nij为两个标签节点i、j在所有文档中共同出现的次数,Cm表示第m个文本。Aij表示将矩阵Xij的对角线元素全部设置为1,即每个标签节点的自循环操作。D为矩阵Aij的度矩阵,即将矩阵Aij进行归一化处理。

图3 GAT模型Fig.3 GAT model
式中,α为注意力机制,即标签节点j对节点i的重要程度;
ω为权值参数向量,W为权重参数矩阵。LeakyReLU为非线性激活函数,αij为标签j相对于标签i的归一化注意系数。k∈Ni表示节点i的所有一阶邻域节点,j∈Ni表示节点i的某一个一阶邻域节点,其中k、j均包含自身节点i,σ为非线性激活函数。
为了更全面地提取标签信息,本文将两层图注意力网络获取的标签信息表示进行拼接,得到标签特征Gi:
其中,t表示GAT的层数,“||”为拼接符号,αtij为第t次GAT运算中标签j相对于标签i的归一化注意力系数,Wt为第t次GAT运算中权重矩阵参数。
2.6 标签文本交互层
交互注意力机制(interactive attention mechanism,IAM)通过对两个句子关联的相似特征进行提取,从而捕捉到对应句子内部重要的语义信息。因此,为了进一步加强标签之间的语义联系,本文将紧密连接的全局标签信息表示与文本上下文语义信息表示做交互注意力计算,获取基于文本语义联系的全局标签特征表示。
如图4所示,首先将标签矩阵G与BiLSTM输出H进行点乘运算得到信息交互矩阵M,M中的每个值表示标签与文本信息的相关性;
接着利用soft max激活函数分别对M的行与列作归一化处理,获取文本对标签和标签对文本的注意力分数αij和βij,计算过程如式(22)~(24)所示:
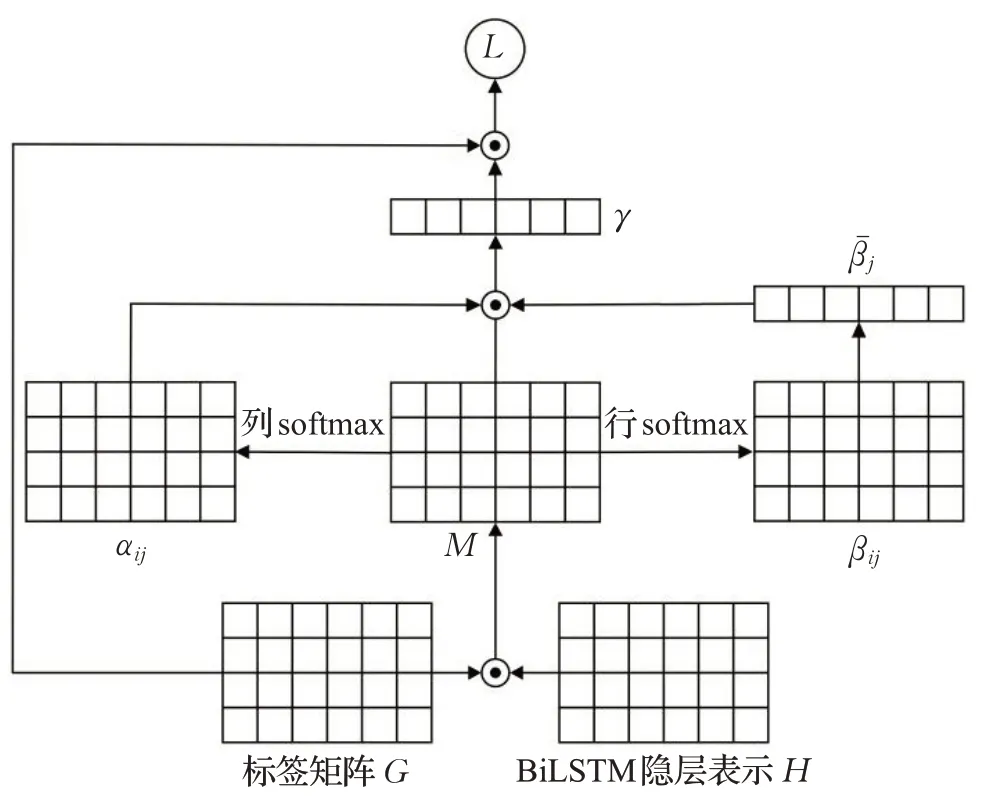
图4 交互注意力机制模型Fig.4 Interactive attention mechanism model
式中,⊙为点乘运算,Mij表示文本上下文中第i个词对第j个标签的相关性,αij表示上下文中第i个词对第j个标签的注意力权重,βij表示第i标签对上下文中第j个词的注意力权重。
然后对βij的列取平均得到文本级注意力,接着取标签注意力权重向量αij与文本级注意力向量-βT的点乘结果作为交互注意力向量γ。最后将其与标签矩阵G经过点乘运算获取具有文本语义联系的全局标签向量表示L,计算过程如下:
2.7 自适应融合层
在获取文本特征信息表示X与基于文本语义联系的全局标签表示L后,本文采用自适应融合策略对两者进行融合操作,从而提高模型的泛化能力。具体做法如下:
首先将文本特征信息表示X与标签信息表示L分别经过sigmoid函数得到分配权重矩阵θ1与θ2:
式中,θ1、θ2分别表示文本信息、标签信息对预测标签j所构成最终文本表示的重要程度,W1、W2为待训练的参数矩阵,因此预测的标签j信息最终表示为:
2.8 模型训练
模型最后将E通过多层感知器对其进行预测:
式中,W3、W4为待训练参数矩阵,f为Re LU激活函数,通过sigmoid函数做归一化处理,将其转化为对应的标签预测概率,接着通过交叉熵损失函数计算出损失值L:
其中,m为标签种类数目,n为文档数,yij表示第i个文档中标签j的真实值,yij表示第i个文档中标签j的预测值。
3.1 实验环境与数据集
本文实验基于Pytorch深度学习框架,具体实验环境如表1。

表1 实验环境Table 1 Experimental platform
本文选用AAPD、RCV1-V2与EUR-Lex三个英文公开数据集进行模型性能评估,其中AAPD数据集从ArXiv计算机科学领域搜集的论文摘要及相应的主题;
RCV1-V2数据集由路透社有限公司提供的80多万篇人工分类的新闻报道组成;
EUR-Lex数据集是由欧盟法律文件所组成。三个数据集详细分布情况如表2所示。

表2 数据集信息Table 2 Statistics for dataset
3.2 实验参数
本文使用Glove模型对文本与标签信息进行词嵌入表示,词向量的维度均为300。使用Adam优化器对训练参数进行优化,使用Dropout来防止过拟合。具体参数设置如表3所示。

表3 实验参数设置Table 3 Setting of experimental parameters
3.3 评估指标
本文采用精度(precision at K,P@K)和归一化折损累计增益(normalized discounted cumulative gain at K,nDCG@K)作为模型评估指标。具体公式如下:
式中,l∈rankk(y)为真实标签在预测标签的前k个索引,||y||0表示真实标签向量y中相关标签的个数。
3.4 基线模型
本文选取以下五种主流且较新的基线模型作对比实验:
(1)XML-CNN[8]:利用CNN可以从不同角度对文本的词序列信息做处理的特点,设计一个动态池化层对文本特征进行多角度的提取,提高标签预测的准确性。
(2)EXAM[18]:利用交互注意力机制计算文本信息与标签信息匹配得分,将聚合的分数作为每个类别预测的概率。
(3)SGM[19]:基于不同标签之间的相关性,将MLTC任务看作序列生成问题,利用LSTM对文本所含标签类别逐一预测。
(4)AttentionXML[9]:将文本信息的初始化向量表示依次通过BiLSTM、注意力机制挖掘出标签所对应的文本内容,最后根据概率链规则预测出对应的标签类别。
(5)LSAN[11]:主要将标签信息与文本信息通过自适应融合的方式来实现对文本内容的预测。
3.5 对比实验分析
本文提出的CS-GAT模型与五个基线模型的实验结果如表4~6所示。在三个数据集上,CS-GAT模型相较于最好的LSAN模型P@K分别提升了1.02、1.18、0.94;
1.29、1.44、0.66;
2.33、1.14、1.29个百分点。nDCG@K分别提升了1.02、0.88、0.68;
1.29、2.09、1.71;
2.33、1.60、1.36个百分点,可以体现出CS-GAT模型是优越的。
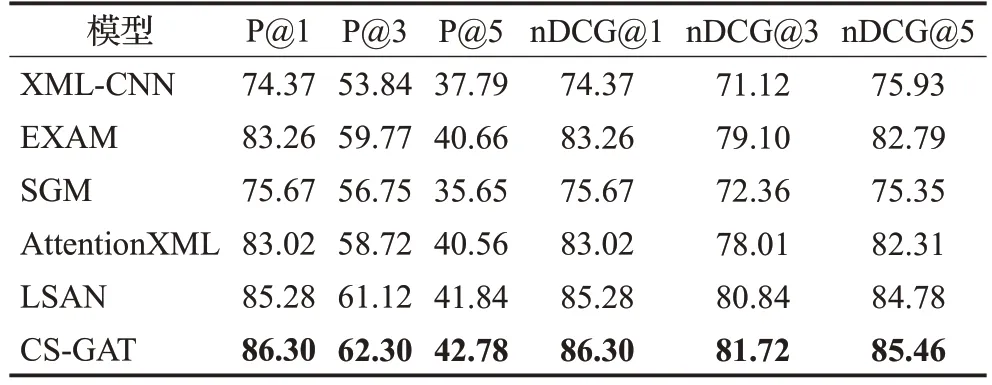
表4 在AAPD上的结果对比Table 4 Comparison of results on AAPD单位:%
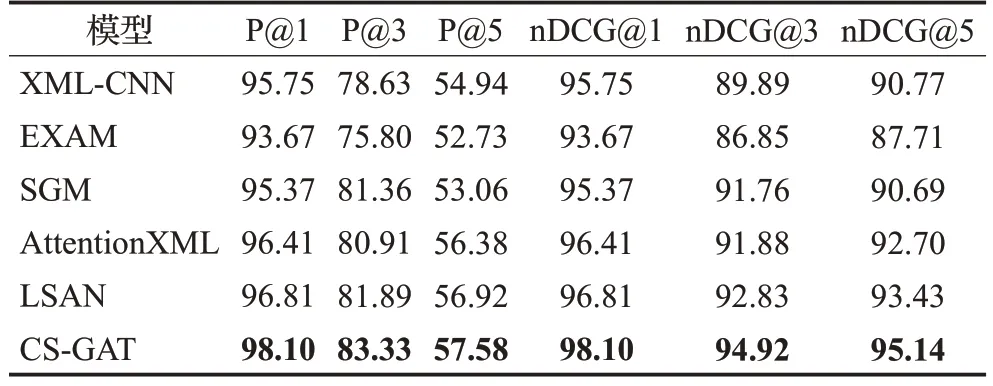
表5 在RCV1-V2上的结果对比Table 5 Comparison of results on RCV1-V2单位:%

表6 在EUR-Lex上的结果对比Table 6 Comparison of results on EUR-Lex单位:%
从总体上来看,XML-CNN、EXAM、SGM与AttentionXML四个模型相比于LSAN与CS-GAT模型较差,原因在于这四个模型均没有单独地将文本标注的标签信息考虑进去,尽管SGM与AttentionXML试图建立文本与标签之间的联系,但仅仅局限于对文本内容的训练与学习,就会降低尾部标签的预测能力。除此之外,这四个基线模型,XML-CNN在AAPD与EUR-Lex数据集上性能最差,原因是其只考虑文本局部语义信息,其他模型均通过注意力机制从全局的角度考虑了不同文本内容对标签的影响,突出了关键语句或词的特征表示,所以模型的学习能力会更好一点。相反,在RCV1-V2数据集上,虽然各模型的分类效果都显著提升,但XMLCNN却优于EXAM与SGM模型,主要因为EXAM与SGM更侧重捕获文本与标签的关联性,然而RCV1-V2数据集总词数少、类别较为明确,在挖掘文本深层次语义信息与标签的关联程度的过程中容易造成过拟合,导致在测试集上降低了文本的预测精度。因此对于更侧重于文本语义挖掘的XML-CNN与AttentionXML在RCV1-V2数据集上学习效率更高。
纵观对比实验结果,XML-CNN、EXAM、SGM与AttentionXML四个模型在数据集上的表现有好有差。LSAN相比于其他基线模型在三个数据集上均取得了更好的结果,这是因为LSAN通过自适应融合策略自动调整融合文本与标签信息的权重比例θ,提高了模型在各个数据集上的适应能力,同样本文的CS-GAT模型也考虑到了这一点。而本文的CS-GAT模型相比于LSAN有进一步的提升,是因为一方面通过CNN与SAM对文本局部与全局特征信息进行提取、融合,增强了模型的特征表达能力;
另一方面标签之间的联系不再局限于特定文本的语义联系,通过多层GAT充分挖掘全局标签之间的联系以及关联程度。从整体上看,信息的融合与标签的关联有着更为紧密的联系,因为有效地提取文本特征信息的同时也能学习标签之间存在的紧密连接关系,所以CS-GAT是优越的。
3.6 模型分析实验
3.6.1 CS-GAT模型的有效性验证
为了对CS-GAT模型的整体效果研究,本文从局部与全局信息、标签图注意力两个模块进行有效性验证。本文构建C-Label、S-Label、CS-Label、CS-Label+CNN与CS-GAT模型,其中C-Label表示仅融合局部信息,S-Label表示仅融合全局信息,CS-Label表示同时融合局部与全局信息,CS-Label+CNN表示在CS-Label的基础上将初始化后的标签信息通过CNN获取连续标签之间的局部联系,CS-GAT则表示在CS-Label的基础上通过GAT捕捉全局标签之间的图结构信息。以AAPD数据集为例,将以上模型进行对比,实验结果如表7所示。
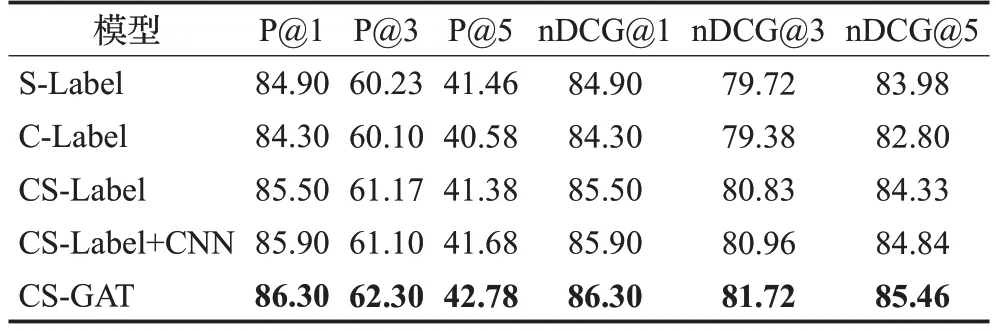
表7 CS-GAT模型有效性实验Table 7 CS-GAT model validity experiment单位:%
由表7可知,融合局部与全局信息、引入标签图注意力两种方式均可使得模型效果有所改善,而将两者相结合的效果取得了进一步提升,说明本文的CS-GAT模型在整体上是更有效的。因为标签是文本的表现形式,文本是标签的具体内容,两者相互依存有着紧密联系,所以同时优化文本与标签更有利于文本特征的划分。
分模块来看,相比于CS-Label而言,仅提取局部信息P@K与nDCG@K分别降低1.20、1.07、0.80;
1.20、1.45、1.53个百分点,仅提取全局信息分别降低0.60、0.94、−0.08;
0.60、1.11、0.35个百分点。这表明融合局部与全局信息对模型的分类性能有一定帮助作用。融合了局部与全局信息从文本特征角度来说,CS-Label集成了CNN与SAM各自的优势,得到更为全面的特征向量表示;
从文本信息角度来说,一方面使原有维度下的信息量增强,另一方面从融合的特征向量中获得最具差异性的信息表示,提高了模型的分类效果。除此之外,SLabel较C-Label模型P@K与nDCG@K分别提升了0.60、0.13、0.88;
0.60、0.34、1.18个百分点。因为CNN只关注于文本的局部信息,而SAM一方面可以捕获文本的全局信息,另一方面也可以学习到不同文本内容对标签的依赖程度,从而更好地划分文本的特征信息,同时也进一步验证了XML-CNN在AAPD与EUR-Lex数据集上的分类效果次于其他对比模型。
对于引入标签图注意力,与CS-GAT相比,CS-Label模型P@K与nDCG@K分别降低0.80、1.13、1.40;
0.80、0.89、1.13个百分点,CS-Label+CNN模型降低了0.40、1.20、1.10;
0.40、0.76、0.62个百分点。这表明GAT模块通过注意力机制对图结构数据中每个标签节点与其一阶邻域标签节点做聚合操作,促进了全局标签之间的紧密连接关系,更好地学习出标签特征信息表示,从而提高模型的整体性能。通过以上实验,验证了本文所提模型的优越性与有效性。
3.6.2 GAT层数设置实验
为了进一步验证GAT的层数对CS-GAT模型的影响,本文依旧以AAPD数据集为例在两个评估指标上进行对比,实验结果如图5、图6所示。
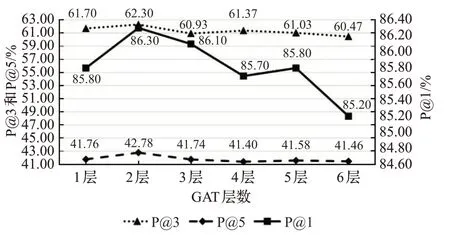
图5 不同GAT层数的P@K值Fig.5 P@K of different layers of GAT
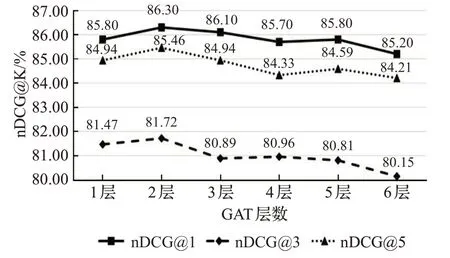
图6 不同GAT层数的nDCG@K值Fig.6 nDCG@K of different layers of GAT
为了防止GAT的层数过大导致实验结果出现过拟合,实验中取GAT层数范围为{1,2,3,4,5,6},图中横坐标代表GAT的层数,纵坐标分别为P@K与nDCG@K。从图5与图6中可以清晰看出,当GAT层数设置为2的时候,P@K与nDCG@K的值均达到最高,验证了本文GAT层数设置为2的合理性。当层数为3、4、5与6时,模型性能评估指标值虽有起伏,但总体呈下降趋势,主要因为随着训练参数增加,负载过大导致CS-GAT模型变得难以训练,所以GAT的层数设置为2为最佳。
为了解决文本特征信息丢失与全局标签之间的依赖关系,本文提出了CS-GAT模型来解决多标签文本分类任务:通过CNN与SAM分别提取文本局部与全局特征信息并进行融合,得到更为全面的特征向量表示;
同时将不同文本标签之间的关联性转变为具有全局信息的边加权图,然后利用多层GAT充分挖掘不同标签之间的关联程度,接着将其与文本上下文语义信息进行交互,获取具有文本语义联系的全局标签特征表示;
最后通过自适应融合策略进一步提取两者信息,提高模型的泛化能力。通过在三个数据集上的对比实验,验证了CS-GAT模型的优越性,同时也验证了融合局部与全局信息、引入标签图注意力的有效性与合理性。
虽然本文提出的模型在三个数据集上均取得不错效果,但是在EUR-Lex这样包含大量标签数据集上的分类效果还有待进一步提升,下一阶段将针对大量标签之间的紧密连接关系,挖掘其更深层次的语义联系;
同时进一步调整模型参数,降低模型计算的复杂度,提高训练速度。
猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
