首页 > 心得体会 > 学习材料 / 正文
一种基于机器学习的专利可转让性评估方法研究*
2023-05-10 11:05:11 ℃李 欣 冯 野 马晓迪
(北京工业大学经济与管理学院 北京 100124)
专利作为科学技术信息的重要载体,反映了国家或企业的研发投入能力与技术创新水平。通过专利交易实现专利成果转移转化成为我国促进科技创新和产学研高效协同的重要方式之一。然而,在专利申请量急剧增长的背景下,由于专利信息传播不畅、缺乏资金投入和专利产品带来效益难以预期等原因,我国的专利转移转化率却偏低[1]。因此,筛选出适合交易的高价值专利有助于政府早期识别具有转让潜力的高价值专利,有助于企业购买具有市场收益潜力的专利来提升自身竞争力,有利于促进我国专利成果转移转化率的提升。Ko 等首次提出专利可转让性的概念,即通过交易实现专利价值潜力的可能性[2]。而构建专利可转让性评估方法,从大规模的专利数据中筛选出具有转让可能性的专利,将有助于推进专利成果转化,提高专利转化率。而如何构建专利可转让性评估方法成为学术界研究的热点之一。
专利的可转让性与专利价值存在一定的区别与联系。首先,专利可转让性是指通过交易实现专利价值潜力的可能性[2]。有学者利用专利是否发生过转让衡量其可转让性。专利价值是专利在经营过程中给企业带来的经济收益和专利对企业发展战略的贡献在现实市场条件下的表现[3]。许多学者使用专利价值相关指标作为代理或通过指标加权计算得分来衡量专利价值。其次,专利可转让性评估是评估专利是否会发生转让的可能性。具有高价值的专利其转让的可能性更高,但也有部分高价值专利不会发生转让[4]。即转让的专利是有价值的,但一些高价值的专利也未必转让。
关于专利可转让性评估的研究,目前学者主要是通过构建专利可转让性评价指标体系,并利用机器学习方法进行专利可转让性评估。Ko等人从专利自身特征的内部指标与专利技术所属领域特征的外部指标两个维度,构建由23个指标组成的专利可转让性评价体系,然后构建深度神经网络模型评估专利的可转让性,并通过调节模型阈值划分专利可转让性等级[2]。武玉英等人构建基于技术与法律维度的内部指标和基于专利权人的外部指标,并使用结合高阶神经元的深度神经网络方法进行专利可转让性评价[5]。然而,这些学者虽然从不同维度构建专利可转让性的评价指标体系,并利用机器学习模型进行专利可转让性评估,但评价指标之间可能存在冗余,会增大机器学习模型过拟合的风险,降低机器学习模型的泛化能力,影响评价结果的有效性。
关于去除冗余评价指标研究方面,有些学者利用指标约减方法来减少冗余指标。在指标约减的研究中,Trappey等人利用主成分分析从专利价值评价指标体系中提取相互独立的主成分[6],但该方法存在提取主成分可解释性模糊以及存在使用不同数据提取主成分会导致结果不一致的问题。慎金花等人利用粗糙集方法约减专利价值评价的冗余指标[1],而粗糙集约减算法没有直接把机器学习模型性能作为评价标准。邱一卉提出基于CART(Classification and regression tree)的包裹式指标约减算法保留评估专利价值重要指标[7],但原算法存在部分保留指标不会带来评估模型准确率提升的问题。
综上所述,本文将提出一种改进的基于机器学习的专利可转让性评估方法。该方法将机器学习方法引入指标约减算法中,构建基于机器学习的专利可转让性评估指标约减算法,去除专利可转让性评估的冗余指标,获取专利可转让性评估的重要指标体系,以提升基于机器学习的专利可转让性评估模型的准确率,并以人工智能领域专利为例进行实证研究,验证该方法的可行性和有效性。
本文提出了一种基于机器学习的专利可转让性评估方法,如图1所示。具体思路是:首先,从Derwent Innovation(以下简称 DI)专利数据库获取专利数据,并提取专利指标,从技术维度、法律维度、经济维度和主体维度构建适用于基于机器学习的专利可转让性评价指标体系。其次,利用基于机器学习的指标约减算法对构建的专利可转让性评价指标进行约减,去除专利可转让性评价的冗余指标。之后,通过非参数检验方法对比转让专利与未转让专利在各保留指标间的差异,解释和验证约减后的评价指标体系的合理性。然后,利用约减后的评价指标数据训练与测试机器学习模型。最后,利用分类评价指标对机器学习模型的性能进行评价,最终得到专利可转让性评估的最优模型。
具体研究步骤如下:
1.1 数据检索与获取
本文以DI专利数据库为数据源收集数据,使用与研究主题相关的检索策略来下载相关专利数据,并对其进行数据清洗。然后在数据清洗后的专利数据中提取专利指标。
1.2 专利可转让性评价指标体系构建与约减
1.2.1专利可转让性评价指标体系构建
由于具有价值的专利才会发生转让,所以本文在学者们以前关于专利价值与专利可转让性影响因素研究的基础上,构建专利可转让性评估指标体系,并遵循以下原则:①为了全面评估专利可转让性,指标体系应包括专利可转让性的技术、法律、经济和主体四大维度;
②指标应在专利授权后即可获得,以便对专利可转让性进行早期评价与识别;
③应选取可量化、易获取的评价指标,以便使用机器学习模型去评估专利可转让性。因此,本文选取包含技术、法律、经济和主体四大维度的17个指标,以对专利可转让性进行全面和准确评价。

图1 基于机器学习的专利可转让性评估研究框架
a.专利技术维度反映专利自身的技术水平。技术维度指标选取如下:
科学关联度。科学关联度是指专利引用科技文献的数量,反映了专利技术与科学研究的联系程度[1,8]。在科技导向领域,科学关联度与专利价值呈现显著相关关系[9]。
引证专利数。引证专利数是指专利引用其他专利的数量,体现技术之间的知识积累性与连续性[1]。引证专利数量越多代表专利越具有坚实的技术基础,从而说明其价值也越高[8]。
IPC数量。IPC数量使用4位IPC数量进行表示,体现了专利的技术覆盖范围[10]。IPC 分类数量越多说明该专利可应用到更多技术领域发挥其价值[8,10]。
新颖性。新颖性反映了技术的创新程度,新颖性的计算公式(1)如下:

(1)
其中NCp是专利p自身在其申请年之前从未出现的8位IPC组合数,Cp是自身8位IPC的组合数目;
指标得分越高,专利创新程度越高[11]。
发明人数量。发明人数量反映了专利的研发复杂度。研发复杂度越高,专利的技术价值也越高[10]。
专利权人数量。专利权人数量反映专利研发资源投入程度及技术实用性[12]。专利权人数越多,专利质量越高[13],其专利价值也越高。
b.专利法律维度反映专利的法律保护程度。法律维度指标选取如下:
权利要求数。权利要求数反映专利的保护范围,越有价值的专利要求保护的权项数越多、范围越广[8]。
独立权利要求数。独立权利要求数反映了专利解决技术难题的技术创新性和实用性[14]。技术创新性和实用性越高,专利价值越高。
从属权利要求数。从属权利要求保护的发明与独立权利要求保护的发明相同,但反映更加具体[15]。从属权利要求和独立权利要求共同组成专利的权利要求,其数量反映专利的价值。
优先权数量。优先权数量反映了专利在多国组合和布局情况,一项专利获取多国授权将带来更大的维持成本[16],所以具有价值的专利才值得专利权人申请优先权。
审查时长。审查时长为专利授权年份与专利申请年份的差值。申请时程越长,表明技术先进性越强[17],其价值越高。
c.经济维度反映专利的市场潜力。经济维度指标选取如下:
专利家族数。专利家族数指一项专利所处的一组优先权完全相同的专利家族中专利的个数[18]。专利家族规模越大说明形成专利保护网络越牢固,技术组合布局越完善,专利家族的价值越高[19]。
同族国家数。同族国家数量是同族专利申请国的数量,反映了专利的国际竞争力。具有高价值的专利才值得专利权人在多国申请保护[8]。
d.主体维度反映专利的主体的技术实力和转让倾向。主体维度指标选取如下:
专利权人类型。不同类型的机构对实施专利转让的倾向存在差异,科研院所多承担技术研发阶段的工作,而企业注重技术的市场运营[20]。本文将专利权人类型为机构合作、研究机构、企业、大学、个人,并进行数字化分别记为5,4,3,2,1。其中,机构合作指专利权人由研究机构、企业和大学中的两个及以上所组成的情况。
专利权人专利数。所有专利权人在该领域发布的专利数量总和,反映专利权人开发专利的努力程度[21]。专利权人在该领域发布专利越多,说明其在该领域技术实力越强,专利价值可能越高。
第一发明人专利数。即第一发明人在该领域的专利数量,反映第一发明人在该领域的发明能力[22]。发明能力越强,其专利价值可能越高。
发明人专利数。即所有发明人在该领域的专利数量总和,反映所有发明人的综合发明能力。
1.2.2指标约减
在获取专利可转让性评价指标体系后,为了减少冗余评价指标,本文将对获取的评价指标进行指标约减。本文将对基于CART的指标选择方法进行改进[7],提出一种基于机器学习模型预测准确率的指标选择方法。
首先,设计计算不同指标组合下基于机器学习的评估模型预测准确率的计算模块。建立一个10层的循环,然后在每个循环中设置5折交叉验证来划分数据集。每次交叉验证都会根据相应的循环设置随机数,保证每次数据集划分结果不一样。
在每次交叉验证中,原始数据被划分为训练集与验证集。我们使用SMOTE(Synthetic minority oversampling technique)过采样算法平衡训练集数据。利用平衡后的训练集去训练机器学习模型,再利用验证集去评估机器学习模型,这样就得到某一次数据下模型对于验证集预测的准确率均值及其方差。
其次,选择合适的机器学习模型作为指标约减算法中进行专利可转让性预测的模型。选取不同的机器学习模型,并利用所有指标下的数据训练模型,得到不同机器学习模型的预测准确率均值及其方差。根据预测准确率均值及其方差选取最优机器学习模型。
然后,计算指标的影响系数。定义“影响系数数值”如式(2)所示,
(2)

利用迭代的方式,采取从指标集中有放回地去除指标的方法逐一计算每个指标的影响系数。根据影响系数值对指标进行升序排序,排名靠前的对模型预测准确率影响较大。
上述过程得到各指标按照重要程度排序列表。然后我们建立保留指标列表,采取递归的方式每次从重要程度列表取出一个指标添加到保留指标列表,然后计算相应保留指标列表下的模型预测准确率均值,当模型预测准确率均值得到提升时,确认将此指标添加到保留指标列表,并将其从重要程度列表移除。否则,继续尝试添加重要程度列表中下一个指标。在每次确认向保留指标列表添加指标时,下一次尝试添加重要程度列表中指标时都是从头开始尝试。当尝试添加到重要程度列表中最后一个指标到保留指标列表也没有给模型带来提升时算法结束。或者指标重要程度列表为空时,即所有的指标都被添加到保留指标列表,算法停止。最后我们就得到了保留指标列表。
相比于原指标约减算法,本算法的改进体现在两个方面。一是,在计算模型准确率均值方面:使用所选数据下性能最优的机器学习模型来计算预测准确率。同时加入过采样来平衡数据。二是,在确定保留指标的算法方面:采取添加指标使得模型预测准确率均值提升,才将此指标保留的方式。避免了原算法可能出现的添加某指标使得准确率提升,是由于添加的前一个指标使得模型的准确率下降的情况,导致我们保留了冗余指标。
1.3 指标约减结果解释
本文利用非参数检验U检验去检验转让专利与未转让专利在某一个评价指标下分布是否存在差异。被检验存在差异说明有充分理由认为二者来自不同的分布,进而认为机器学习模型可以通过这个指标对转让专利与未转让专利进行划分。并对转让专利与未转让专利指标分布进行可视化对比,查看两个分布在统计量上的特点,进一步从分布统计量角度解释两个分布存在哪些差异。最后根据转让专利与未转让专利指标差异性检验的结果,解释指标约减的结果。
以往研究使用预测模型准确率的提升来证明保留指标的合理性。本研究在此基础上,通过检验指标在转让专利与未转让专利之间分布上的差异,进一步验证了保留指标的合理性。同时,通过指标分布可视化比查看具体差异特点,增强了指标约减结果的可解释性。
1.4 评估模型构建
为提高专利可转让性评估的效率,本文选择机器学习中应用较为广泛的全连接神经网络、XGBoost(eXtreme Gradient Boosting)和SVM(Support Vector Machine),并进行性能对比,选择性能最优的模型作为专利可转让性评价的评估模型。
全连接神经网络由输入层、隐藏层和输出层组成。每层神经元之间设置权重与偏置,并通过反向传播算法对其进行更新。同时每个神经元设置激活函数,这种结构使得全连接神经网络具有良好的非线性拟合能力[23]。
XGBoost是通常以树模型为基模型的加法模型。其核心思想是不断添加树模型,并且不断通过特征分裂来生成一棵树。通过对得到k颗树进行集成,得到具有良好性能的预测模型[24]。
SVM的基本思路是寻找一个最优分类超平面,使两类间相邻最近样本点间的边缘最大化。SVM可以通过核函数进行非线性分类[23]。
通过对比3个机器学习模型在数据集上的性能表现,选择出评估专利可转让性的最优模型。基于机器学习的专利可转让评估模型构建过程如下:
首先,构建机器学习模型所需数据集。将约减后的评价指标数据作为机器学习模型的输入,并从预处理后的专利数据中提取专利转让信息来评估专利可转让性。将专利至少存在一次机构间转让视为转让专利[20],将其标签设置为1;
其余专利标签设置为0。0和1作为机器学习模型对应的输出。
其次,并按照时间先后顺序,将数据划分为训练集与测试集。其中训练集用于训练模型,测试集用于评估模型的泛化能力。
然后,使用训练集训练全连接神经网络、XGBoost和SVM模型,并利用测试集评估3种机器学习模型的性能。
最后,对比3种机器学习模型在准确度、精确度、召回率与F1分数这四个评估指标上的表现,选择泛化能力最优的模型作为评估专利可转让性的最优模型。
2.1 数据检索与获取
本文以检索式TAB=(“AI” OR “artificial intelligence*” OR “computer vision*” OR “machine learning*” OR “deep learning*” OR “reinforcement learning*” OR “NLP” OR “natural language processing*” OR “smart robot*” OR “intelligent robot*” OR “speech recognition*” OR “voice recognition*” OR “big data*” OR “cloud computing*”) AND PY>=(2007) AND PY<=(2017)在DI中选择USPTO专利数据库检索人工智能技术相关授权专利,共检索到15 844条专利数据,并进行数据清洗得到13 764条专利数据。提取评估专利可转让性相关指标后,得到专利指标数据集,记为数据集1。
按照年份对数据集1划分,得到2007—2016年的专利(数据集2)与2017年专利(数据集3)。然后将数据集2按照专利是否转让,划分为未转让专利(数据集4)与转让专利(数据集5)。数据获取情况如表1所示。
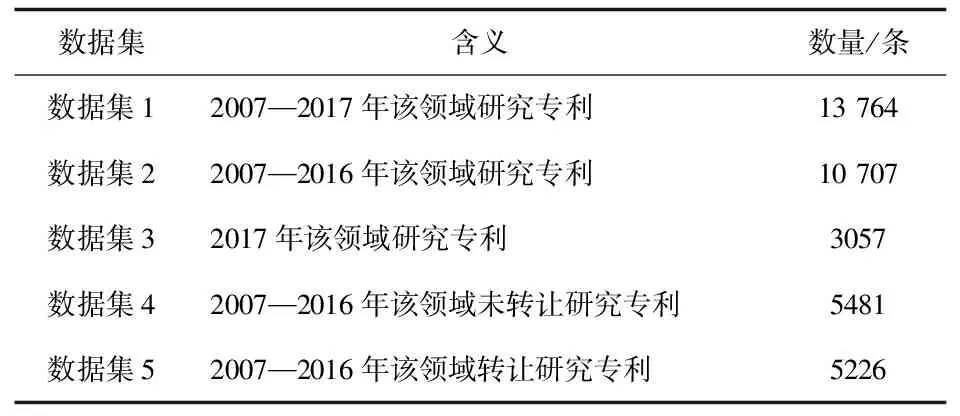
表1 数据获取情况
2.2 专利可转让性评价指标体系构建与约减
首先根据我们构建的专利可转让性评价指标体系,从专利数据集2中提取并计算相应数据构建符合机器学习模型的数据集。
然后利用基于机器学习的指标约减算法对17个指标进行约减,步骤如下。
步骤1:确定最佳机器学习模型
利用全部17个指标数据分别对全连接神经网络、XGBoost和SVM模型进行训练,通过尝试的方式得到3个机器学习模型最佳的参数。
全连接神经网络的超参数为:设置4个神经元个数为32的隐藏层,每个隐藏层的随机失活率设置为0.2。优化器为SGD,损失函数为交叉熵损失函数,迭代次数设置为200;
XGBoost模型的最佳参数为:基模型设置为gbtree,学习率设置为0.1,树的最大深度为6,n_estimators设置为100;
SVM的超参数为:惩罚系数设置为1,核函数为rbf,gamma值设置为0.2。
在交叉验证中,4个机器学习模型在验证集上的预测准确率均值与方差如表2所示。
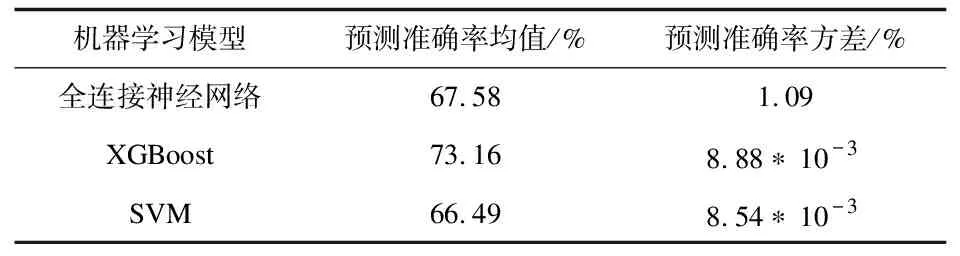
表2 验证集的预测准确率均值与方差
由表2可以看出,XGBoost的预测准确率均值最高,比排名第2的全连接神经网络高出5.58%。SVM的预测准确率方差最小。预测准确率均值代表模型的性能,方差代表预测的稳定性,综合这两个因素,选择XGBoost作为指标约减算法中的机器学习模型。
步骤2:计算影响系数
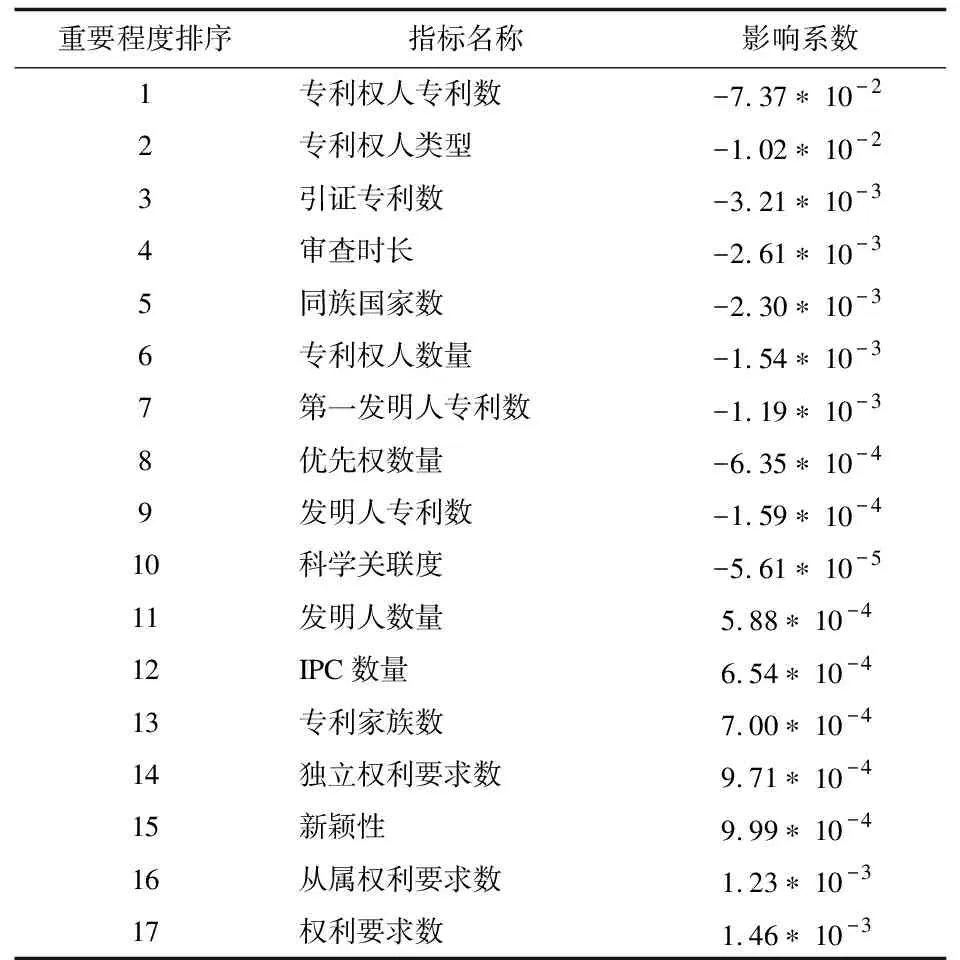
表3 指标重要程度排序
步骤3:根据指标对模型准确率的提升效果确认保留指标
通过上一步我们得到各指标按照影响系数值升序排序的指标重要程度列表。然后建立保留指标列表H,用于存放保留指标。
首先,从指标重要程度列表指标中,按照其重要程度逐个添加至保留指标列表。当指标Ci添加至保留指标列表H中,H与标签构建的XGBoost模型预测准确率均值得到提升,则确认将此指标添加到保留指标列表。然后,继续从指标重要程度列表的开始继续尝试向保留指标列表添加指标。当添加指标Ci后的H与标签L构建的XGBoost模型的预测准确率均值没有得到提升时,则继续尝试向保留指标列表H中添加指标Ci的下一个指标。直至尝试将指标重要程度列表的最后一个指标添加至保留指标列表时,也没有使模型的预测准确率均值带来提升时,算法结束。最后,我们得到了保留指标结果如表4所示,为专利权人专利数、专利权人类型、引证专利数、审查时长、同族国家数、专利权人数量、第一发明人专利数、优先权数量、发明人专利数和科学关联度。根据每次添加保留指标的预测准确率均值,绘制准确率提升曲线图如图2所示。
从表4可以看出,约减后的10个指标中4个来自主体维度,3个来自技术维度,2个来自法律维度,1个来自经济维度。在对保留指标的递归过程中,模型的预测准确率均值由67.19%上升到73.72%,相比于所有指标下预测准确率均值73.16%,提升了0.56%。通过指标约减去除掉评估专利可转让性的冗余指标,模型的预测准确率得到提升。
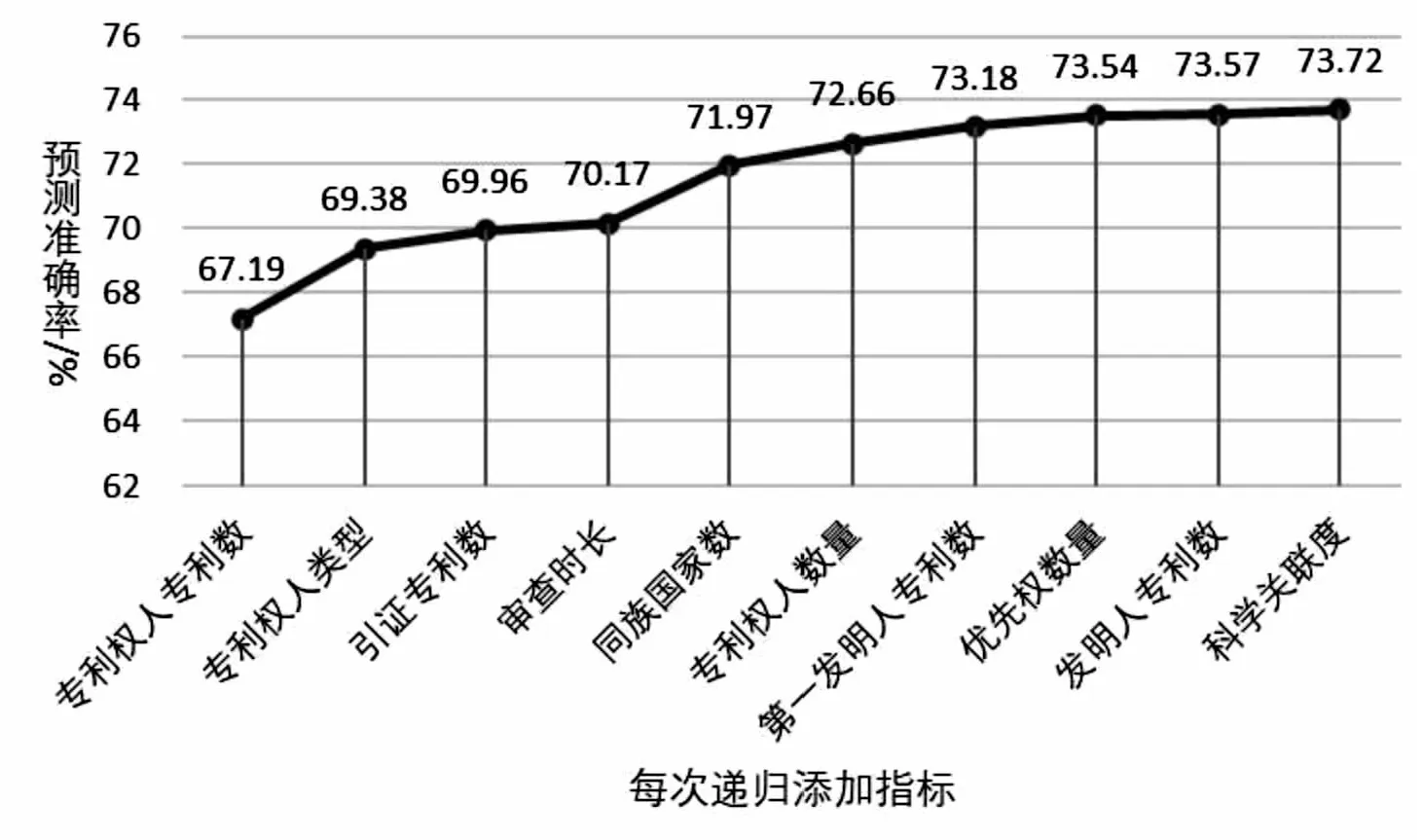
图2 根据保留指标递归添加的预测准确率提升曲线

表4 根据保留指标递归添加的预测准确率
原指标约减算法按照重要程度列表中指标顺序逐个添加指标,当添加指标后准确率大于上一次,则保留此指标。按照原算法得到的准确率提升曲线如图3所示。

图3 原算法根据保留指标递归添加的预测准确率提升曲线
从图3可以看出,按照原算法保留指标除了本文使用改进后约减算法得到的10个指标外,还包括了IPC数量和独立权利要求数。而这两个指标的保留是由于添加上一个指标使得准确率下降导致的。使用原算法得到的保留指标,计算其预测准确率均值为73.56%,低于改进后算法得到保留指标下的预测准确率均值73.72%。所以这两个指标是冗余的,进而表明改进后的指标约减算法效果更好。
2.3 指标约减结果解释
为了从指标统计分布的角度探究这些指标被保留的原因。选取保留指标在数据集4与数据集5中的数据,然后利用差异检验检验二者分布是否存在差异。
由于各约减后指标的分布不全符合正态分布,所以本文选用非参数检验U检验来检验不同指标下转让专利与未转让专利的数据分布是否存在差异。检验结果如表5所示。检验p值小于0.05时,被认为存在差异。
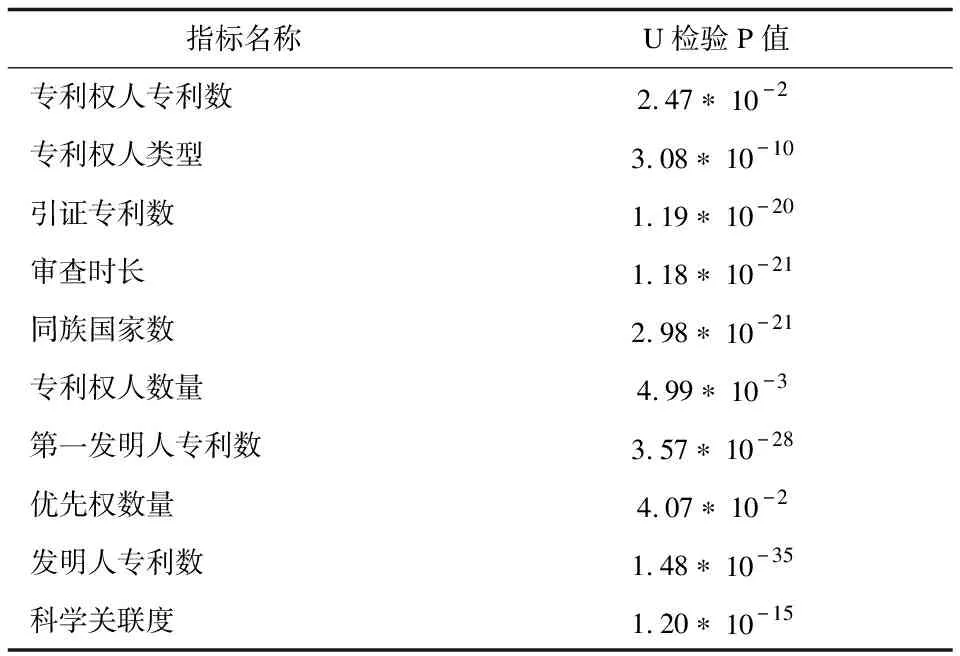
表5 指标差异性检验结果
由表5可知,保留指标均被U检验检验为存在分布差异。这些指标被检验存在差异,说明有充分理由认为这些指标数据集中转让专利数据与未转让专利数据来自不同的分布,进而表明这些指标有助于机器学习模型对转让专利与未转让专利进行划分。
为了进一步分析保留指标数据集下转让专利与未转让专利两个分布存在哪些差异,本文计算分布统计量并进行分布可视化,分析同一指标下两个分布存在哪些特点。转让专利与未转让专利在各个指标下的统计量,结果如表6所示。
为对比转让专利与未转让专利在同一指标下的分布情况,我们进行了指标分布对比分析,部分指标分布对比结果如图4和表7所示。

图4 专利权人专利数对比图
对专利权人专利数进行分布可视化后得到图4。图4中箱线图中上面为转让专利指标箱线图,下面为未转让专利指标箱线图。其中三角点代表均值,圆点为算法检测的异常点。右边相对应的为转让专利与未转让专利指标分布直方图。
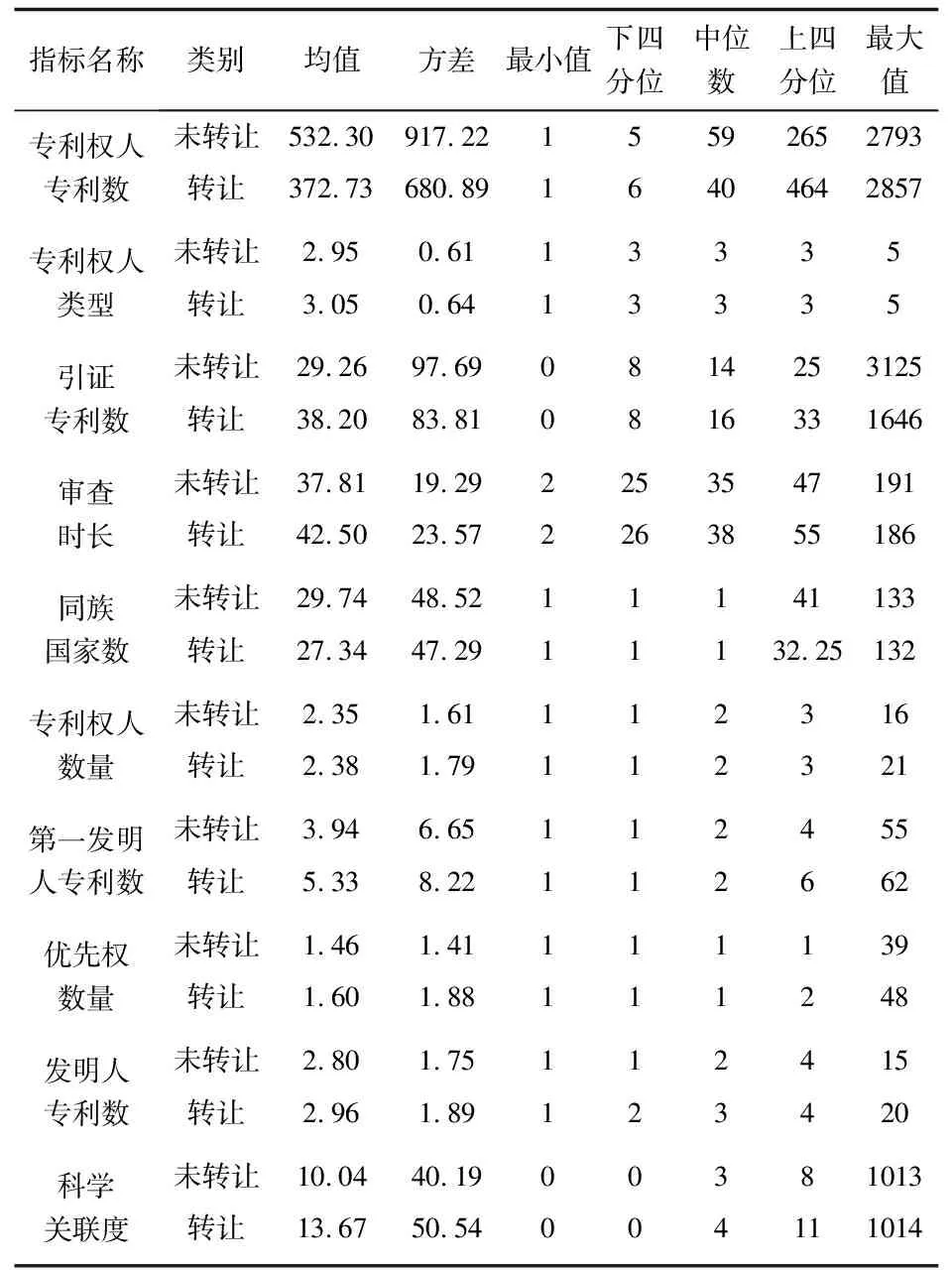
表6 转让专利与未转让专利各指标统计量对比
由图4可知,未转让专利的中位数比转让专利高19,均值高159.57。而转让专利的上四分位比未转让专利高208。
对专利权人类型中各类型专利权人的数量与占比进行统计得到表7。
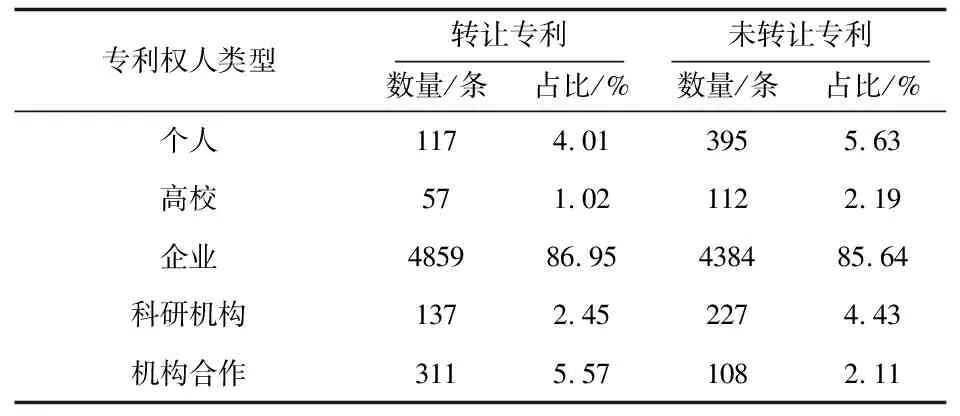
表7 专利权人类型对比
由表7可知, 转让专利与未转让专利中专利权人为企业的占比均超过85%。在转让专利中机构合作的占比高于未转让专利,所占比例超过未转让专利的2倍。转让专利中高校和科研机构的占比均低于未转让专利。
综上可知,专利权人专利数、专利权人类型、引证专利数、审查时长、同族国家数、专利权人数量、第一发明人专利数、优先权数量、发明人专利数和科学关联度在转让专利与未转让专利直接存在差异。被检测存在差异的指标说明该指标更有助于机器学习模型对转让专利与未转让专利进行分类。这些结果表明,通过指标约减算法,我们去除了评估专利可转让性的冗余指标,并从数据分布角度验证了保留指标的合理性。
已有研究表明,不同类型专利权人由于其在研发与经营策略上存在不同,使得其专利转让行为存在差异[20]。本文根据专利权人特征与发明人特征构建的专利主体维度指标反映专利主体的技术实力与转让倾向。主体维度四个指标均被保留,说明主体维度指标对于评估专利可转让性是非常重要的,这也与已有研究结果相一致。已有研究也表明,高价值专利更容易发生转让[4],评估专利转移潜力的核心因素之一是对其专利价值的识别[25]。在技术维度中,已有研究认为引证专利数与专利价值有显著正相关[26],科学关联度被认为是评估专利价值的核心指标[8],专利权人数量也多次被用于专利质量和价值的评估[27]。在法律维度中,优先权数量反映了专利组合与布局情况,研究表明实施合理的专利组合与布局策略有利于促进技术专利转化过程中的价值增值[28]。企业专利的审查时长被认为与专利价值呈现正相关关系[29]。在经济维度中,由于高价值专利才值得在不同地域申请保护[30-31],所以同族国家数量能够很好反映专利的经济价值。
综上所述,本文约减后得到的专利可转让性评估指标是有效的,这些指标是专利可转让性评估的重要指标。
2.4 评估模型构建
首先,以约减后专利可转让性评价指标体系为依据,从数据集2与数据集3中提取并计算相应指标数据,获得与约减后专利可转让性评价指标体系相对应的符合机器学习模型的专利数据来构建训练集、验证集和测试集。其中,数据集2为2007—2016年专利数据,将其按照4∶1的比例随机划分为训练集与验证集。训练集用于训练机器学习模型,验证集用于调整模型参数。数据集3为2017年专利数据,作为测试集来评估模型的泛化能力。
然后,分别构建全连接神经网络、XGBoost和SVM模型评估专利可转让性。根据验证集评估结果调整机器学习模型的参数,全连接神经网络的迭代次数变更为240,XGBoost参数保持不变,SVM的gamma值变更为0.8,3个模型的其余参数与指标约减算法中对应模型的参数保持一致。约减后指标对应数据集下各机器学习模型的性能评估结果如表8所示。
由表8可知,XGBoost模型在测试集上各评估指标的表现均优于全连接神经网络与SVM。使用约减后指标数据训练的XGBoost模型对于测试集的预测准确率为72.36%,总体预测精确度、召回率和F1分数为72.80%、72.50%和72.29%。综上,XGBoost为评估专利可转让性的最优模型,具有良好的泛化能力。

表8 约减后指标对应3种机器学习模型的性能评估结果
人工智能领域专利可转让性评估案例表明,本文构建的基于机器学习的指标约减算法能够去除掉冗余指标,使得模型预测准确率得到提升;
基于约减后的指标所构建的基于机器学习的专利可转让性评估模型也是可行和有效的,能够获得具有良好泛化能力的最优评估模型。
面对日益增加的专利数据,如何快速、准确地识别出具有可转让性的专利对于政府部门、大学、科研机构和企业的专利管理决策至关重要。针对目前专利可转让性评价研究存在的不足,本文提出了一种基于机器学习的专利可转让性评价方法,并以人工智能技术领域专利为研究对象,验证了该方法的可行性和有效性。案例研究发现:a.专利权人专利数、专利权人类型、引证专利数、审查时长、同族国家数、专利权人数量、第一发明人专利数、优先权数量、发明人专利数和科学关联度对于转让专利和非转让专利具有明显的区分度。其中,主体维度的指标均被保留,说明主体维度指标对于评估专利可转让性是非常重要的。b.基于机器学习的专利可转让性评估模型,使用约减后的评价指标,模型具有较好的泛化能力,模型分类准确率达到72.36%,可以较好地对专利的可转让性进行评估。
本文的主要贡献是提出了一种基于机器学习的专利可转让性评估方法。首先,将机器学习方法引入指标约减算法中,构建基于机器学习的专利可转让性评估指标约减算法,对专利可转让性评价指标体系进行指标约减,剔除冗余指标来提升机器学习模型的泛化能力。同时利用非参数检验方法来解释指标约减结果的合理性,进而得到一套专利可转让性评估指标体系。其次,虽然本文是以人工智能领域2007-2017年的历史专利数据,验证了基于机器学习的专利可转让性评估模型的可行性和有效性,但该模型的输入指标一经专利授权即可获取,因此当新专利(2022年授权的专利)数据输入模型时,模型可对输入专利的可转让性进行评估。因此,该模型不仅为人工智能领域专利可转让性评估提供了可行和有效的方法,也为其它领域的专利可转让性评估提供方法支持。此外,本文所提出的机器学习模型框架是开放的,可以利用不同的机器学习算法来对某领域历史的转让专利和未转让专利进行分析,并获取专利特征与专利转让之间的关系模式。当该领域新的授权专利一经公开,就可以获取专利的特征数据,并可以利用机器学习模型来对其转让的可能性进行评估,从而为早期识别专利可转让性提供了可能。因此,基于机器学习的专利可转让性评估方法为专利可转让性评估提供了新的研究方法。
猜你喜欢专利权人机器准确率基于动态博弈的企业专利诉讼研究:动机与诉讼收益商展经济(2023年3期)2023-02-20机器狗环球时报(2022-07-13)2022-07-13机器狗环球时报(2022-03-14)2022-03-14乳腺超声检查诊断乳腺肿瘤的特异度及准确率分析健康之家(2021年19期)2021-05-23不同序列磁共振成像诊断脊柱损伤的临床准确率比较探讨医学食疗与健康(2021年27期)2021-05-132015—2017 年宁夏各天气预报参考产品质量检验分析农业科技与信息(2021年2期)2021-03-27未来机器城电影(2018年8期)2018-09-21高速公路车牌识别标识站准确率验证法中国交通信息化(2018年5期)2018-08-21对标准必要专利权人拒绝许可行为的反垄断规制知识产权(2016年7期)2016-12-01以美国及台湾地区的知识产权管理经验解读专利纠纷谈判策略(上)华东科技(2013年4期)2013-03-26猜你喜欢
- 2024-01-20 有关于第五次全国经济普查统计重点业务综合培训大会上讲话(完整文档)
- 2024-01-20 “严纪律、转作风、保安全、树形象”专题学习教育活动通知(完整文档)
- 2024-01-20 2024XX区住房城乡建设工作情况汇报
- 2024-01-20 2024高校思政教育交流材料:善用反腐败斗争这堂“大思政课”(精选文档)
- 2024-01-20 2024年主题教育专题党课辅导报告,(4)
- 2024-01-20 关于赴某地学习考察地方立法工作情况报告(范文推荐)
- 2024-01-20 2024年度关于增强党建带团建工作实效对策与建议(精选文档)
- 2024-01-20 教师演讲稿:春风化雨育桃李,,潜心耕耘满芬芳(全文)
- 2024-01-20 主题教育第二阶段来了
- 2024-01-20 2024年度关于到信访局实践锻炼个人总结【完整版】
- 搜索
-
- 打赌输了任人处理作文1000字7篇 05-12
- 当代大学生在全面建设社会主义现代化强 05-12
- 全面建成社会主义现代化强国的战略安排 03-10
- 个人廉洁自律方面存在的问题及整改措施 05-12
- 谈谈青年大学生在中国式现代化征程上的 05-12
- 2022年党支部第一议题会议记录(全文完 11-02
- 作为青年大学生如何肩负时代责任6篇 05-12
- 村党组织建设现状及工作亮点存在问题与 05-12
- 全面从严治党,自我革命重要论述研讨会 05-12
- 产业工人队伍建设改革(全文完整) 10-31
- 11-25国庆70周年庆典晚会 庆典晚会串词
- 11-25办公室礼仪的十大原则 浅谈办公室的电话礼仪
- 01-17用心灵轻轻地歌唱_心灵的歌唱
- 01-17也许你不是我一生的唯一|也许不是我
- 01-17爱了,请珍惜;不爱,趁早放手|爱就珍惜不爱就放手
- 01-17岁月带走的是记忆,但回忆会越来越清晰|有趣又有深意的句子
- 01-17曾经的美好只是曾经,我只想珍惜身边的人|我只想珍惜你
- 01-18从容不惊 [学会笑眼去看世界,不惊不乍,淡定从容]
- 02-03当代大学生学习态度调查报告
- 02-03常用护患英语会话
- 标签列表
